
Data is now collected everywhere and can be accessed anywhere. Whether you are deciding which product to buy, which potential customer to visit, or which restaurant to frequent, many situations in our everyday personal and professional lives benefit from access to relevant, accurate, and actionable data. Such access supports awareness, promotes understanding, and helps us make the right decisions in today’s complex information society. This access to anywhere data is made possible by an increasing amount of everywhere data collected from virtually all aspects of our physical and digital world:22 shopping lists and purchase histories; movie, music, and book preferences; electronic health records and medical test results; colleagues, friends, and family; professional experience and education; and more. While significant privacy, security, and safety concerns are intrinsic to this confluence of anywhere and everywhere data, there is also an unprecedented opportunity to use this data to support individuals navigating the complexities of their professional and personal lives. Fortunately, the last 20 years of the mobile revolution have given us the means to achieve this. Mobile is now the dominant computing platform on the planet, with more than 15 billion mobile devices in 2020a and more than six billion of them being “smart” and able to access the Internet.b However, these devices—for all their mobility—are currently mere portholes into the digital world, are rarely designed to work together effectively to support a single user let alone multiple ones, and lack the powerful analytical tools needed to enable data-driven decision-making on the go.

Key Insights
Data is collected everywhere on our increasingly connected and information-rich globe.
Mobile and IoT devices are becoming the world’s universal computing platforms.
Immersive and mobile technologies are poised to help people leverage all this data for analytics conducted anytime and anywhere.
This emerging genre of ubiquitous analytics is leveraging mobile devices, slim form-factor XR goggles, and cloud computing to enable people to make sense of data wherever they are, from the office, the factory floor, or even their own living rooms.
Fortunately, this may be about to change, with mobile and ubiquitous computing46 as well as extended reality (XR)43 finally beginning to transform the fields of visualization and data science. Applying these technologies to data analysis suggests a future of ubiquitous19 and immersive analytics,31 where clusters of networked mobile devices form an ecosystem for data analytics that can be accessed anytime and anywhere. Such a vision of mobile, immersive, and ubiquitous sensemaking environments would blend state-of-the-art analytics methods with our physical reality to enable making sense of any kind of data in virtually any situation (see Figure 1). However, we should not be weaving computation into our everyday lives just because we can. Rather, progress in cognitive science11,30,41 supports leveraging the new generation of mobile, immersive, and ubiquitous technologies toward data analytics. These so-called post-cognitive frameworks suggest that human thought is not contained merely within our heads but encompasses the entire ecosystem37 of other people, physical artifacts in our surroundings, and our very own bodies. Distributing computational nodes into our physical surroundings will thus enable us to better scaffold analytical reasoning, creativity, and decision making.
In this article, we investigate how the prevalence of collected everywhere data can enable it to be leveraged for anywhere and anytime access. To achieve this, we first explore the concepts of anywhere and everywhere data and see how current technologies can (and cannot) support cognition in these ubiquitous computing environments. We also review current research in ubiquitous and immersive analytics that builds toward this vision. Finally, we synthesize the current research challenges facing the scientific community and describe the outlook for future research on the topic.
Anywhere and Everywhere Data
Envisioned by Mark Weiser and Xerox PARC in the late 1980s,46 the “third wave” of computing—ubiquitous computing—is essentially here, even if it looks subtly different from their original vision.17 Instead of talking alarm clocks, we have voice-driven home assistants; instead of cheap and disposable computational “tabs,” we have smartphones that we bring everywhere we go; instead of an interactive liveboard in every office, we have Zoom and Google Meet videoconferences at our beck and call. Nevertheless, with billions of mobile devices in existence—many of them smart—and a burgeoning Internet of Things (IoT) making increasing inroads into our physical reality, it is safe to say that we are rapidly approaching a world where computing has indeed been woven into everyday life. The critical difference is, unlike in the original vision of ubiquitous computing, the implementation has been more about personal devices than shared infrastructure—what Harrison et al.26 call quality rather than quantity computing.
Envisioned by Mark Weiser and Xerox PARC in the late 1980s, the “third wave” of computing—ubiquitous computing—is essentially here.
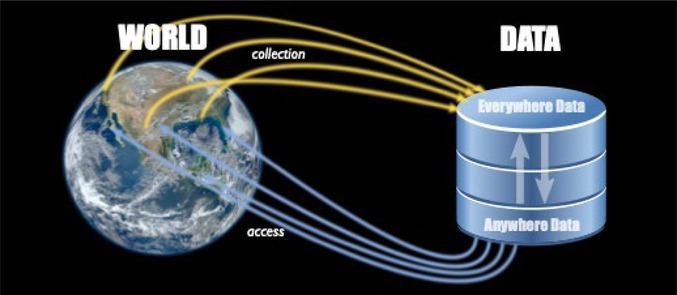
Regardless, this quiet ubiquitous and mobile computing revolution has had two very specific outcomes relevant to data analytics (Figure 2): the emergence of everywhere data and anywhere data. For the former, it has led to the collection of digital data across our entire society and in virtually all walks of life, both in the real world and online. The IoT encompasses a wide and growing array of devices, such as Webcams and security cameras, smart thermostats and light bulbs, digital weather stations, pollution and air-quality sensors, smart locks, connected home appliances, and so on. These devices are also becoming more entwined into professional settings, such as for connected healthcare devices and monitors, autonomous farming equipment, wireless inventory trackers, biometric security scanners, wireless sensor networks, and unmanned military equipment. Common for all the datasets collected by these devices is that they are local, temporal, and contextual:
Local: Connected to a specific geographic or semantic location (for example, the temperature on top of the Eiffel tower).
Temporal: Associated with a point in time or a temporal pattern (for example, the temperature on May 1).
Contextual: Related to a specific situation and thus best interpreted in that context (for example, a car engine’s temperature when traveling at 60mph).
The situation is slightly different for data collected online, as there may be no geographical location associated with the data. Furthermore, in many cases, even data collected from the real world is stored in databases where these local, temporal, and contextual aspects are discarded or aggregated. For example, the thousands of Webcams around the world that merely show video to whomever happens to tune in represent a lost opportunity. What if we instead continuously ran privacy-preserving image-analysis algorithms on this footage to capture environmental data, such as wind speed, population density, snow accumulation, beach erosion, or road traffic?
This quiet ubiquitous and mobile computing revolution has had two very specific outcomes relevant to data analytics: the emergence of everywhere data and anywhere data.
Nevertheless, it is safe to say that virtually everything we do online is tracked and recorded, a task only made easier by the fact that in the digital world, instrumentation is trivial. The second outcome from the mobile computing revolution is that technology advances have instilled in users a desire for the ability to access this data anytime and anywhere. Many people are accustomed to enjoying near-constant connectivity with the Internet and all its trappings, from social media and video streaming to email and instant messaging. The step to expecting the same anywhere data access even for analytics and sensemaking tasks is not far. However, while current devices certainly can access, manage, and store these datasets, input and output technology has only recently reached a level where such sensemaking can be conducted. But how should we go about doing so effectively?
The Cognitive Case
Advances in cognitive science summarized as so-called post-cognitive frameworks—such as embodied,41 extended,11 distributed cognition30 (see Post-Cognitive Frameworks sidebar)—suggest that human thinking is a system-level process,37 one that is not merely contained within our brains but which expands to include the world around us, the physical artifacts in our vicinity, our own bodies, and other people. In a post-cognitive framework, cognition is represented as information being transformed from one media to another through interactions, for instance, a person uses a pen to write a reminder on a Post-it note, places the note on a refrigerator, reads the reminder at a later date, and then acts upon it. In other words, tools do not amplify our mind but instead transform certain cognitive activities, such as remembering long number sequences, into other, less taxing cognitive activities—such as reading. Analogously, a visual representation of data on a digital screen is another form of media that a person can interact with to view, manipulate, and understand the underlying data—but so is the notepad the person uses to jot down notes, the phone through which they speak to a colleague, and the calculator they employ for quick arithmetic.
Effectively supporting sensemaking thus means instrumenting the entire ecosystem of artifacts involved in the cognitive process. This is in contrast to traditional human-computer interaction (HCI) and visualization paradigms, which tend to consider only the actual interface between user and machine: the visual output from the screen and the user input from the mouse, keyboard, touchscreen, or microphone. By distributing interactive representations of data on a multitude of digital devices scattered around our physical surroundings as well as with the collaborators involved in the cognitive system, we are for all intents and purposes creating a cybernetic extension of the mind, expanding it using these digital devices. This notion would have been revolutionary if not for the fact that we have already been doing this for thousands of years, since the first human picked up the first fallen branch and used it to dig a hole in the dirt. A shovel is a cybernetic extension of a person’s arms that enables them to dig better, and an excavator takes this concept of human extension even further. Similarly, a computer can be seen as a cybernetic extension of our logic, reasoning, and memory—or, as Steve Jobs famously puts it, a “bicycle for the mind.” Nevertheless, from the digging example, it is clear that the type of tool makes a big difference, and even if digging may be a solved problem, the same cannot be said of sensemaking.
Of course, the argument here is not that the more devices we weave into our everyday environment, the more effective the cognitive process. As Harrison et al.26 point out with their quality vs. quantity computing argument, human attention is a scarce commodity, and the current focus on a single, highly capable personal device seems to have won out over the “one user to many devices” Ubicomp vision from the 1990s. However, there clearly exists a middle ground between a single device per person and dozens. In addition, nothing says that the devices must be homogeneous; it may be difficult to use two tablets at the same time, but a tablet and a smartwatch can be complementary. For one thing, data analysts do not only use computers but tend to surround themselves with pen and paper, calculators, reference material, books, and other physical artifacts, not to mention other analysts.37 For another, physical space is a key factor in the data analysis process; Wright et al.48 describe how some professional intelligence analysts would use the entire floor of their office to arrange documents during analysis, and Andrews and North conducted empirical studies demonstrating the utility of significant visual space in facilitating sensemaking.1 In fact, the intelligent use of space as part of cognition is a cornerstone of post-cognitive frameworks,33 simplifying choice, facilitating perception, and aiding computation. Furthermore, proxemics—hailed by some as the new Ubicomp24—tells us how people physically relate to artifacts and other people as they interact with them; for example, we typically turn to face people we speak to. These are all prime arguments in favor of instrumenting all the components involved in the cognitive process—ranging from notepads to books and other people—using networked digital devices. Drawing from all three of the ubiquitous computing, visual computing, and visual analytics traditions, we call this approach ubiquitous analytics.19
The Gap in Our Tech
If cognitive science supports the use of these networked groups of devices to facilitate sensemaking, why have we not yet seen a plethora of such ubiquitous analytics systems on the market and in the scientific literature? The answer is that until only recently, the technology required to harness anywhere and everywhere data has been outside our reach. More specifically, the gaps in our technology include screen size, input surfaces, and the general design of the mobile devices we need for this endeavor.
Both screen size and input surfaces suffer from a device-miniaturization tradeoff, where mobile devices already maximize the input and output dimensions to encompass the full size of the device. They simply cannot be made much larger to avoid diminishing the mobility and portability of a smartwatch, tablet, or smartphone. One solution for both input and output is to go beyond the device itself to appropriate the physical world as part of the interaction.25 For example, portable projectors can turn any nearby surface into a display of arbitrary size.15 Depth cameras, ultrasound, or electrical sensing can similarly transform walls, tables, or even our very own bodies into touch surfaces. The rise of consumer-level mixed- and augmented-reality43 equipment has taken this idea even further by turning our entire world into a potential canvas for data display and manipulation. Instead of our smartphones being mere portholes into an unseen world of data, XR technology has broken down the fourth wall hemming us in.
Until only recently, the technology required to harness anywhere and everywhere data has been outside our reach.
A hurdle remains, however: Current mobile devices are still designed using the “quality computing” mindset. This means that each individual device is intended to be used in isolation and with the undivided attention of the user. A significant gap for mobile computing is to derive new design paradigms where multiple devices can stack together and scaffold each other for the current task while minimizing barriers and tedious housekeeping. We will demonstrate some examples of how to design such stacking devices in the treatment to come.
Ubiquitous, Immersive, and Situated Analytics
While command-line tools, automated scripts, and libraries are common in general data-science tasks such as computation, wrangling, and confirmatory analysis,9 the kind of exploratory data analysis common to sensemaking (see Sensemaking and Visualization sidebar) often benefits from a more fluid and visual interaction model. This is particularly true in mobile settings, where the precise text entry required for programming and command-line interfaces remains challenging on handheld devices. In such situations, it is more convenient to turn to interactive visual interfaces and automated recommendations. The scientific field of data visualization concerns itself with precisely these visual and interactive data displays. In fact, the field has recently undergone a dramatic change with the rise of ubiquitous,19 immersive,21,31 and situated analytics20 for tackling these use cases.
Three-dimensional visual representations have long been the norm in many scientific applications for visualization, such as flow visualization, medical imaging, and volumetric rendering. However, the very first applications of data visualization to immersive settings actually came from outside the visualization field. In 2003, Bowman et al.6 proposed a research agenda for so-called information-rich virtual environments (IRVEs) that combined 3D virtual reality with information visualization. Touch-enabled tabletops were an early platform, with Spindler and Dachselt44 proposing a tangible lens for interacting with data on or above a horizontal display. Finally, visualization made inroads into mobile computing in a much more unobtrusive manner, with the first applications being commercial ones on smartphones. Lee et al. review mobile data visualization in a recent book on the topic.36
Starting in 2011, I joined this research area by proposing the notion of an embodied form of human-data interaction.18 This launched my research agenda on this topic, and my students and I followed this up with an embodied lens used for exploring data on a touch-based tabletop.32 It eventually led to Pourang Irani and I defining the ubiquitous analytics19 paradigm in 2013, which serves as an umbrella term for the research field: anytime, anywhere sensemaking performed on a plethora of networked digital devices, not just immersive ones. My students and I also proposed several computing infrastructures for realizing this vision for data analytics, including Munin (a peer-to-peer middleware based on Java),4 PolyChrome (the first Web-based framework),3 and Vistrates (a mature Web replication framework for component-based visualization authoring).5 Researchers have since taken our ideas further; for example, ImAxes13 enables data analysis in virtual reality using powerful hand gestures for connecting dimensional axes in 3D. Another early example was Butscher et al.’s work combining parallel coordinates display in augmented reality on top of a tabletop display.8
Along the way, several variations of these ubiquitous forms of analytics have emerged. Immersive analytics, initially introduced by Chandler et al.10 in 2015, takes a specific focus on immersive and 3D spatial technologies to support sensemaking.31 Situated analytics,20 on the other hand, emphasizes the spatial referents for data in the real world. Willet et al.47 built on this in 2017 for embedded data representations that are deeply integrated with the spaces, objects, and contexts to which the data refers.
Given the one-to-many ratio of users to devices in traditional Ubicomp, cardinality is a common denominator also for ubiquitous analytics. In the below subsections, we discuss cardinality from three different perspectives and give specific examples for each: multiple devices, multiple resources, and multiple collaborators.
Multiple devices. The first factor worth investigating in a ubiquitous approach to analytics is how to best manage the multiple types of devices a user will engage with during sensemaking. As already mentioned, human attention is a finite resource that must be judiciously managed. Current device platforms are typically designed for focused use; for example, a smartphone engages the user’s hand, often the dominant one, so adding a second smartphone is seldom helpful. Rather, adding multiple devices to an interaction should be complementary, either by physical form factor (for instance, a smartwatch or a large display), by physical placement (for instance, handheld, wall-mounted, or head-mounted), by task (for instance, a primary display used for map navigation and secondary ones to show legends and drill-down details), or by various combinations of these. Users are rarely helped by two identical devices inhabiting the same position in this design space, except possibly for comparison tasks where holding two tablets side by side may be beneficial.

The first factor worth investigating in a ubiquitous approach to analytics is how to best manage the multiple types of devices a user will engage with during sensemaking.
We studied this phenomenon in a 2018 research paper on the interplay between smartwatches and large touch displays27 that we informally dubbed David & Goliath (D&G). The form factors of these two different computing platforms are radically different. A smartwatch is a fundamentally personal device, whereas a large display is a fundamentally public one. Smartwatches have small displays, are attached to a person’s wrist and are thus always within reach, and are only really accessible—both in terms of physical reach as well as social practices—to the wearer. Any action performed and any data displayed on a smartwatch will accordingly be personalized. In contrast, a large touch display is often vertically mounted on a wall, is visible to many by virtue of its size, and invites interaction by anyone within physical reach. This, in other words, is a prime example of how a ubiquitous analytics environment can be designed to use complementary device platforms.
Figure 3 shows an example of the David & Goliath system in action. Drawing on the personal affordances of the smartwatch, we mainly use the smaller display as a personal storage container as well as a mediator and a remote control—all tasks that are well-suited to the device. The large display, on the other hand, is a public and shared device that provides the fundamental data visualization for the team working on a specific task. Because of its size, it can show dashboards of multiple visualizations rather than just one.
Devices can also complement each other over time. In the recent ReLive29 system (Figure 4), we proposed a hybrid desktop/VR interface that gives the same user access to two different ubiquitous analytics interfaces depending on task. ReLive was built to help mixed-reality designers and researchers analyze real-time telemetry from user studies conducted in virtual- or augmented-reality environments. Thus, the primary data being visualized is 3D tracking and event logs over time. Here, again, the two analysis interfaces—an in situ 3D virtual reality interface and an ex situ 2D desktop interface—are complementary in that each suits a specific task. When it comes to understanding 3D data, such as how two participants worked together in a 3D assembly task, nothing beats viewing the data from a first-hand perspective in 3D. However, when deriving high-level abstract findings, such as the average distance between participants over an entire session, the 2D desktop interface is optimal. Having access to both interfaces allows a user to pick the right tool depending on task.
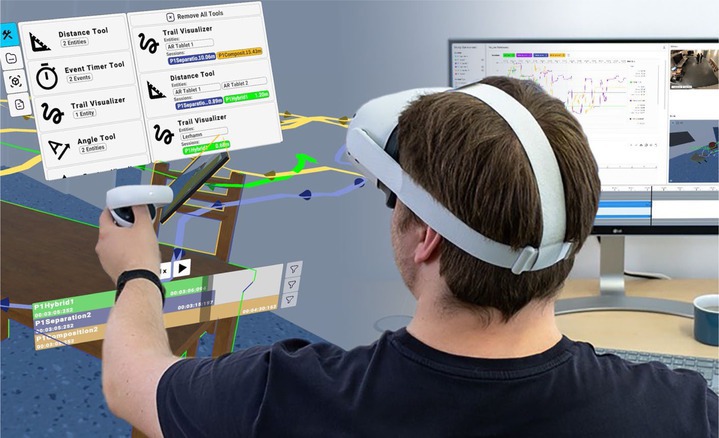
But it is not enough that two devices are complementary—they should actively support each other. This is particularly important in ReLive, where the same user will be switching between the two different interfaces time and time again, sometimes as part of the same task. This interface switch leads to a “cognitive context switch,” where users must reorient themselves within the new interface in relation to the other interface. In ReLive, this is facilitated by providing common anchors between the two views. The 2D desktop view provides a 3D in situ viewport that is always visible. Analogously, the 3D Virtual Reality view replicates many of the interface features from the desktop view, and selections made inside the first-hand perspective can be accessed in the 2D view.
Takeaway. Each device involved in ubiquitous analytics should have a clear role that complements the other devices, and transitions between them should be seamless.
Multiple resources. Given that the previous discussion is at the level of entire devices, our next concern is how to manage the resources associated with these devices, such as displays, computational power, input affordances, and so on. Resource management quickly becomes onerous and almost all-consuming when multiple devices are involved, and automation is thus required. For example, imagine logging into your typical workplace network, and then multiply this for every device you want to include in a work session. If the overhead associated with using multiple devices becomes overwhelming, people will simply stick to a single device.
One example where such automated resource management is critical is display management. In a typical ubiquitous analytics scenario, we might imagine that the displays available to a person will change dynamically over the course of a work session. For example, while leaving your car or bus on the way to the office, you might only have access to your smartphone, allowing you to view a single data display at a time. Once you get to your office and your desk, you can boot up your computer and distribute an entire visualization dashboard across your monitors as well as your personal devices. Finally, when you head into the conference room for a meeting, the projected screen as well as the laptops belonging to your colleagues could be used to display even more detailed data visualizations. However, for this to be practical, the layout of visualizations across available displays should be automatic, lest the user gets continually bogged down by moving charts around. Furthermore, such a layout must organize closely related charts together on the same display as well as respect their geometry affinity.
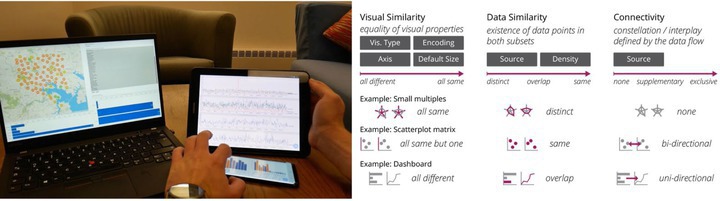
Such dynamic layout across ubiquitous analytics environments was our focus in the Vistribute28 system (Figure 5) from 2019. Based on a design space of visualization relationships (Figure 5, right), the Vistribute layout manager performs real-time constraint solving based on a set of high-level visualization-layout heuristics. These heuristics include multi-chart relationships, such as the visual and data similarity as well as data-flow connectivity in the figure, but also single-chart heuristics. For example, dense data displays, such as geographical maps, are given more display space while a skewed aspect-ratio chart, like a time-series line chart, will be given wide and short display allocations.
The VisHive toolkit14 tackles a different but similar problem: computational resource management. More specifically, mobile ubiquitous analytics often call for significant computation, such as when performing textual analysis, clustering, or machine learning. The computational power of an individual mobile device may be insufficient to complete this calculation on its own in a timely manner. One solution is to simply use a remote computational resource, but even if the Internet connectivity would be there—which is not a given in many mobile on-the-go situations—the data to be processed is often simply too large to effectively upload on the fly. The VisHive system solves this by forming an ad hoc cluster, or hive, of mobile devices for load-balancing computation in the field. Designed to work in conjunction with Web-based visualization systems, VisHive is a small JavaScript library that runs directly in a device’s Web browser and requires no specialized software to be installed on the device. In this way, a user can simply bring additional mobile devices online to help process computational tasks in case a particular computation is taking too long to complete.
Takeaway. Resource management across multiple devices involved in a ubiquitous analytics environment should be automated to minimize the user burden.
Multiple collaborators. Finally, the third cardinality factor in a ubiquitous analytics system is the individual users who often collaborate on realistic tasks. In general, collaborative visualization is a grand challenge of data visualization research, but ubiquitous analytics have the benefit of being designed to be collaborative from the very foundation. For example, the David & Goliath system can easily be used in a collaborative manner (as in Figure 3), and the two different interfaces in ReLive could just as easily be employed by two parallel users rather than the same one in sequence.
One example of this is the Branch-Explore-Merge (B-E-M) tabletop system38 we proposed in 2012 for collaborating across tabletops and mobile devices (Figure 6). A precursor to the D&G system discussed earlier, B-E-M uses the same philosophy of private and personal devices (smartphones and tablets) vs. public and shared devices (large touch tabletops in this case) as in the smartwatch and wall display scenario. With B-E-M, however, the focus is specifically on the coordination and consensus mechanisms required for a visualization system used by multiple users. While a user should be able to modify the visualization on their own personal device at will, any change made on the shared tabletop will directly affect all collaborators. To manage this process, B-E-M draws on basic revision-control principles from software engineering, where the user can branch the current state of the shared display on their own device, explore the data on their own, and then finally merge back their changes—or discard them if the exploration turns out to be a dead end. The B-E-M system requires a vote from all participants around the tabletop for changes to be merged back onto the shared display.
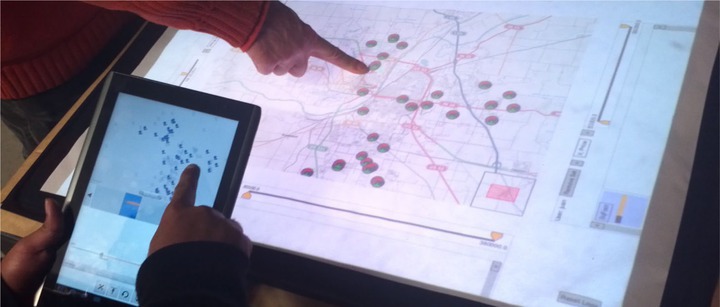
Voting is a somewhat disruptive coordination mechanism, and often more implicit mechanisms are better. In the Proxemic Lens2 project from 2016, we used proxemics information24 such as the distance between users, the direction of their body and head, their hand and foot gestures, and the spatial arrangement of objects and people in 3D space to guide interaction. The goal of the project was to infer user intention in a ubiquitous analytics scenario from their body language and physical navigation in a space. We were particularly interested in studying how a large shared display can be best utilized depending on the collaborative coupling of the people using it: separate viewports (lenses) for people working independently and stacked or overlaid viewports for people working closely together (Figure 7). We used a static environment and a floor-to-ceiling display with a Vicon motion-capture system to track this information for multiple collaborators, but mobile environments will require more subtle biometric or inertial-sensing technology. Overall, participants enjoyed the implicit interaction of the Proxemic Lens system, and their intention was often inferred correctly. However, they also indicated a preference for explicit rather than implicit gestures for actions typically seen as commands, such as creating charts, splitting viewports, and consensus operations (Figure 7, right).
Takeaway. Collaboration in ubiquitous analytics requires careful consideration of coordination and consensus, just like for general collaborative work, but the heterogeneous devices typically employed in ubiquitous analytics settings makes integrating such coordination mechanisms straightforward.

Challenges and Outlook
This future vision for data analytics is still a new notion, and its various manifestations as visual, ubiquitous, immersive, and situated analytics are still nascent and emergent. My research group has been a significant driver in this field, but the story is much bigger than just our efforts. The greater research community is energetic and growing, with new and exciting analytical systems being proposed at every major conference and journal issue; certainly too many to discuss in a single review article. However, we claim that the techniques and technologies described here represent a cross-section of ubiquitous analytics research.
Based on this review, we would summarize our takeaways using a single theme: device diversity. Basically, it is the varied and heterogeneous nature—as well as their effective utilization—of the individual devices involved in a sensemaking task that makes ubiquitous analytics powerful. This idea is also supported by the post-cognitive frameworks discussed in this article.
If heterogeneity is the lead theme of ubiquitous analytics, where is the field going in the future? Ens et al.21 presented a vision for immersive analytics in 2021 and outlined the grand research challenges of that field. We support these challenges in general but complement their technical nature with our own list of higher-level future challenges:
The future is mixed. While handheld devices with screens are here to stay, it seems almost inevitable that future devices will eventually be based on augmented and mixed reality.43 Augmented-reality and mixed-reality displays have the capacity to turn the entire surrounding world into a canvas for visual data displays, and the technology is constantly improving. This should mean that immersive 3D visualizations and interaction techniques will become increasingly important in the future.
Human-centered artificial intelligence teaming. While mostly glossed over in this article, the future of ubiquitous analytics is closely entwined with artificial intelligence. Only with powerful automated algorithms and recommendations at our beck and call will we be able to overcome the computational challenges of tomorrow. However, rather than the black-box pipeline model of traditional AI, we believe in the use of visual interactive interfaces as inflection points for involving human operators in the loop. This is known as human-centered artificial intelligence (HCAI),42 but this is outside the scope of this article.
Standards, components, and practices. If future sensemaking environments are characterized by heterogeneous systems and devices, then we will need standards as well as standardized components and practices to enable multiple vendors to provide their own versions of these tools. While there exist several immersive analytics12 and augmented-reality toolkits,23 we will need a much richer ecosystem, including for software development, session and view management, navigation, and so on. Furthermore, many existing toolkits are built on proprietary 3D game engines, such as Unity. It is difficult to predict the future here, but based on past history, technologies based on open standards, such as the Web-based VRIA7 and Vistrates5 toolkits, are safer bets than those built on closed and proprietary technology.
Accessibility and inclusivity. The field of data visualization is just now recognizing the accessibility of interactive visual representations to people with visual, motor, or cognitive impairments. Ubiquitous analytics will need to learn from these lessons at an early stage. However, the heterogeneous nature of ubiquitous analytics can once again play in our favor in that the inclusion of diverse platforms into the sensemaking loop may make it easier to accommodate people of varying physical and cognitive ability.
Of scale and scalability. With the exception of the VisHive project, most of this paper has not concerned itself with large-scale data management. While data visualization is often seen as a best-in-class solution for the human aspect of big data,22 there are many challenges on the computational and data-management sides that must be solved to enable mobile sensemaking at this scale and magnitude.
Evermore everywhere. Similarly, while the everywhere data aspect of this article is more about providing opportunity for anywhere data, we still need further work on capturing, integrating, and synthesizing heterogeneous data from multiple sources in our environment. While privacy and security must remain foremost in our minds, such new data about our world will only continue to make data-driven decision-making better and more effective.
The current state of ubiquitous data analytics has been more than 10 years in the making. There is now a thriving and creative research community that is invested in taking this vision forward into the future. Perhaps one day we will truly see sensemaking become embedded into the fabric of everyday life.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment