
This is a slightly adapted version of an article first posted on my personal blog; perhaps it can be of interest to the CACM blog readers as well. It started with a quiz:
I have a function:
- For 0 it yields 0.
- For 1 it yields 1.
- For 2 it yields 4.
- For 3 it yields 9.
- For 4 it yields 16.
What is the value for 5?
Now about the picture below: it has nothing to do with the article’s theme (except, of course, for the pursuit of beauty), but will keep your eyes away from the spoiler appearing below — while, as I hope, brightening your day — as you make up your own answer.

To help you get further, here is a hint: the value for 5 is in fact, 25. Correspondingly, the question changes to: “What is the value for 6?“. For good measure we can also ask about the value for 1000.
Now compare your answer to what follows after the second SPD (Spoiler-Protection Device).

A good answer for the value at 6 is: 34 . It follows from assuming that the function is
-10 + 5 x + |2 x – 3| + |2 x -7|
which matches the values for the given inputs:
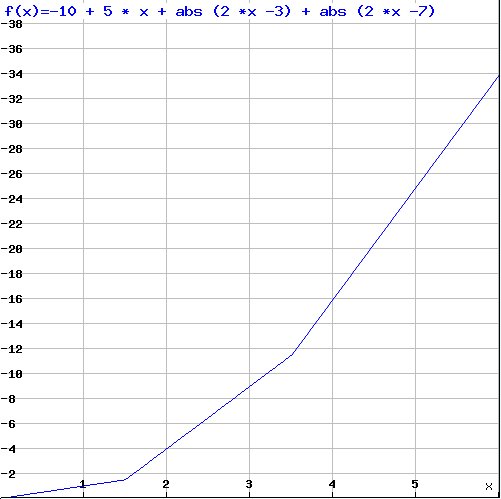
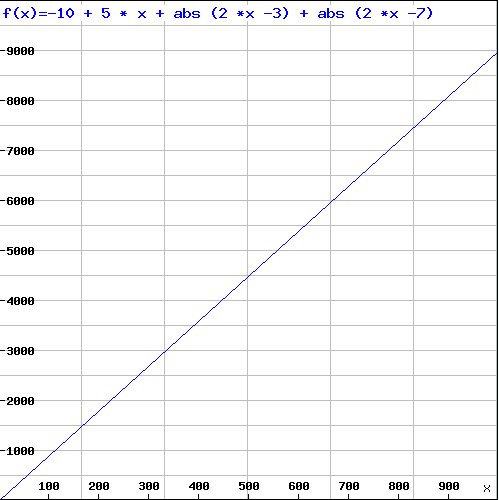
With this choice the value for 1000 is 8980:
Another good answer at position 6 is 35.6. It comes up if we assume the function is over reals rather than integers; then a possible formula, which correlates remarkably well (R-square of 0.9997) with the values at the given inputs, is:
869.42645566111 (1 -0.4325853145802 e-.0467615868913719 (x – 17.7342512233011))2.3116827277657443
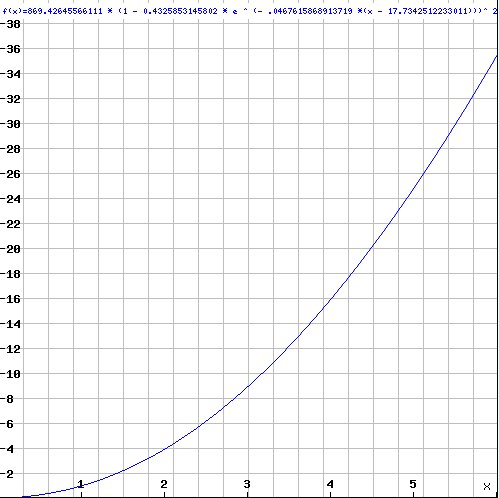
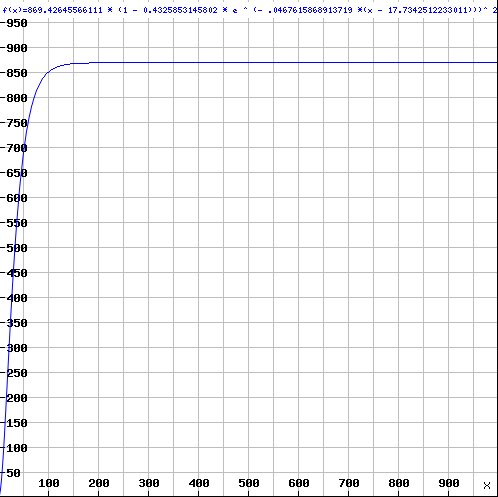
with a quite different asymptotic behavior, giving the value 869.4 at position 1000:
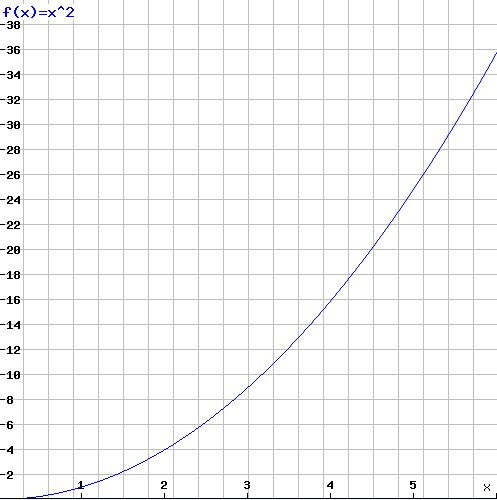
Some readers might have thought of another possibility: 36 at position 6 and one million at 1000. Indeed the square function x2 matches all the given values:
So which of these answers is right?
Each is as good as the others, and as bad. There is in particular no reason to believe that the values given in the quiz’s statement suggest the square function. Any function that fits the given values, exactly (if we stick to integers) or approximately (with reals as simulated on a computer), is an equally worthy candidate. Six inputs, or six thousand, do not resolve the question. At best they are hints.
This difference between a hint and a solution is at the core of software engineering. It is, for example, the difference between a test and a specification. A test tells us that the program works for some values; as Dijkstra famously pointed out, and anyone who has developed a serious program has experienced, it does not tell us that it will work for others. The more successful tests, the more hints; but they are still only hints. I have long wondered whether Dijkstra was explicitly thinking of the Popperian notion of falsifiability: no number of experiments will prove a physical theory (although a careful experiment may boost the confidence in the theory, especially if competing theories fail to explain it, as the famous Eddington expedition did for relativity in 1919 [1]); but a single experiment can disprove a theory. Similarly, being told that our function’s value at 6 is 34 disqualifies the square function and the exponential, but does not guarantee that the first function (the linear combination) is the solution.
This specification-testing duality is the extension to computer science of the basic duality of logic. It starts with the elementary boolean operators: to prove a or b it suffices to establish a or to establish b; and to disprove a and b it suffices to show that a does not hold or to show that b does not hold. The other way around, to disprove a or b we have to show that a does not hold and to show that b does not hold; to prove that a and b holds, we have to show that a holds and to show that b holds. Predicate calculus generalizes or to ∃, “there exists”, and and to ∀, “for all”. To prove ∃ x | p (x) (there is an x of which p holds) it suffices to find one value a such that p (a); let’s be pretentious and say we have “skolemized” x. To disprove∀ x | p (x) (p holds of all x) it suffices to find one value for which p does not hold.
In software engineering the corresponding duality is between proofs and tests, or (equivalently) specifications and use cases. A specification is like a “for all”: it tells us what must happen for all envisioned inputs. A test is like a “there exists”; it tells us what happens for a particular input and hence, as in predicate calculus, it is interesting as a disproof mechanism:
- A successful test brings little information (like learning the value for 5 when trying to figure out what a function is, or finding one true value in trying to prove a ∀ or a false value in trying to prove a ∃).
- An unsuccessful test brings us decisive information (like a false value for a ∀): the program is definitely not correct. Such a test skolemizes incorrectness.
A proof, for its part, brings the discussion to an end when it is successful. In practice, testing may still be useful in this case, but only testing that addresses issues not covered by the proof:
- Correctness of the compiler and platform, if not themselves proved correct.
- Correctness the proof tools themselves, since most practical proofs require software support.
- Aspects not covered by the specification such as, typically, performance and usability.
For the properties it does cover, the proof is final. It is as foolish, then, to use tests in lieu of specifications as it would be to ignore the limitations of a proof.
Agile approaches have caused much confusion here; as often happens in the agile literature [2], the powerful insight is mixed up with harmful advice. The insight, which has significantly improved the practice of software development, is that the regression test suite is a key asset of a project and that tests should be run throughout. The bad advice is to ditch upfront requirements and specifications in favor of tests.
The property that tests lack and specifications possess is generality. A test is an instance; a thousand tests can never be more than a thousand instances. As I pointed out in a short note a few years ago [3], the relationship is not symmetric: one can generate tests from a specification, but not the other way around. You can get the omelette from the eggs, but you cannot get the eggs from the omelette.
The same relationship holds between use cases and requirements. It is stunning to see how many people think that use cases (scenarios) are a form of requirements. As requirements they are as useless as one or ten values are to defining a function. Use cases are a way to complement the requirements by describing the system’s behavior in selected important cases. A kind of reality check, to ensure that whatever abstract aims have been defined for the system it still covers the cases known to be of immediate interest. But to rely on use cases as requirements means that you will get a system that will satisfy the use cases — and possibly little else.
One of my first assignment in the first company I worked for was to evaluate a system that a contractor had developed for us. The contract specified 15 test cases, and the program performed perfectly in each of them. It did little else. The passing criteria were clear, so we had no choice but to pay the contractor (along with deciding to go with someone else for subsequent projects). One might think that things have changed, but when I use systems designed in recent years, in particular Web-based systems, I often find myself in a stranglehold: I am stuck with the cases that the specifiers thought of. Maybe it’s me, but my needs tend, somehow, to fall outside of these cases.
Actually it is not just me. A few weeks ago, I was sitting close to a small-business owner who was trying to find her way through an insurance site. Clearly the site had a planned execution path for employees, and another for administrators. Problem: she was both an employee and the administrator. I do not know how the session ended, but it was a clear case of misdesign: a system built in terms of standard scenarios. Good specification performs an extra step of abstraction (for example using object-oriented techniques and contracts, but this is for another article). Skipping this step means forsaking the principal responsibility of the requirements phase: to generalize from an analysis of the behavior in known cases to a definition of the desired behaviors in all relevant cases.
Once more, as elsewhere in computer science [4], abstraction is the key to solid results that stand the test of time. Definitely better than judging a book by its cover, inferring a function by its first few values, verifying a program by its tests, looking for an egg in its omelette, or specifying a system by its use cases.
References
[1] See e.g. a blog article: Einstein and Eddington, here.
[2] Bertrand Meyer: Agile! The Good, the Hype and the Ugly, 2013, to appear.
[3] Bertrand Meyer: Test or spec? Test and spec? Test from spec!, EiffelWorld column, 2004, available here.
[4] Jeff Kramer: Is Abstraction the Key to Computer Science?, in Communications of the ACM, vol. 50, no. 4, April 2007, pages 36-42.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment