
The next ubiquitous computing platform, following personal computers and smartphones, is likely to be inherently autonomous in nature, encompassing drones, robots, and self-driving cars, which have moved from mere concepts in labs to permeating almost every aspect of our society, such as transportation, delivery, manufacturing, home service, and agriculture.23,35 By the end of 2025, it is projected that 284 million vehicles will be operating in the U.S., with most of them having certain degrees of autonomy.29 Similarly, the automated drone market is expected to reach $42.8 billion USD, with annual sales exceeding two million units.28
Behind the proliferation of autonomous machines lies a critical need to ensure reliability10,34 Recent high-profile tragedies18 have underscored the importance of building reliable computing systems for autonomous machines. For instance, almost every vendor, be it in the software, hardware, or systems segment, must conform to functional safety standards when delivering products for automotive use.
Key Insights
The safety and resilience of autonomous machines are of significant concern—hardware and software faults can lead to safety hazards.
Not all algorithmic kernels in the autonomous machine software stack are equally resilient—front-end kernels are generally more robust compared to back-end kernels.
Vulnerability-adaptive protection is a cost-effective approach to enhance the reliability of autonomous machines; the protection budget, be it spatial or temporal, should be proportionally allocated based on the inherent resilience of kernels.
An autonomous machine is essentially a cyber-physical system; the resilience of its cyber components (compute) impacts its physical performance.
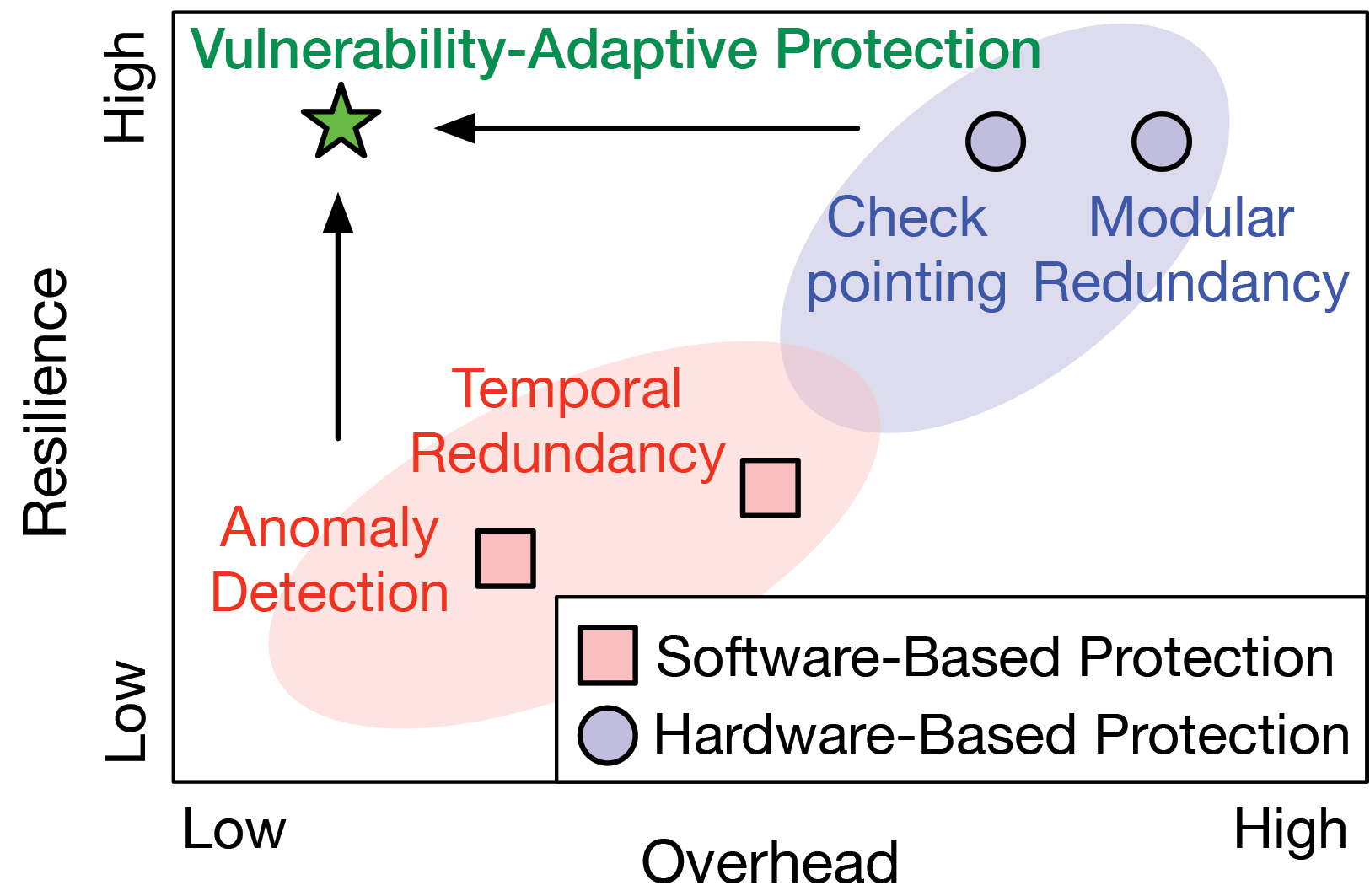
Today’s resiliency solutions for autonomous machines make fundamental trade-offs between resiliency and cost, which manifests as high overhead in performance, energy consumption, and chip area. For instance, hardware modular redundancy provides high safety but more than doubles the area and energy cost of the systems.1 Fundamentally, today’s protection solutions are of a “one-size-fits-all” nature: They use the same protection scheme throughout the entire software computing stack of autonomous machines.
The insight of this article is that for a resiliency solution to provide high protection coverage while introducing little cost, we must exploit the inherent robustness variations in the autonomous machine software stack. In particular, we show that different nodes in the complex software stack differ significantly in their inherent robustness under hardware faults: The front end of an autonomous machine software stack is generally more robust, while the back end is less so.
Building on the inherent differences in robustness, we advocate for a vulnerability-adaptive protection (VAP) design paradigm. In this paradigm, the protection budget, be it spatial (for example, modular redundancy) or temporal (for example, re-execution), is inversely proportional to the inherent robustness of a task or algorithm that is under protection. Designers should dedicate more protection budget to less robust tasks.
The VAP design paradigm is in stark contrast to the existing “one-size-fits-all” resiliency strategy, which uniformly applies the same protection strength to all tasks in the computing systems. As a result, existing strategies must accommodate the worst case (that is, the least robust component), leading to a high protection overhead. In contrast, VAP wisely allocates the protection budget based on the inherent robustness of each node, achieving the same protection coverage with minimal overhead.
In summary, we make the following contributions:
We present a comprehensive review of the design landscape for resilient autonomous machines. We show that existing techniques are of a “one-size-fits-all” nature, where the same protection scheme is applied to the entire software stack, leading to either high overhead or low protection strength.
We provide a thorough characterization of the inherent resilience of different tasks in widely used, open source software stacks for autonomous vehicles (AutoWare) and drones (MAVBench). We show that different tasks vary significantly in their resilience under hardware faults. In particular, front-end machine vision tasks that operate on massive visual data are much more resilient to faults than back-end tasks, such as planning and control, which operate on smaller data but are more sensitive to faults.
We propose VAP for resilient autonomous machines. In VAP, we spend less protection efforts on front-end machine-vision tasks and more budget on back-end planning and control tasks. Experimentally, we show that the VAP mechanism provides high protection coverage while maintaining low protection overhead on both autonomous vehicle and drone systems.
Design Space of Resilient Autonomous Machines
The design space of resilient autonomous machines is extremely complicated. From a system designer’s perspective, latency, energy, cost, and resilience are all critical metrics that need to be cared about. In this article, we first describe the sources of errors, and, in the following sections, propose the design space and then summarize the landscape of resiliency solutions.
Fault sources. Different sources of errors can affect the resilience of autonomous machines, including adversarial attacks, software bugs, and common bit flips.33,38,40 In this article, we consider hardware bit flips that occur in a single compute cycle. This type of fault is usually referred to as a soft error, serving as one of the most dominant errors influencing autonomous machine systems. The exacerbating impact of soft errors has been recently emphasized by industrial studies,13 where radiations and temperature change can result in random bit flips in silicon flip-flop units and memory cells. Future trends of increasing code complexity and shrinking feature sizes will only exacerbate the problem.
Soft errors can result in different misbehaviors of autonomous machine systems. The most common one is silent data corruption (SDC), where the results are incorrect but the incorrect execution does not lead to a visible system failure.7 In other cases, the effect of soft errors is visible; for instance, a process might hang or crash. Visible soft errors are relatively easier to address; for instance, we can simply restart the process under impact. SDCs, however, are harder to catch due to their silent nature and, thus, could lead to more serious issues. For example, an SDC on the control command can lead to an unexpected accelerating command instead of the original decelerating command, posing a severe operational safety concern.
Specifically, in our resilience analysis, we inject faults in the CPU/GPU architectural state. Memory and caches are assumed to be protected with ECC codes. Each injected fault is characterized by its location and the injected value. The faults injected into the architectural states of these processors can manifest as errors in the inputs, outputs, and internal state of the autonomous machine modules. Bit faults cause corruption of variables when not masked in hardware and propagate to the module output.
Metrics and design constraints of resilient autonomous machines. Before introducing fault protection schemes, we describe key metrics that any autonomous machine must optimize for: resilience, latency, energy consumption, and cost.
Resilience. A metric to quantify resilience is important in our design space as we strive to build a robust autonomous machine. We use the error propagation rate (EPR) as the resilience metric for autonomous vehicles.9 EPR indicates the percentage of the final output of the autonomous vehicle (AV) software that is influenced when an error occurs at an earlier kernel. We obtain this metric by comparing the ground truth with the output after error injection. The lower the EPR, the better the resilience.
Latency. To guarantee resiliency, we trade off other metrics in the design space, where compute latency is the most important among them. The end-to-end compute latency, which is the time between when a new event is sensed from the surroundings and when the vehicle takes action, can impact whether an autonomous machine can stop or decelerate to avoid objects safely.
The extra computation brought by the protection scheme will increase end-to-end compute latency and further negatively impact the safe object avoidance distance. Figure 2(a) illustrates the relationship between compute latency and object avoidance distance deriving from our concrete vehicle data analysis.37 The baseline vehicle operates at a typical speed of 5.6 with 4 brake deceleration, and is equipped with powerful CPU and GPU for computationally intensive autonomy algorithms. The vehicle has an average computing latency of 164, meaning the vehicle could avoid objects that are 5 away or farther once detected. This latency model illustrates how much compute latency matters in the end-to-end autonomous vehicle system, providing budget guidance for fault-protection-scheme overhead and impact analysis.
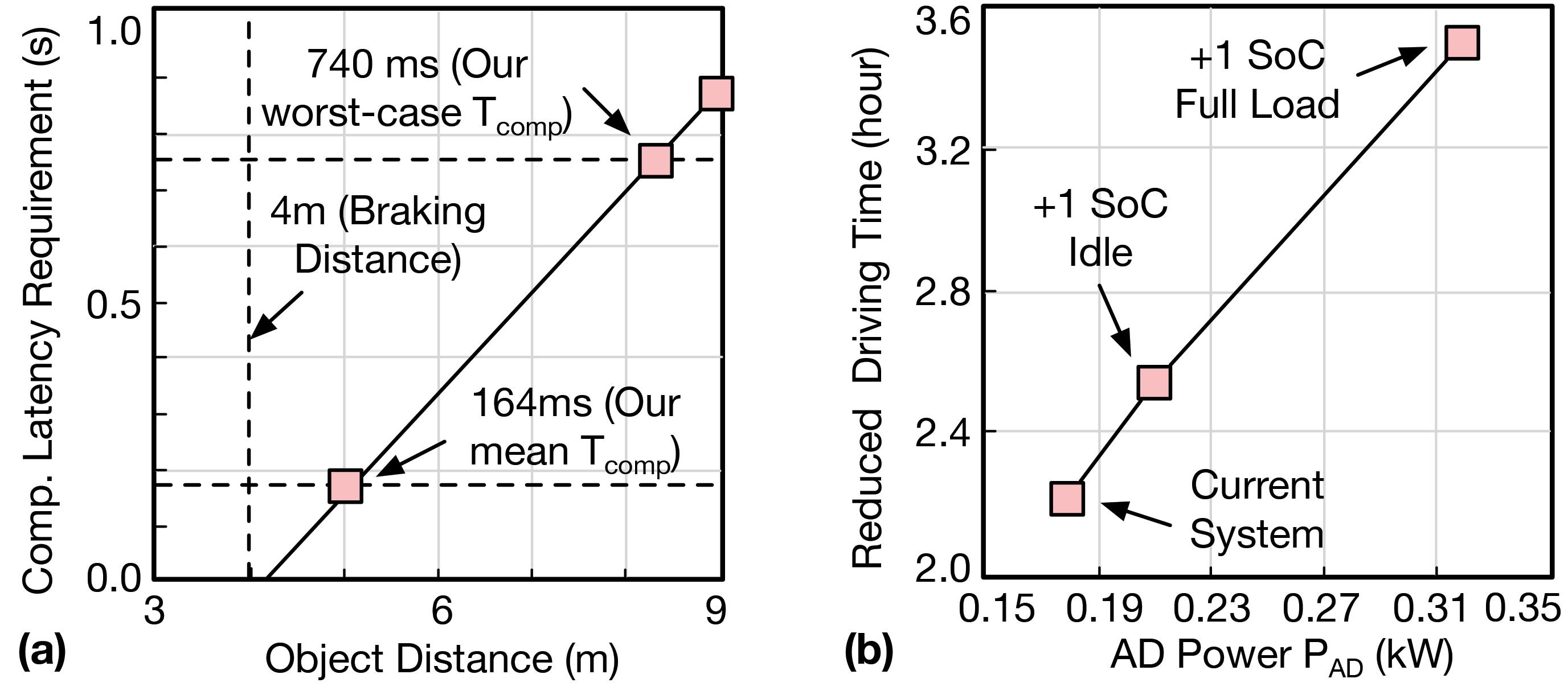
Energy. Energy consumption closely correlates with automotive endurance. With the trend toward electrification, the majority of vehicles in the future will be powered by batteries.
The extra energy consumed by autonomous-driving computing systems will reduce vehicle operating time and translate to revenue loss for commercial vehicles. Figure 2(b) demonstrates the relationship between the power of the autonomous driving system and reduced driving time.37 The vehicle is powered by batteries that have a total energy budget of 6·. The vehicle itself consumes 0.6 on average, and enabling autonomous driving consumes an additional 0.175, allowing for 7.7h of driving time under a single battery charge. The extra energy consumption from the protection scheme will further reduce operating time. This energy model allows us to understand how extra energy consumption brought by the protection scheme would impact the driving time and daily revenue of the vehicle.
Cost. Cost overhead is important to almost every vendor. We analyze extra chip area and silicon cost for autonomous vehicles and drone systems brought by various fault-protection schemes.
Landscape of protection techniques. Different protection techniques exhibit distinct performance, efficiency, cost, and resilience impacts on autonomous machines. Table 1 compares four software and hardware protection schemes and illustrates their trade-off in the resilient autonomous machine design. We reveal that conventional “one-size-fits-all” approaches are limited by the trade-off in overhead and resilience improvement.
Evaluation | Software-Based | Hardware-Based | VAP | ||
|---|---|---|---|---|---|
Anomaly Detection | Temporal Redundancy | Modular Redundancy | Checkpointing | Front end: SW | |
| Latency | ✗ | ✗ | ✔ | ✗ | ✔ |
| Energy | ✔ | ✗ | ✗ | ✔ | ✔ |
| Cost | ✔ | ✔ | ✗ | ✗ | ✔ |
| Resilience | ✗ | ✗ | ✔ | ✔ | ✔ |
We first analyze two software-based protection schemes. Software-based protection schemes usually exhibit advantages in lower engineering cost and power overhead, but they suffer from compute-latency overhead and incomplete fault recovery.
Anomaly detection. Anomaly detection is generally used to identify rare observations which significantly deviate from the majority of data. In autonomous scenarios with a large number of abnormal behaviors, anomaly detection may incur high latency overhead due to the node re-execution and cannot fully mitigate fault impact due to false-positive detection in corner cases.9,32
Temporal redundancy. Temporal redundancy refers to executing the code more than once with the same piece of hardware. The redundant executions can help alleviate the threat of silent data corruption caused by soft errors as they are transient. The temporal data diversity and redundancy in the sensor data can also be exploited in detecting hardware faults.15,16 Temporal redundancy typically incurs large compute latency and energy overhead due to the redundant sequential executions and may not be able to detect all faults due to the continued existence of few hardware defects.
We then analyze two hardware-based fault-protection schemes: modular redundancy and checkpointing. Hardware-based protection schemes typically offer effective error mitigation but incur significant power overheads and additional costs.
Modular redundancy. Modular redundancy (that is, spatial redundancy) refers to executing the same node on two or more hardware platforms. For instance, Tesla’s Full Self-Driving chip duplicates the entire processing logic, with one copy serving as a backup in case the other encounters unrecoverable errors. Similarly, NVIDIA Orin chips for self-driving applications enable full system duplication and lock-step execution.1,6 Other established methods include triple modular redundancy, which involves three identical hardware instances with voting logic at the output. If an error affects one hardware instance, the voting logic records the majority output and masks the malfunctioning hardware. Modular redundancy is typically effective in fault detection with negligible impact on latency, though it incurs considerable energy and silicon costs.
Checkpointing. Checkpointing refers to periodically storing a fault-free copy of the processor state so that computation can continue from that point without altering the autonomous machine’s behavior.4 A rollback consists of a recovery mechanism that restores the processor to a previous safe state in case the autonomous machine crashes due to a failure in the underlying system. The conventional checkpointing method usually accompanies dual modular redundancy and brings large runtime overhead due to the store-and-retrieve procedure that may violate the real-time nature of autonomous machines. Checkpointing can also implemented in a software manner17 that trades off between efficiency and overhead. Including hardware support in saving checkpoints and re-executing can increase efficiency significantly. Since autonomous machines continuously interact with their environments and have strict real-time and efficiency requirements, we particularly refer to hardware checkpointing in the protection landscape.
Conventional “one-size-fits-all” hardware or software-based protection techniques are limited by the fundamental trade-off between performance overhead and resilience improvement in the design space of autonomous machines. Recently, automotive safety integrity level (ASIL) decomposition39 is proposed to decompose the automotive code with higher ASIL standards into different pieces of lower ASIL standards, and then place the decomposed pieces on different cores. As in Figure 1, in this work, we aim to push the landscape frontier to the top-left corner with low overhead and high resilience. Thus, we leverage the insight from inherent systems performance and resilience characteristics and propose to overcome this trade-off by concurrently optimizing performance-efficiency-resilience with an intelligent VAP paradigm.
System Characterization Study
This section characterizes the performance and resilience of different modules in a typical autonomous machine system. Autonomous machine computing differentiates from traditional systems in dataflow, software pipeline, compute substrate, and underlying architecture.25 Our characterization suggests that different modules exhibit diverse performance and resilience features. The front-end of the autonomous system (sensing, localization, perception) usually has higher resilience but also higher latency and energy consumption, while the back-end (planning, decision-making, control) is more vulnerable to errors but has lower latency.
We introduce an autonomous machine system and first use the autonomous vehicle as an example. For each module, we quantify their reliability using the quantitative metric and show the inherent trade-off between resilience and performance. We then illustrate a similar finding with drones as another example.
Performance and resilience trade-offs in autonomous vehicles. A typical autonomous machine system consists of five components: sensing, perception, localization, planning, and control. Sensor samples are first synchronized and processed before being used by the perception and localization modules. The localization module localizes the vehicle to the global map, and the perception module tries to understand the surroundings by detecting and tracking objects. The perception and localization results are used by the planning module to plan a path and generate control commands. The control module will smooth the control signals and transmit them through to the vehicle’s engine control unit. The control signals control the vehicle’s actuators, such as the gas pedal, brake, and steering wheel. Each module contains one or more nodes, and each node is an individual process while the system is running.
Front-end modules: Sensing, perception, and localization. We separate the computing pipeline of autonomous machines into front end and back end. The front end consists of three modules: sensing, perception, and localization. The front end deals with sensor data and provides semantic results for the back end.
Sensing. Sensing tries to capture the environments5,26 and is time-consuming. We show one of the nodes in the sensing stage in Figure 3(a), the average latency of the specific node is on the left y-axis. A node is an individual process performing certain tasks in a robot operating system (ROS). Ray_filter filters the LiDAR points to represent the ground. The average runtime of ray_filter is 29.6ms, which is a significant latency in an autonomous vehicle pipeline.
Perception. Perception helps to build reliable and detailed representations of the dynamic surroundings based on sensory data.11,27 The perception module is inherently computationally intensive and usually contributes the longest latency in autonomous machines. The serial processing of detect, track, and predict in the perception pipeline exacerbates computing latency. Although most perception nodes have been accelerated by GPUs or other accelerators, the perception stage still takes more than 100ms to finish. Figure 3(a) shows that the vision_detect node contributes 42.2ms to the entire pipeline, and lidar_detect node also has a latency of 15.5ms.
Localization. Localization serves to calculate the position and orientation of an autonomous machine itself in a given frame of reference. Localization algorithms usually have high computational requirements. These algorithms, such as simultaneous localization and mapping (SLAM),31 and visual inertial odometry (VIO),2 first capture correspondence in continuous frames, and then use multiple correspondences to solve a complex optimization problem for the final pose. A typical SLAM algorithm takes tens of ms latency even running on a powerful Intel CPU.22,36 The VIO algorithm exhibits similar latency.30 Figure 3(a) shows that our autonomous vehicle pipeline uses ndt_matching as the localization algorithm, with an average latency of 35.2ms.
Back-end modules: Planning, decision making, and control. The back end of the autonomous machine autonomy pipeline contains three modules: planning, decision-making, and control. The results of the back end directly control the actuators.
Planning. Planning tries to find a collision-free path from the current location to the destination.8,12 Planning algorithms usually rely on the occupancy grid produced by the perception module and indicates whether the locations are free or occupied. Once the occupancy grid map is generated, it will not change during one planning process. The start location on the occupancy grid map is determined by the localization module.
Decision making. Autonomous machines use state machines to control behavior, where the state machine is controlled by the decision-making module. For example, in Autoware, when an autonomous vehicle detects a pedestrian close by, the decision-making module will turn the vehicle’s status from driving to stopping. Decision making also relies on the results of perception and localization. Similar to the planning module, decision making is also vulnerable to errors as it directly influences the agent’s behavior.
Control. Control is the last module in the autonomous machine pipeline, which is responsible for smoothing the control commands. The control module is the most lightweight module in autonomous machine software but it is the most vulnerable to errors.
Figure 3(a) shows three nodes from the backend: pure_pursuit, twist_filter and twist_gate. All three nodes have very low latency, which is less than 0.1 ms, however, they all have high EPR compared to the front-end. pure_pursuit has an EPR of 20.3%, twist_filter has an EPR of 70.8% and twist_gate has an EPR of 80.2%.
Performance and resilience trade-offs in autonomous drones. In the autonomous vehicle pipeline, the front end usually contributes to higher latency in the pipeline while being more robust. The back end is usually low in compute complexity but is vulnerable to errors. We find a similar trend existing in autonomous drones with characterization study on MAVBench simulator.3
Figure 3(b) shows the trade-off between performance and resilience in drones, with the average latency and the mission failure rate. All three nodes in the front end, Point Cloud (P. C.) Generation, Octomap, and Collision Check (Col. CK.), have very high average latency but low mission-failure rate. The highest mission-failure rate happens at Col. CK., which is only 3.6%.
We have a similar observation in the back-end. Figure 3(b) shows that all four nodes in the back end contribute to much less latency compared to the front end. However, the mission failure rates of the four nodes are all significantly higher. In a typical drone autonomy pipeline evaluated on MAVBench, within the total end-to-end compute latency of 871, the front-end modules of the drone system contribute 688 (79%), while back-end modules contribute 183 (21%). However, the average mission failure rate of the back-end is more than 2 higher compared to the front-end.
Vulnerability-Adaptive Protection Design Methodology
Leveraging the insights of distinct performance and resilience characteristics of front-end and back-end kernels, we propose an adaptive and cost-effective protection design paradigm for autonomous machine systems, achieving high operation resilience and safety with negligible latency and energy overheads.
Design paradigm. The key principle of our adaptive fault protection scheme is vulnerability-adaptive protection, the protection budget is allocated proportionally to the inherent resilience of autonomous machine kernels. If an autonomous kernel is robust to errors, we will protect it with a lightweight method, such as software-based protection. In contrast, if the kernel is vulnerable to errors, we will spend more effort protecting it, such as hardware-based protection. This adaptive scheme can adapt to different autonomy paradigms and improve autonomous machine resilience while maintaining low computation and power overhead.
Specifically, we propose to apply a software-based protection scheme on front-end kernels and hardware-based protection scheme on back-end kernels as an adaptive design paradigm, as shown in Figure 4. This is inspired by the insights from system performance and resilience characterization on exampled autonomous vehicle and drone systems (Figure 3), where it is well observed that the front-end kernels (for example, sensing, perception, localization) are resilient to faults but have heavy computation, while back-end kernels (for example, planning, decision making, control) are vulnerable to faults but have a small amount of computation.
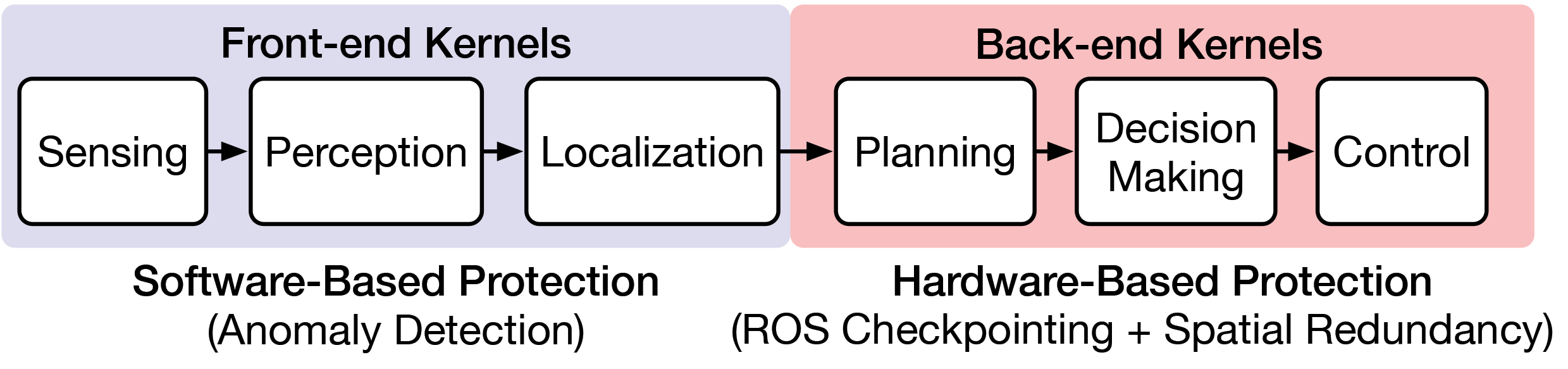
Front end: Software-based protection. We apply anomaly detection in autonomous-machine, front-end sensing-perception-localization kernels (Figure 4). We leverage three insights for front-end protection. First, the vehicles or drones typically process temporal inputs and generate temporal outputs. For instance, the sequences of sensor inputs usually exhibit strong temporal consistency and continuous property. Moreover, when a vehicle is driving in a straight line, it is unlikely that the path planning module will issue a sudden actuator acceleration. Therefore, the outputs of consecutive time steps are usually bounded in the fault-free case, and errors in autonomous machines are sometimes manifested as outliers that break the temporal consistency and can be detected. Second, front-end kernels have inherent error-masking and error-attenuation capabilities through redundant information and operations, such as low-pass filtering and operator union. For example, an autonomous machine can tolerate a significant input-data rate drop without causing safety hazards. Third, front-end kernels exhibit rare false positive detection with anomaly detection, thus significantly reducing the node re-execution overhead and protection-failure cases.
To facilitate the proposed protection scheme in a plug-and-play manner, we propose to design anomaly detection as a ROS node. In this way, the autonomous machine code can be treated as a black box, and designers can directly integrate the protection scheme in the autonomous system through standard ROS function calls.
Back end: Hardware-based protection. We apply modular redundancy and checkpointing in autonomous-machine, back-end planning-control kernels (Figure 4), by periodically storing a fault-free copy of the architectural state and executing the same code on two hardware modules. We leverage three insights for back-end protection. First, back-end kernels are very critical to errors (Figure 3), motivating us to strengthen fault protection with the hardware-based method. Second, the back-end nodes are extremely lightweight and do not perform any complicated computation, thus the overhead of running software calculations (for example, anomaly detection) would be large, but the overhead of hardware-based protection would be small. Third, more false-positive detection cases are from the back end in software protection, which results in potential protection failure and needs to strengthen from hardware-based protection.
To improve resilience without impacting performance, we propose a selective redundancy and ROS-based checkpointing approach. We only make redundancy copy for the hardware core running back-end modules and keep all cores running front-end modules unchanged. In ROS, we periodically queue the ROS node message during the normal process. If faults are detected, the faulty node can directly re-execute as long as the restart point is before the ROS node communication. Since all computation occurs locally before node communication and the amount of back-end computation is small, we can guarantee robustness without incurring large checkpointing overhead. This checkpointing method designed for ROS eliminates the large compute latency overhead brought by conventional architectural-state checkpointing and restore methods that may violate the real-time nature of autonomous machines.
Scalability and adaptability. VAP is extensible to finer-grained stage-level or node-level protection. VAP can assign suitable protection schemes to each sensing-perception-localization-planning-control stage or each ROS node given the inherent node-level robustness variations (Figure 3). VAP is also extensible to other protection schemes, such as autoencoder-based anomaly detection and temporary redundancy.14 Moreover, VAP is adaptive for both pre-deployment and post-deployment protection scenarios. For pre-deployment, VAP offers the methodology to characterize the vulnerability of autonomous machine pipelines thus adaptively determining the protection scheme. For post-deployment, VAP can dynamically reschedule the ROS nodes across compute cores to adaptively switch between software and hardware protection.
Evaluation—Autonomous Vehicle
In this section, we demonstrate the advantages of our proposed adaptive protection design paradigm in performance and resilience. Evaluated on the Autoware autonomous vehicle system with design constraints, we illustrate that the adaptive protection technique VAP can achieve better resilience and lower error propagation rate, with lower latency, energy, and system performance overhead compared with conventional “one-size-fits-all” software and hardware-based protection techniques.
Adaptive protection improves resilience. VAP greatly reduces the error-propagation rate in autonomous vehicles by leveraging the insight of high resilience of front-end kernels with inherent error-masking capabilities and strengthening the back-end kernel resilience by hardware-based protection.
We integrate the VAP design into Autoware, with software-based anomaly detection in front-end modules, and hardware-based modular redundancy and ROS checkpointing in back-end modules. After injecting bit-flip faults in various front-end and back-end nodes across Autoware, we observe that the error-propagation rate maintains 0%, indicating all injected faults can be masked by the inherent robustness of the system or detected and mitigated by the proposed adaptive protection scheme. This level of resilience can also satisfy ASIL-D safety criteria.
VAP clearly demonstrates resilience improvement advantages with a lower error-propagation rate compared with conventional software and hardware-based techniques, as illustrated in Table 2.
| Fault Protection Scheme | Latency and Object Distance | Power Consumption and Driving Time | Cost | Resilience | |||||
|---|---|---|---|---|---|---|---|---|---|
Compute Latency () | Object Avoidance Distance () | AD Component Power ()* | AD Energy Change (%) | Driving Time (hour) | Revenue Loss (%) | Extra Dollar Cost | Error Propagation Rate (%) | ||
Baseline | No Protection | 164 | 5.00 | 175 | – | 7.74 | – | – | 46.5 |
| Software | Anomaly Detection | 245 | 5.47 | 175 | +33.14 | 7.20 | -6.99 | negligible | 24.2 |
| Temporal Redundancy | 347 | 6.05 | 175 | +75.24 | 6.62 | -14.52 | negligible | 11.7 | |
| Hardware | Modular Redundancy | 164 | 5.00 | 473 | +170.29 | 5.59 | -27.78 | (CPU + GPU)2 | 0 |
| Checkpointing | 610 | 7.56 | 324 | +91.52 | 6.42 | -17.13 | (CPU + GPU)1 | 0 | |
Adaptive Protection Paradigm (VAP) Front-end Software + Back-end Hardware | 173 | 5.05 | 175 | +4.09 | 7.67 | -0.92 | negligible | 0 | |
Compared with software techniques: Anomaly detection. Anomaly detection detects abnormal behaviors by leveraging the temporal consistency of autonomous machines. Evaluated on Autoware, anomaly detection can reduce the EPR from 46.5% to 24.2%. The reason that EPR is not further reduced is that in a few scenarios, the input information or output actions do have a sudden change, yet the anomaly protector treats it as an outlier and replaces it with the average value in the previous window or directly re-executes the node. These false-positive errors thus will propagate and result in non-perfect results. We observe that these false-positive cases mainly result from back-end modules. For example, in Autoware, 97.3% of the protection failure cases in are caused by false positives, and the data is 94.5% for node. This motivates us to adopt the hardware-based technique in the adaptive protection scheme to achieve improved resilience.
Compared with software techniques: Temporal redundancy. Temporal redundancy ceases fault propagation by executing the same piece of autonomous-machine software code twice. Evaluated on Autoware, the temporal redundancy technique can reduce the EPR from 46.5% to 11.7%. Temporal redundancy is not guaranteed to fully mitigate hardware faults as the input to certain nodes can be faulty. Practically, instead of fully duplicating executions, the temporal redundancy scheme can trade off error-detection coverage with less percentage of code duplication for lower overheads, design complexity, and availability.
Compared with hardware techniques: Modular redundancy. By executing identical software code on independent hardware, the fully duplicated system is shown to be effective against soft errors on Autoware. The error-propagation rate of autonomous vehicles can reduce to 0%. However, modular redundancy usually comes with a high extra dollar cost. The main overhead comes from the added silicon area and associated non-recurring engineering, which is expected to increase as autonomous machines increasingly integrate specialized accelerators.
Compared with hardware techniques: Checkpointing. The checkpointing scheme ceases fault propagation by retrieving the saved state, so the application is recovered from the checkpoint and continues from that point on. Combined with modular redundancy as fault detection, the checkpointing protection scheme can reduce the EPR to 0% in Autoware. However, it is to note that checkpointing and restoring procedures greatly increase compute latency that may violate the real-time nature of autonomous machines.
Adaptive protection reduces performance overhead. The proposed VAP paradigm achieves low end-to-end latency and energy overhead by taking the advantage of (1) low cost and false-positive detection rate of software-based protection in front-end kernels and (2) low compute latency of hardware-based protection in back-end kernels.
Specifically, evaluated on Autoware, VAP slightly increases the end-to-end compute latency from 164 to 173, resulting in a 0.05 increase in object avoidance distance. The protection scheme increases the autonomous driving component energy consumption by 4.09%, resulting in a negligible 0.07h operation time reduction. This results from the observation that front-end nodes contribute most compute latency within the end-to-end compute pipeline, but have little to no false positive in the anomaly detection scheme, thus the overhead mainly comes from detection logic. Back-end nodes contribute little to compute latency and have light computation complexity and parameters, resulting in little modular redundancy overhead.
VAP demonstrates lower latency and energy overhead with improved end-to-end performance compared with traditional software-based and hardware-based techniques, as illustrated in Table 2 with detailed breakdown in Table 3.
| Perception | Localization | Planning | Control | Total | |
|---|---|---|---|---|---|
| No Protection | 58 | 69 | 35 | 2 | 164 |
| Anomaly Detection | 64 | 72 | 106 | 3 | 245 |
| Checkpointing | 216 | 256 | 131 | 7 | 610 |
| VAP | 64 | 72 | 35 | 2 | 173 |
Compared with software techniques: Anomaly detection. Anomaly detection brings performance overhead due to the detection algorithm execution and node re-compute once outliers are detected. We apply anomaly detection on multiple ROS nodes in Autoware (Figure 3). The end-to-end compute latency increases from 164 to 245, resulting in a longer object avoidance distance from 5 to 5.47 (9.4% increase). The energy consumption of the system increases by 33.14%, resulting in 0.54 driving time reduction. Since only a piece of code needs to be added to the autonomous vehicle software stack, the extra cost is negligible.
Compared with software techniques: Temporal redundancy. Temporal redundancy introduces performance overhead mainly due to the redundant execution. Executing each software module twice effectively halves the performance. We apply temporal redundancy in Autoware, and the redundant execution almost doubles the compute latency from 164 to 347. Therefore, the vehicle can only proactively plan the route to avoid obstacles at 6.05 away instead of 5. The energy consumption increases by 75.24%, reducing the driving time by 1.12h. The temporal redundancy technique usually only involves extra software code execution with negligible engineering and silicon cost.
Compared with hardware techniques: Modular redundancy. Hardware redundancy usually trades off extra power and cost for performance. We adopt the triple modular redundancy technique as an example, and evaluate it in Autoware. By leveraging three identical main computing modules (CPU + GPU), the end-to-end compute latency is almost unchanged since modern processors usually provide hardware support to minimize the performance overhead of executing on identical hardware copies. However, due to the redundancy of hardware platforms, the autonomous driving system power increases from 175 to 473, reducing the driving time by 2.15h, which can translate to 27.78% daily revenue loss.
Compared with hardware techniques: Checkpointing. Checkpointing usually accompanies dual modular redundancy and brings a large performance overhead due to the store-and-retrieve procedure that may violate the real-time nature of autonomous machines. Checkpointing freezes the process and dumps the application states to the persistent storage, during which the process halts its execution without any progress. Meanwhile, checkpointing needs to be able to create globally consistent checkpoints across the entire application.
We evaluate checkpointing in Autoware. The end-to-end compute latency increases from 164 to 610, mainly due to the overhead of state frozen and restore. This significant latency increase results in a 51.2% longer stop distance, forcing the vehicle to avoid the obstacle 7.56m away. That is usually not tolerable compared to the original performance. The extra checkpointing operations and redundancy increase compute energy consumption by 91.52%, resulting in a 1.32 operation-hour reduction.
Although checkpointing is considered an efficient error-mitigation technique in cloud and database applications, it is not suitable for real-time applications, such as safety-critical autonomous machines, since it introduces latency spikes into the critical path which may result in deadline missing. Furthermore, the checkpointing and restore times scale linearly with the memory size, thus the overhead could be bigger if the autonomy kernels take lots of memory.
Autonomous Drone vs. Vehicle
In this section, we evaluate VAP on autonomous drones and focus on the difference between drone and vehicle systems. We first introduce the unique design constraints of drone systems and then demonstrate the resilience and performance advantages of VAP on drone systems.
Metrics and design constraints of resilient autonomous drones. We use resilience, latency, energy, and cost as evaluation metrics of autonomous drone systems. Different from autonomous vehicles, drones typically have a smaller form factor, thus the extra compute latency and payload weight brought by protection schemes will impact its safe flight velocity, further impacting end-to-end system mission performance. Therefore, we focus on presenting the unique latency and energy requirements of the drone system.
Resilience. We use mission-failure rate as the resilience metric for drones.14 We define a failure case as the drone colliding with obstacles or failing to find a feasible path to the destination within the battery capacity limit. The reason we apply different metrics in autonomous vehicles and drones is that autonomous vehicles and drones face different reliability concerns. Autonomous vehicles face more complicated scenarios on the road. A slight difference in the command to the actuators can lead to a potential crash with other vehicles or pedestrians. Drones, however, work in scenarios with greater freedom. The chance of a crash with obstacles led by a slight trajectory change is rare.
Latency. Compute latency impacts the safe flight velocity of drones and needs to be short enough to ensure flight mission safety. Within the sensor rate and physics limits, as the compute latency becomes longer, the drone must lower its safe flight velocity to ensure enough time to react to obstacles without colliding.
Figure 5(a) shows the relationship between compute latency and maximum safe flight velocity derived from analytical modeling24 and validated in concrete real-world flight tests.19,21 Our drone is equipped with cameras that sense objects within 4.5, and an TX2 as onboard compute to generate high-level flight commands. Our drone has an average compute latency of 871 with 2.79 average flight velocity during an autonomous navigation task. Achieving high safe velocity is crucial as it ensures that the drone is reactive to a dynamic environment and finishes tasks quickly, thereby lowering mission time and energy.20 This latency model allows us to understand how computing latency matters in the autonomous drone system and impacts mission performance.
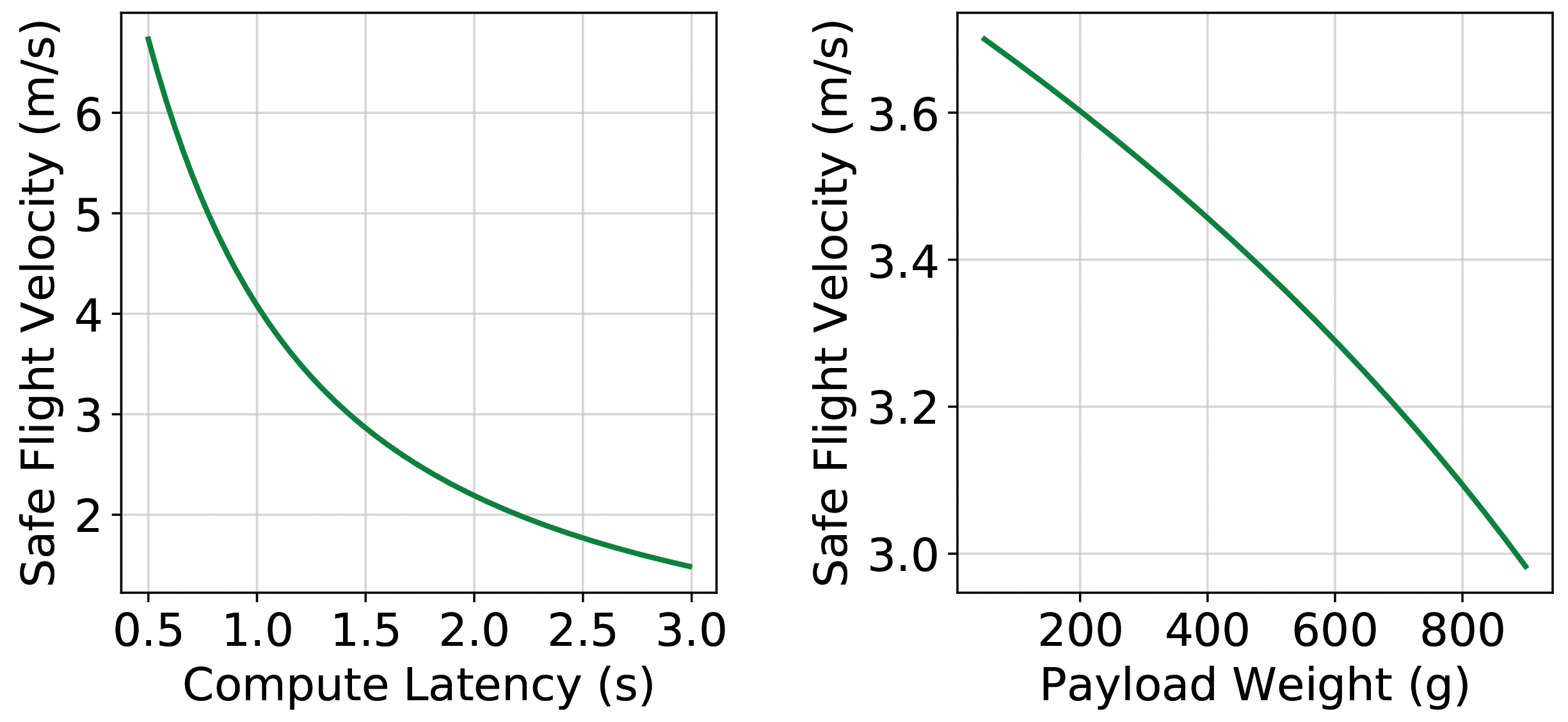
Energy. The drone is severely constrained in terms of size, weight, and power (SWaP). A physics component change (for example, onboard payload) will impact flight performance. Payload weight, such as redundant onboard computers and larger heatsinks, affects a drone’s acceleration, thus lowering its thrust-to-weight ratio and safe flight velocity.
Figure 5(b) illustrates the relationship between drone payload weight and its maximum safe flight velocity on an drone platform. As the drone gets smaller in form factor, its safe velocity would be more sensitive and affected by payload weight due to a decreasing payload-carrying capability.19 Furthermore, flight velocity closely correlates to the flight mission time and energy. Hence, it is essential to understand these effects when designing and evaluating fault-protection schemes for drones.
Resilience and performance evaluation. We evaluate the resilience and performance of VAP on a MAVBench simulator for autonomous drone systems, and demonstrate its advantages over conventional software and hardware “one-size-fits-all” techniques, as illustrated in Table 4 with a detailed breakdown in Table 5.
| Fault Protection Scheme | Latency and Flight Time | Power Consumption and Flight Energy | Cost | Resilience | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Compute Latency () | Avg. Flight Velocity () | Mission Time () | Compute Power () | Mission Energy () | Num. of Missions | Endurance Reduction (%) | Extra Dollar Cost | Mission Failure Rate (%) | ||
| Baseline | No Protection | 871 | 2.79 | 107.53 | 15 | 60.09 | 5.62 | – | – | 12.20 |
| Software | Anomaly Detection | 1201 | 2.51 | 119.52 | 15 | 66.79 | 5.05 | -10.04 | negligible | 6.44 |
| Temporal Redundancy | 1924 | 2.14 | 140.18 | 15 | 78.34 | 4.31 | -23.30 | negligible | 3.02 | |
| Hardware | Modular Redundancy | 871 | 2.74 | 109.49 | 45 | 63.13 | 5.34 | -3.79 | TX22 | 0 |
| Checkpointing | 3458 | 1.75 | 171.43 | 30 | 96.76 | 3.49 | -37.90 | TX21 | 0 | |
Adaptive Protection Design Paradigm Front-end Software + Back end Hardware | 897 | 2.77 | 108.30 | 15 | 60.52 | 5.58 | -0.72 | negligible | 0 | |
| Perception | Localization | Planning | Control | Total | |
|---|---|---|---|---|---|
| No Protection | 632 | 55 | 182 | 2 | 871 |
| Anomaly Detection | 645 | 60 | 493 | 3 | 1201 |
| Checkpointing | 2446 | 214 | 792 | 6 | 3485 |
| VAP | 645 | 60 | 190 | 2 | 897 |
Adaptive protection VAP is cost-effective in a drone system. The proposed VAP exhibits high resilience on a drone system with a small performance overhead. For improved operational safety, notably, VAP can reduce the flight mission failure rate to 0% under soft errors.
For reduced performance overhead, evaluated on a typical autonomous drone system, the adaptive protection slightly increases end-to-end compute latency from 871 to 897. Since false-positive cases are rare for front-end modules, the main overhead of anomaly detection comes from extra detection logic. This slight latency overhead results in a small drop in average flight velocity from 2.79 to 2.77, consequently resulting in mission flight time slightly increasing from 107.53 to 108.30, and mission energy increasing from 60.09 to 60.52 with 0.72% less endurance.
Conventional “one-size-fits-all” techniques bring more performance degradation in small-scale systems. Conventional hardware and software protection techniques incur large compute and end-to-end performance overhead on drone systems. For example, software-based anomaly detection increases the end-to-end compute latency from 871 to 1,201, lowering the average flight velocity from 2.79 to 2.51. This consequently results in 11.15% higher flight energy for the same navigation task, and the number of missions that a drone is capable of finishing is reduced from 5.62 to 5.05.
Notably, since a drone has a limited battery capacity and a smaller form factor compared to vehicles, the compute latency overhead results in greater system performance degradation. For example, software-based temporal redundancy increases the end-to-end compute latency by 2.21 in the worst scenario, which lowers the average flight velocity from 2.79 to 2.14. This results in 30.37% higher flight energy and 23.30% less mission endurance. Hardware-based checkpointing increases end-to-end compute latency by 3.97, lowering the average flight velocity to 1.75 and resulting in 61.02% higher flight energy for the same navigation task. Similarly, extra payload weight have higher impacts on small form factor drones and result in more performance degradation.
Conclusion and Outlook
The advent of autonomous machines has the potential to revolutionize modern society, and the ability of an autonomous machine to tolerate or mitigate errors is essential to ensure its functional safety. For the first time, we systematically analyze the design landscape of protection techniques for resilient autonomous machines and reveal the inherent performance-resilience trade-offs in different kernels of complex autonomous machine computing stacks. We propose an adaptive protection design paradigm, VAP, with front-end software and back-end hardware techniques that demonstrate cost-effectiveness in both large-scale autonomous vehicles and small-scale drone systems. We envision that the observations and design paradigms discussed in this paper will further spur a series of innovations at the algorithm, system, and hardware levels, resulting in increased deployments of intelligent swarms, enhanced autonomy, and highly efficient custom hardware designs for autonomous machine computing.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment