Artificial intelligence (AI) captured the world’s attention in 2023 with the emergence of pre-trained models such as GPT, on which the conversational AI system ChatGPT is based. For the first time, we can converse with an entity, however imperfectly, about anything, as we do with other humans. This new capability provided by pre-trained models has created a paradigm shift in AI, transforming it from an application to a general-purpose technology that is configurable to specific uses. Whereas historically an AI model was trained to do one thing well, it is now usable for a variety of tasks such as general conversations; assistance; decision making; and the generation of documents, code, and video—for which it was not explicitly trained. The scientific history of AI provides a backdrop for evaluating and discussing the capabilities and limitations of this new technology, and the challenges that lie ahead.
Key Insights
Kuhn’s framework of scientific progress helps us understand how artificial intelligence has gone through several paradigm shifts during its scientific history, and how the representation and use of knowledge has widened in scope and scale.
The current general intelligence paradigm has breached a major barrier where machines can learn through self-supervision, transforming AI from an application to a general-purpose technology like electricity that will enable the rapid development of transformative applications across the economy.
Trust is the key barrier in the current AI paradigm, which must be overcome for the widespread adoption of AI.
Whereas historically an AI model was trained to do one thing well, it is now usable for a variety of tasks such as general conversations; assistance; decision making; and the generation of documents, code, and video.
Economics Nobel Laureate Herbert Simon, one of the pioneers of AI who coined the term “artificial intelligence”, described it as a “science of the artificial.”43 In contrast to the natural sciences, which describe the world as it exists, a science of the artificial is driven by a goal, of creating machine intelligence. According to Simon, this made AI a science of design and engineering. Just five decades later, pre-trained models have greatly expanded the design aspirations of AI, from crafting high-performing systems in narrowly specified applications, to becoming general-purpose and without boundaries, applicable to anything involving intelligence.
The evolution of AI can be understood through Kuhn’s theory of scientific progress22 in terms of “paradigm shifts.” While philosophers of science have debated Kuhn’s multiple uses of the term “paradigm” in his original treatise, I use it in a generic sense to signify a set of theories and methods accepted by the community to guide inquiry. It’s a way of thinking favored by the scientific community.
Kuhn describes science as a process involving occasional “revolutions” stemming from crises faced by the dominant theories, followed by periods of “normal science” where the details of the new paradigm are fleshed out. Over time, as the dominant paradigm fails to address an increasing number of important anomalies or challenges, the center of gravity of the field shifts toward a new set of theories and methods—a new way of thinking that better addresses them—even as the old paradigm may co-exist. Indeed, we still use and teach Newtonian physics, despite its breakdown when it comes to subatomic particles or objects traveling at the speed of light.
A key feature of Kuhn’s paradigms that I draw on is that they have “exemplars” that guide problem formulation and solution. In physics, for example, the models describing the laws of motion, like Kepler’s or Newton’s laws of motion, served as exemplars that drove hypothesis formulation, observation, and hypothesis testing. In AI, exemplars define the core principles and methods for knowledge extraction, representation, and use. Early approaches favored methods for declaring human-specified knowledge as rules using symbols to describe the world, and an “inference engine” to manipulate the symbols sequentially—which was viewed as “reasoning.” In contrast, current methods have shifted toward parallel processing of information, and learning more complex statistical representations of the world that are derived almost entirely from data. The latter tend to be better at dealing with the contextual subtleties and complexity we witness in problems involving language, perception, and cognition.
The paradigm shifts in AI have been accompanied by methods that broke through major walls considered significant at the time. The first generation of AI research in the late 1950s and 1960s was dominated by game-playing search algorithms39 that led to novel ways for searching various kinds of graph structures. But this type of mechanical search provided limited insight into intelligence, where real-world knowledge seemed to play a major role in solving problems, such as in medical diagnosis and planning.
The paradigm shifts in AI have been accompanied by methods that broke through major walls considered significant at the time.
Expert systems provided a way forward, by representing domain expertise and intuition in the form of explicit rules and relationships that could be invoked by an inference mechanism. But these systems were hard to create and maintain. A knowledge engineer needed to define each relationship manually and consider how it would be invoked in making inferences.
The practical challenges of the knowledge acquisition bottleneck led to the next paradigm shift. As more data became available, researchers developed learning algorithms that could automatically create rules or models directly from the data using mathematical, statistical, or logical methods, guided by a user-specified objective function.
That is where we are today. Systems such as ChatGPT employ variants of neural networks called transformers that provide the architecture of large language models (LLMs), which are trained directly from the collection of human expression available on the Internet. They use complex mathematical models with billions of parameters estimated from large amounts of publicly available data. Although language has been a key area of advancement in recent years, current-day generative AI algorithms are enabling machines to learn from other modalities of data, including vision, sound, smell, and touch.
What is particularly important today is the shift from building specialized applications of AI to one where knowledge and intelligence do not have specific boundaries, but transfer seamlessly across applications and to novel situations. Even though the question of whether the behaviors and performance of modern AI systems satisfy the Turing Test for intelligence46 is still debated, the debate itself is indicative of the significant progress in AI and the palpable increase in its capability. Chollet8 attempts to unify the narrow “task-specific” and “general-purpose” capabilities of humans into a dual theory of intelligence, arguing that a measure of intelligence should consider how such capabilities are manifested across a wide range of tasks.
What is particularly important today is the shift from building specialized applications of AI to one where knowledge and intelligence do not have specific boundaries.
The Paradigm Shifts in AI
To understand the state of the art of AI and where it is heading, it is important to track its scientific history, especially the bottlenecks that stalled progress in each paradigm and the degree to which they were addressed by each paradigm shift.
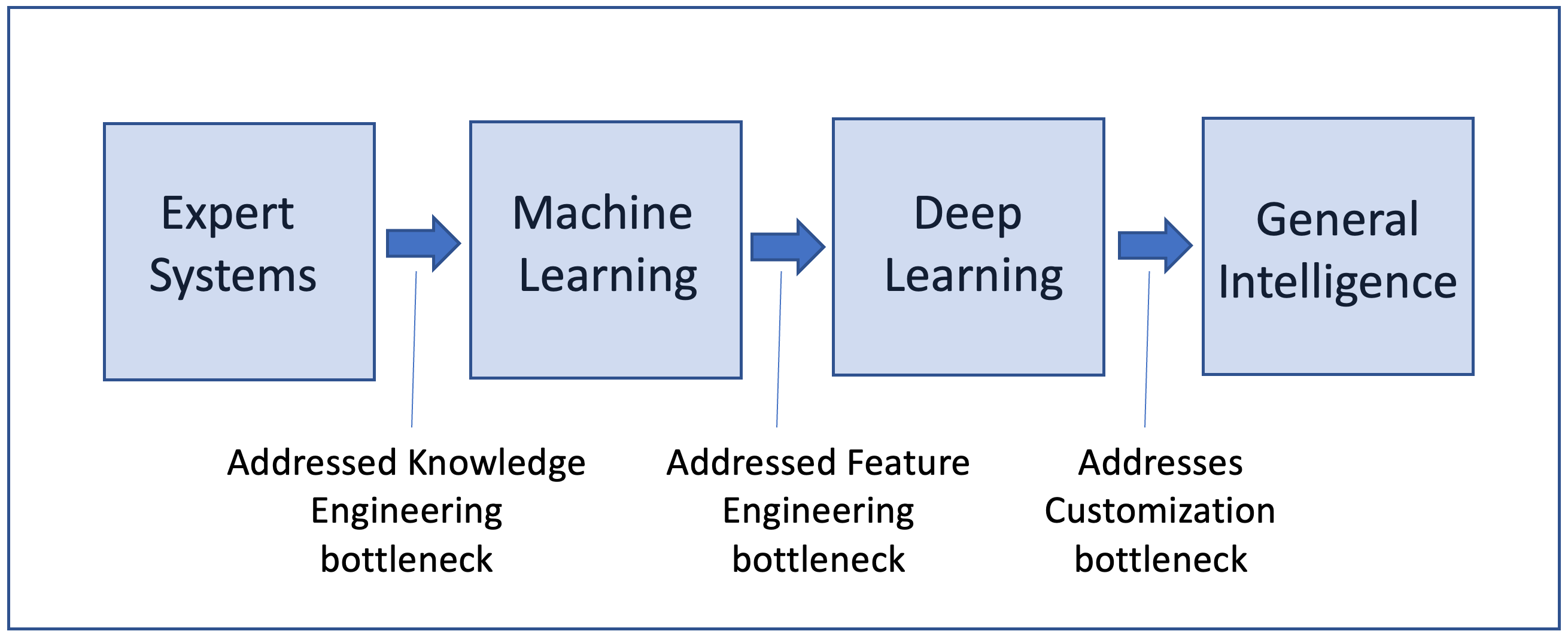
The figure sketches out the history of AI from the expert systems era—which spanned the mid-1960s to the late 1980s—to the present. I do not cover the era of adversarial game-playing algorithms and the emergence of graph-traversal search algorithms such as A*,16 which primarily fall into the realm of optimization and heuristic search on well-specified problems. Indeed, game playing continues to be an active line of inquiry within AI, with the emergence of championship-level algorithms such as AlphaGo and its variants.42 I start with the era of knowledge-based systems, which began to focus on the systematic representation and use of human knowledge at scale.
Expert systems. Expert systems are attractive in well-circumscribed domains in which human expertise is identifiable and definable. They perform well at specific tasks where this expertise can be extracted through interactions with humans, and it is typically represented in terms of relationships among situations and outcomes. AI was applied to diagnosis, planning, and design across a number of domains, including healthcare, science, engineering, and business. The thinking was that if such systems performed at the level of human experts, they were intelligent.
An early successful demonstration of AI in medicine was the Internist system,33 which performed diagnosis in the field of internal medicine. Internist represented expert knowledge using causal graphs and hierarchies relating diseases to symptoms. The rule-based expert system Mycin41 provided another early demonstration of diagnostic reasoning in the narrow domain of blood diseases. Expert systems were also successful in a number of other well-specified domains, such as engineering, mineral prospecting, accounting, tax planning, and configuring computer systems.28
The prototypical exemplar for representing knowledge in this paradigm is via symbolic relationships expressed in the form of “IF/THEN” rules,30 “semantic networks,”35 or structured object representations.29 But it is difficult to express uncertainty in terms of these representations, let alone combine such uncertainties during inference, which prompted the development of more principled graphical models for representing uncertainty in knowledge using probability theory.31
The exemplar in this paradigm was largely shaped by logic and the existing models of cognition from psychology, which viewed humans as having a long-term and a short-term memory, and a mechanism for evoking them in a specific context. The knowledge declared by humans in expert systems, such as the rule “excess bilirubin high pallor” constituted their long-term memory. An attention mechanism, also known as the inference engine or “control regime,” evoked the rules depending on the context, and updated the system’s short-term memory accordingly. If a patient exhibited unusually high pallor, for example, this symptom was noted in short-term memory and the appropriate rule was evoked from long-term memory to hypothesize its cause, such as “excess bilirubin.” In effect, the declaration of knowledge was separate from its application, which was controlled by the attention mechanism.
Research in natural language processing (NLP) was along similar lines, with researchers seeking to discover the rules of language. The expectation was that once these were fully specified, a machine would follow them in order to understand and generate language.40 This turned out to be exceedingly difficult to achieve.
The major hurdle of this paradigm of top-down knowledge specification was the “knowledge engineering bottleneck.” It was challenging to extract reliable knowledge from experts, and equally difficult to represent and combine uncertainty in terms of rules. Collaborations between experts and knowledge engineers could take years or even decades, and the systems became brittle at scale—rules that made sense in isolation often produced unexpected and undesirable results in the presence of many others. Furthermore, researchers found that expert systems would often make errors in common-sense reasoning, which seemed intertwined with specialized knowledge. Evaluating such systems was also difficult, if one ever got to that stage. Human reasoning and language seemed much too complex and heterogenous to be captured by top-down specification of relationships in this paradigm.
Machine learning. The center of gravity of AI began to tilt toward machine learning in the late 1980s and 1990s, with the maturation of database technology, the emergence of the Internet, and the increasing abundance of observational and transactional data.2 AI thinking shifted away from spoon-feeding highly specified human abstractions to the machine and toward automatically learning such relationships from data, guided by human intuition. While symbolic expert systems required humans to specify a model, machine learning (ML) enabled the machine to learn the model automatically from curated examples. Model discovery was guided by a “loss function,” designed to directly or indirectly minimize the system’s overall prediction error, which, by virtue of the available data, could be measured in terms of the differences between predictions and empirical reality. At the same time, research in neural networks grew, to the point that 1987 saw the advent of the first conference dedicated to neural systems called neural information processing systems (NIPS).
Empirics provided the ground truth for supervision of the learning process. For example, to learn how to predict pneumonia, also called the target, one could collect historical medical records of people with and without pneumonia, intuit and engineer the features that might be associated with the target, and let the machine figure out the relationships from the data to minimize the overall prediction error. Instead of trying to specify the rules, the new generation of algorithms could learn them from data using optimization. Many such algorithms emerged, belonging to the broad class of “function approximation” methods that used data and a user-defined objective function to guide knowledge discovery.
This shift in perspective transformed the machine from a rule-follower into a generator and tester of hypotheses that used optimization—via the loss function—to focus knowledge discovery. This ability made machines capable of automated inquiry without a human in the loop. Instead of being a passive repository of knowledge, the machine became an active “what if” explorer, capable of asking and evaluating its own questions. This enabled data-driven scientific discovery, where knowledge was created from data.
The epistemic criterion in ML for something to qualify as knowledge was accurate prediction.11 This criterion conforms to Austro-Hungarian philosopher Karl Popper’s view that the predictive power of theories is a good measure of their strength.34 Popper argued that theories seeking only to explain a phenomenon were weaker than those making ‘bold’ ex ante predictions that were objectively falsifiable. Good theories stood the test of time. In his 1963 treatise on this subject, “Conjectures and Refutations,” Popper characterized Einstein’s theory of relativity as a “good” one, since it made bold predictions that can be falsified easily, yet all attempts at falsification of the theory have failed.
The exemplars for supervised ML are relationships derived from data specified in (X,y) pairs, where “y” is data about the target to be predicted based on a situation described by the set of observable features “X.” The exemplar has a very general form: The discovered relationships can be “IF/THEN” rules, graph structures such as Bayesian networks,31 or implicit mathematical functions expressed via weights in a neural network.18,37 Interestingly, even before the emergence of digital computers, McCulloch and Pitts had shown that neurons with a binary threshold activation function were analogous to first-order logic sentences,27 initiating a stream of research to connect neural networks with rules and symbols that continues to this day.6
Regardless of the representation, the learned knowledge could be viewed as analogous to long-term memory, invoked depending on context, and updatable over time.
But there is no free lunch with machine learning. There is a loss of transparency in what the machine has learned. Neural networks, including LLMs, are particularly opaque; it is difficult to assign meanings to the connections among neurons, let alone combinations of them.
Even more significantly, the ML paradigm introduced a new bottleneck, namely, requiring the curation of the right features from the raw data. For example, to include an MRI image as input into the diagnostic reasoning process, the contents of the image had to be expressed in terms of features such as “inflammation” and “large spots on the liver.” Similarly, a physician’s notes about a case had to be translated into condensed features that the machine could process. This type of feature engineering was cumbersome. Accurately specifying the outcomes or labels could also be costly and time-consuming. These were major bottlenecks for the paradigm.
What was needed was the ability of the machine to deal directly with the raw data emanating from the real world, instead of relying on humans to perform the often-difficult translation of feature engineering. Machines needed to ingest raw data such as numbers, images, notes, or sounds directly, ideally without curation by humans.
Deep learning. The next AI paradigm, now called “deep learning,” made a big dent in the feature engineering bottleneck by providing a solution to perception, such as seeing, reading, and hearing. Instead of requiring humans to describe the world for the machine, this generation of algorithms could consume the raw input similar to what humans use, in the form of images, language, and sound. Deep neural nets (DNNs), which involve multiple stacked layers of neurons, form the foundation of vision and language models.17,25 While learning still involves adjusting the weights between neurons, the “deep” part of the neural architecture is important in translating the raw sensory input automatically into machine-computable data. Advances in hardware for parallel processing (and thus parallel learning) were critical in making DNNs feasible at scale.21
The exemplar in deep learning is a multi-level neural-network architecture. Adjusting the weights between neurons makes it a universal function approximator,10 where the machine can approximate any function, regardless of its complexity, to an acceptable degree of precision. What is novel about DNNs is the organization of hidden layers between the input and output that learn the features implicit in the raw data instead of requiring that they be specified by humans. A vision system, for example, might learn to recognize features common to all images, such as lines, curves, and colors from the raw images that make up its training data. These can be combined variously to make up more complex image parts, such as windows, doors, and street signs that are represented by “downstream” layers of the DNN. In other words, the DNN tends to have an organization, where more abstract concepts that are closer to its output are composed from more basic features represented in the layers that are closer to the input. In a sense, the architecture enables the successive refinement of the input data by implicitly preprocessing it in stages as it passes through the different layers of the neural network to its output.
The same ideas have been applied to LLMs from which systems like ChatGPT are built. LLMs learn the implicit relationships among things in the world from large amounts of text from books, magazines, Web posts, and so on. As in vision, we would expect layers of the neural network that are closer to the output to represent more abstract concepts, relative to layers that are closer to the input. However, we do not currently understand exactly how DNNs organize and use such knowledge, or how they represent relationships in general. This depends on what they are trained to do.
In language modeling, for example, the core training task is to learn to predict the next occurrence of an input sequence. This requires a considerable amount of knowledge and understanding of the relationships among the different parts of the input. LLMs use a special configuration of the transformer neural architecture, which represents language as a contextualized sequence, where context is represented by estimating dependencies between each pair of the input sequence.47 Because this pairwise computation grows sharply with the length of the input, engineering considerations constrain the length of the input sequences—its span of attention, for which LLMs are able to maintain context.
This transformer architecture holds both long-term memory, represented by the connections between neurons, as well as the context of a conversation—the equivalent of short-term memory—using its “attention mechanism,” which captures the relationships among all parts of the input. For example, it can tell what the pronoun “it” refers to in the sentences “The chicken didn’t cross the road because it was wet” and “The chicken didn’t cross the road because it was tired.” While humans find such reasoning easy by invoking common sense, previous paradigms failed at such kinds of tasks that require an understanding of context. The architecture also works remarkably well in vision, where it is able to capture the correlation structure between the various parts of an image. Indeed, pre-trained “diffusion-based” vision models excel at creating very realistic images and videos or fictional ones from language prompts.32,44
The downside is that DNNs are large and complex. What exactly pre-trained language models learn as a by-product of learning sequence prediction is unclear because their knowledge—the meanings and relationships among things—is represented in a “distributed” way, in the form of weighted connections among the layers of neurons. In contrast to Expert Systems, where relationships are specified in “localized” self-contained chunks, the relationships in a DNN are smeared across the weights in the network and much harder to interpret.
Nevertheless, the complexity of the neural network architecture—typically measured by the number of layers and connections in the neural network (its parameters)—is what allows the machine to recognize context and nuance. It is remarkable that the pre-trained LLM can be used to explain why a joke is funny; create, summarize, or interpret a document or image; answer questions; and all kinds of other things it was not explicitly trained to do.
One conjecture for why it succeeded was the serendipitous choice of autocomplete task for prediction, which was just at the right level of difficulty with lots of freely available data, where doing well conversationally forced the machine to learn a large number of other things about the world. In other words, a sufficiently deep understanding about the world, including common sense, is necessary for language fluency. Although current-day machines lag humans in terms of common sense, they are catching up quickly. Earlier versions of ChatGPT failed at the Winograd Schema task,48 which involves resolving an ambiguous pronoun in a sentence. For example, when asked what the “it” refers to in the sentence “the trophy wouldn’t fit into the suitcase because it was too small,” previous versions of ChatGPT asserted that the “it” referred to the trophy. More recent versions of ChatGPT give the proper response, which requires the use of common sense, where meaning cannot be determined by structure alone. Still, AI machines have a way to go before they can seamlessly blend common sense and deep domain knowledge at the human level.
Table 1 summarizes the progression towards general intelligence, as it is defined in the context of the present discussion. The table summarizes each paradigm in terms of four aspects of knowledge we have discussed: how the data is acquired to serve as its knowledge base, the exemplar for representing knowledge and guiding problem formulation, its scope in terms of its knowledge or capability, and the degree of curation of the input. The “+” prefix means “in addition to the previous case.”
| Data | Exemplar | Scope | Curation | |
|---|---|---|---|---|
| Expert Systems | Human | Rules | Follows | High |
| Machine Learning | + Databases | Rules/networks | + Discovers relationships | Medium |
| Deep Learning | + Sensory | Deep neural networks | + Senses relationships | Low |
| General Intelligence | + Everything | Pre-trained deep neural networks | + Understands the world | Minimal |
General intelligence.
Pre-trained models, which integrate a large corpus of general and specialized models not optimized for a single narrow task, are the foundation of the “general intelligence” paradigm. The importance of language as the carrier of knowledge, which powers LLMs, has been critical to the emergence of the current generation of these models, which provide a level of intelligence that is configurable to various applications.
In contrast, previous AI applications were tuned to a task. To predict pneumonia in a hospital, for example, the AI model was trained using cases from that hospital alone, and its performance would not necessarily transfer to use on patients in a nearby hospital, let alone a different country. General intelligence is about the ability to integrate knowledge about pneumonia with other diseases, conditions, geographies, and so on from all available information, and to apply the knowledge to unforeseen situations. More broadly, general intelligence refers to an integrated set of essential mental skills that include verbal ability; reasoning; and spatial, numerical, mechanical, and common-sense and reasoning abilities, which underpin performance across all mental tasks.7 A machine with general intelligence maintains such knowledge in a way that is easily transferrable across tasks and can be applied to novel situations.
Each paradigm shift moved AI closer to general intelligence and greatly expanded the scope of applications of AI. Expert systems structured human knowledge to solve complex problems. Machine learning brought structured databases to life. Deep learning went further, enabling the machine to deal with structured and unstructured data about an application directly from the real world, as humans are able to do. Recent advances in DNNs have made it possible to create entirely new forms of output, previously assumed to be the purview of humans alone. This greatly expands the scope of AI into the creative arena in the arts, science, and business.
Recent advances in DNNs have made it possible to create entirely new forms of output, previously assumed to be the purview of humans alone.
The recent shift to pre-trained models represents a fundamental departure from the previous paradigms, where knowledge was carefully extracted and represented. AI was an application, and tacit knowledge and common-sense reasoning were add-ons that were separate from expertise. The CYC project26 was the first major effort to explicitly teach the machine common sense. It did not work as the designers had hoped. There is too much tacit knowledge and common sense in human interaction that is evoked depending on context, and intelligence is much too complex and heterogenous to be compartmentalized and specified in the form of rules.
In contrast, pre-trained models, such as LLMs that learn through self-supervision on uncurateda data, eschew boundaries, such as those in the pneumonia example. Rather, they integrate specialized and general knowledge, including data about peoples’ experiences across a range of subjects. Much of this type of knowledge became available because of widespread communication on the Internet, where in the short span of a few decades, humanity expressed thousands of years of its history in terms of language and images, along with social media and conversational data on a wide array of subjects. All humans became potential publishers and curators, providing the training data for AI to learn how to communicate fluently.
It is important to appreciate that in learning to communicate in natural language, AI has broken through two fundamental bottlenecks simultaneously. First, we are now able to communicate with machines on our terms rather than through cryptic computer languages and a restricted vocabulary. This required solving a related problem: integrating and transferring knowledge about the world, including common sense, seamlessly into a conversation about any subject. Achieving this capability has required the machine to acquire the various types of knowledge simultaneously—expertise, common sense, and tacit knowledge—all of which are embedded in language. Secondly, now that the machine can understand us, we can communicate with it easily to create new things via language. This ability, where the machine can understand what we are saying well enough to maintain a conversation or create novel outputs for us according to language-based interactions, enables an entirely new kind of capability, enabling the machine to acquire high-quality training data seamlessly “from the wild” in parallel with its operation.
As in deep learning, the exemplar in the general intelligence paradigm is the DNN, whose properties we are now trying to understand, along with the general principles that underpin their performance. One such principle in the area of LLMs is that performance improves by increasing model complexity, data size, and compute power across a wide range of tasks.20 These “scaling laws of AI” show that predictive accuracy on the autocompletion task improves with increased compute power, model complexity, and data. If this measure of performance on autocompletion is a good proxy for general intelligence, the scaling laws predict that LLMs should continue to improve with increases in compute power and data. The more general insight from the new paradigm is that massive parameterization might be necessary for complex generalization.
The “scaling laws of AI” show that predictive accuracy on the autocompletion task improves with increased compute power, model complexity, and data.
At the moment, there are no obvious limits to these dimensions in the development of general intelligence. On the data front, for example, in addition to language data that humans will continue to generate on the Internet, other modalities of data, such as video, are now becoming more widely available. Indeed, a fertile area of research is how machines will integrate data from across multiple sensory modalities, including vision, sound, touch, and smell, just as humans can do. In short, we are in the early innings of the new paradigm, where we should see continued improvement of pre-trained models and general intelligence with increases in the volume and variety of data and computing power. However, this should not distract us from the fact that several fundamental aspects of intelligence are still mysterious and unlikely to be answered solely by making existing models larger and more complex.
A fertile area of research is how machines will integrate data from across multiple sensory modalities, including vision, sound, touch, and smell.
Nevertheless, it is worth noting that the DNN exemplar of general intelligence has been adopted by a number of disciplines, including psychology, neuroscience, linguistics, and philosophy,6,36,45 which seek to explain intelligence. This has arguably made AI more interdisciplinary by unifying its engineering and design principles with these perspectives. Explaining and understanding the behavior of DNNs in terms of a set of core principles of its underlying disciplines is an active area of research in the current paradigm.
It is worth noting that the progression toward general intelligence has followed a path of increasing scope in machine intelligence as shown in the table. The first paradigm was “Learn from humans.” The next one was “Learn from curated data.” This was followed by “Learn from any kind of data.” The current paradigm is “Learn from any kind of data about the world in a way that transfers to novel situations.” This latest paradigm shift transforms AI into a general-purpose technology and a commodity that should keep improving in terms of quality with increasing amounts of data and computing power.
It is also worth noting that tremendous strides have been made in both sensor and servo technologies, which have led to concomitant leaps forward in the field of robotics, including in autonomous vehicles. Indeed, AI will be central to the development of the mobile artificial life that we humans, or “wet life,” create, which could well become a more resilient life form than its biological creator.14
AI as a General-Purpose Technology
Paradigm shifts as defined by Kuhn are followed by periods of “normal science,” where the details of the new paradigm are fleshed out. We are in the early stages of one such period.
Despite their current limitations, pre-trained AI models have unleashed applications in language and vision, ranging from support services that require conversational expertise to creative tasks such as creating documents or videos. As the capability provided by these pre-trained models grows and becomes embedded in a broad range of industries and functions, AI is transitioning from a bespoke set of tools to a “general-purpose technology” from which applications are assembled.
Economists use the term general-purpose technology—of which electricity and the Internet are examples—as a new method for producing and inventing that is important enough to have a protracted aggregate economic impact across the economy.19
Bresnahan and Trachtenburg3 describe general purpose technologies in terms of three defining properties:
Pervasiveness—They are used as inputs by many downstream sectors
Inherent potential for technical improvements
Innovational complementarities—The productivity of R&D in downstream sectors multiplies as a consequence of innovation in the general-purpose technology, creating productivity gains throughout the economy.
How well does the general intelligence paradigm of AI meet these criteria?
Arguably, AI is already pervasive, embedded increasingly in applications without our realization. And with the new high-bandwidth human-machine interfaces enabled by conversational AI, the quality and volume of training data that machines such as ChatGPT can now acquire as they operate is unprecedented. Sensory data from video and other sources will continue to lead to improvements in pre-trained models and their downstream applications.
The last of the three properties, innovation complementarities, may take time to play out at the level of the economy. With previous technologies, such as electricity and IT, growth rates were below those attained in the decades immediately preceding their arrival.19 As Brynolffson et al. explain, substantial complementary investments were required to realize the benefits of general-purpose technologies, where productivity emerges after a significant lag.4 With electricity, for example, it took decades for society to realize its benefits, since motors needed to be replaced, factories needed redesign, and workforces needed to be re-skilled. IT was similar, as was the Internet.
AI is similarly in its early stages, where businesses and governments are scrambling to reorganize processes and rethinking the future of work. Just as electricity required the creation of an electric grid and the redesign of factories, AI will similarly create an “intelligence grid” requiring a redesign of processes to realize productivity gains from this new general-purpose technology.5 Such improvements can take time to play out.
Challenges of the Current Paradigm: Trust and Law
We should not assume we have converged on the “right paradigm” for AI. The current paradigm will undoubtedly accommodate others that address its shortcomings.
Indeed, paradigm shifts do not always improve on previous paradigms in every way, especially in their early stages, and the current paradigm is no exception. New theories often face resistance and challenges initially, while their details are being filled in. For example, the Copernican revolution faced numerous challenges in explaining certain recorded planetary movements that were explained by the existing theory—until new methods and measurements emerged to provide strong support for the new theory.22 Laudan24 also argues that a paradigm is bolstered by its effectiveness to solve those problems deemed to be more important by the scientific community. For example, the deep-learning paradigm is far superior at perception relative to earlier paradigms, although it is poorer in terms of explanation and transparency.
Indeed, despite the current optimism about AI, which has been fueled by its success at prediction, the current paradigm faces serious challenges. One of the biggest challenges society will face as AI permeates different aspects of our lives is one of trust.12 This challenge stems in large part from its representation of knowledge that is opaque to humans. For example, a recent exciting application of AI is in the accurate prediction of protein-folding and function that is essential for drug development and disease intervention. However, the behavior of such machines is still sensitive to how the input—such as a molecule—is represented, and they struggle to explain the underlying mechanisms of action.15 While this is a fertile area of research in the current paradigm, the current opacity of these systems hinders human understanding of the natural world, which places a high premium on explanation and transparency.
One of the biggest challenges society will face as AI permeates different aspects of our lives is one of trust.
Likewise, even though systems such as ChatGPT can be trained on orders of magnitude more cases than a human expert could possibly encounter in a lifetime, their ability to introspect from multiple viewpoints is severely limited relative to humans. A related problem is we can never be sure they are correct, and not “hallucinating,” that is, filling in their knowledge gaps with answers that look credible but are incorrect. It is like talking to someone intelligent whom you cannot always trust.
These problems will need to be addressed if we are to trust AI. Since the data for pre-trained models is not curated, machines pick up on the falsehoods, biases, and noise in their training data. Indeed, LLMs are not explicitly designed to be truthful, even though we implicitly expect them to be correct. Systems using LLMs can also be unpredictable, and systems based on them can exhibit undesirable social behavior that their designers did not intend. While designers might take great care to prohibit undesirable behavior via training using “reinforcement learning via human feedback” (RLHF), such guardrails do not always work as intended. The machine is relatively inscrutable.
Making AI explainable and truthful is a big challenge. At the moment, it is not obvious whether this problem is addressable solely by the existing paradigm.
The unpredictability of AI systems built on pre-trained models also introduces new problems for trust. For example, the output of LLM-based AI systems on the same input can vary, a behavior we associate with humans but not machines.13 To the contrary, we expect machines to be deterministic, not “noisy” or inconsistent like humans. Until now, we have expected consistency from machines.
While we might consider the machine’s variance in decision making as an indication of creativity—a human-like behavior—it poses severe risks, especially given its inscrutability and an uncanny ability to mimic humans. Machines are already able to create “deep fakes” or fictional movies which can be undistinguishable from human creations. We are seeing the emergence of things like AI-generated pornography using real humans, and creations of art, documents, and personas whose basis is hard to identify. Likewise, it is exceedingly difficult to detect plagiarism, or to even define plagiarism or intellectual property theft, given the large corpus of public information on which LLMs have been trained. Existing laws are not designed to address such problems, and they will need to be expanded to recognize and deal with them.
Finally, inscrutability also creates a larger, existential risk to humanity, which could become a crisis for the current paradigm. For example, in trying to achieve goals that we give the AI, such as “save the planet,” we have no idea about the sub-goals the machine will create to achieve its larger goals. Unlike previous AI machines, which were designed for a specific purpose, general intelligence has emerged without such a purpose, which makes it impossible to know whether the actions of systems built on it will match our intentions in a particular situation. This is known as “the alignment problem,” which arises from our inability to determine whether the machine’s hidden goals are aligned with ours. In saving the planet, for example, the AI might determine that humans pose the greatest risk to Earth’s survival due to pollution or nuclear war, and hence they should be contained or eliminated.1,9,38 This is especially concerning if we do not know the data the machine is using to base its decisions, and the credibility of the data used.
So, even as we celebrate AI as a technology that will have far-reaching benefits for humanity—potentially exceeding that of other general-purpose technologies such as electric power and the Internet—trust and alignment remain disconcertingly unaddressed. They are pressing concerns that we must address to avoid a dystopian AI future.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment