Windows Error Reporting (WER) is a distributed system that automates the processing of error reports coming from an installed base of a billion machines. WER has collected billions of error reports in 10 years of operation. It collects error data automatically and classifies errors into buckets, which are used to prioritize developer effort and report fixes to users. WER uses a progressive approach to data collection, which minimizes overhead for most reports yet allows developers to collect detailed information when needed. WER takes advantage of its scale to use error statistics as a tool in debugging; this allows developers to isolate bugs that cannot be found at smaller scale. WER has been designed for efficient operation at large scale: one pair of database servers records all the errors that occur on all Windows computers worldwide.
1. Introduction
Debugging a single program run by a single user on a single computer is a well-understood problem. It may be arduous, but follows general principles: a user reports an error, the programmer attaches a debugger to the running process or a core dump and examines program state to deduce where algorithms or state deviated from desired behavior. When tracking particularly onerous bugs the programmer can resort to restarting and stepping through execution with the user’s data or providing the user with a version of the program instrumented to provide additional diagnostic information. Once the bug has been isolated, the programmer fixes the code and provides an updated program.a
Debugging in the large is harder. As the number of deployed Microsoft Windows and Microsoft Office systems scaled to tens of millions in the late 1990s, our programming teams struggled to scale with the volume and complexity of errors. Strategies that worked in the small, like asking programmers to triage individual error reports, failed. With hundreds of components, it became much harder to isolate the root causes of errors. Worse still, prioritizing error reports from millions of users became arbitrary and ad hoc.
In 1999, we realized we could completely change our model for debugging in the large, by combining two tools then under development into a new service called Windows Error Reporting (WER). The Windows team devised a tool to automatically diagnose a core dump from a system crash to determine the most likely cause of the crash and identify any known resolutions. Separately, the Office team devised a tool to automatically collect a stack trace with a small of subset of heap memory on an application failure and upload this minidump to servers at Microsoft. WER combines these tools to form a new system which automatically generates error reports from application and operating systems failures, reports them to Microsoft, and automatically diagnoses them to point users at possible resolutions and to aid programmers in debugging.
Beyond mere debugging from error reports, WER enables a new form of statistics-based debugging. WER gathers all error reports to a central database. In the large, programmers can mine the error report database to prioritize work, spot trends, and test hypotheses. Programmers use data from WER to prioritize debugging so that they fix the bugs that affect the most users, not just the bugs hit by the loudest customers. WER data also aids in correlating failures to co-located components. For example, WER can identify that a collection of seemingly unrelated crashes all contain the same likely culprit—say a device driver—even though its code was not running at the time of failure.
Three principles account for the use of WER by every Microsoft product team and by over 700 third-party companies to find thousands of bugs: automated error diagnosis and progressive data collection, which enable error processing at global scales, and statistics-based debugging, which harnesses that scale to help programmers more effectively improve system quality.
WER is not the first system to automate the collection of memory dumps. Postmortem debugging has existed since the dawn of digital computing. In 1951, The Whirlwind I system2 dumped the contents of tube memory to a CRT in octal when a program crashed. An automated camera took a snapshot of the CRT on microfilm, delivered for debugging the following morning. Later systems dumped core to disk; used partial core dumps, which excluded shared code, to minimize the dump size5; and eventually used telecommunication networks to deliver core dumps to the computer manufacturer.4
WER is the first system to provide automatic error diagnosis, the first to use progressive data collection to reduce overheads, and the first to automatically direct users to available fixes based on automated error diagnosis. WER remains unique in four aspects:
- WER is the largest automated error-reporting system in existence. Approximately one billion computers run WER client code: every Windows system since Windows XP.
- WER automates the collection of additional client-side data for hard-to-debug problems. When initial error reports provide insufficient data to debug a problem, programmers can request that WER collect more data in future error reports including: broader memory dumps, environment data, log files, and program settings.
- WER automatically directs users to solutions for corrected errors. For example, 47% of kernel crash reports result in a direction to an appropriate software update or work around.
- WER is general purpose. It is used for operating systems and applications, by Microsoft and non-Microsoft programmers. WER collects error reports for crashes, non-fatal assertion failures, hangs, setup failures, abnormal executions, and hardware failures.
2. Problem, Scale, and Strategy
The goal of WER is to allow us to diagnose and correct every software error on every Windows system. We realized early on that scale presented both the primary obstacle and the primary solution to address the goals of WER. If we could remove humans from the critical path and scale the error reporting mechanism to admit millions of error reports, then we could use the law of large numbers to our advantage. For example, we did not need to collect all error reports, just a statistically significant sample. And we did not need to collect complete diagnostic samples for all occurrences of an error with the same root cause, just enough samples to diagnose the problem and suggest correlation. Moreover, once we had enough data to allow us to fix the most frequently occurring errors, then their occurrence would decrease, bringing the remaining errors to the forefront. Finally, even if we made some mistakes, such as incorrectly diagnosing two errors as having the same root cause, once we fixed the first then the occurrences of the second would reappear and dominate future samples.
Realizing the value of scale, five strategies emerged as necessary components to achieving sufficient scale to produce an effective system: automatic bucketing of error reports, collecting data progressively, minimizing human interaction, preserving user privacy, and directing users to solutions.
WER automatically aggregates error reports likely originating from the same bug into a collection called a bucket.b If not, WER data naively collected with no filtering or organization, would absolutely overwhelm programmers. The ideal bucketing algorithm would map all error reports caused by the one bug into one unique bucket with no other bugs in that bucket. Because we know of no such algorithm, WER instead employs a set of bucketing heuristics in two phases. First, errors are labeled, assigned to a first bucket based on immediate evidence available at the client with the goal that each bucket contains error reports from just one bug. Second, errors are classified at the WER service; they are consolidated to new buckets as additional data is analyzed with the goal of minimizing programmer effort by placing error reports from just one bug into just one final bucket.
Bucketing enables automatic diagnosis and progressive data collection. Good bucketing relieves programmers and the system of the burden of processing redundant error reports, helps prioritize programmer effort by bucket prevalence, and can be used to link users to updates when the bugs has been fixed. In WER, bucketing is progressive. As additional data related to an error report is collected, such as symbolic information to translate from an offset in a module to a named function, the report is associated with a new bucket. Although the design of optimal bucketing algorithms remains an open problem, the bucketing algorithms used by WER are in practice quite effective.
 2.2. Progressive data collection
2.2. Progressive data collection
WER uses a progressive data collection strategy to reduce the cost of error reporting so that the system can scale to high volume while providing sufficient detail for debugging. Most error reports consist of no more than a simple bucket identifier, which just increments its count. If additional data is needed, WER will next collect a minidump (an abbreviated stack and memory dump) and the configuration of the faulting system into a compressed cabinet archive file (the CAB file). If data beyond the minidump is required to diagnose the error, WER can progress to collecting full memory dumps, memory dumps from related programs, related files, or additional data queried from the reporting computer. Progressive data collection reduces the scale of incoming data enough that one pair of SQL servers can record every error on every Windows system worldwide. Progressive data collection also reduces the cost to users in time and bandwidth of reporting errors, thus encouraging user participation.
2.3. Minimizing human interaction
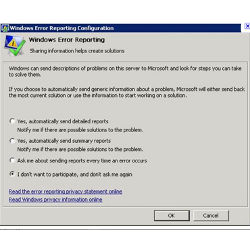
WER removes users from all but the authorization step of error reporting and removes programmers from initial error diagnosis. User interaction is reduced in most cases to a yes/no authorization (see Figure 1). Users may permanently opt in or out of future authorization requests. WER servers analyze each error report automatically to direct users to existing fixes, or, as needed, ask the client to collect additional data. Programmers are notified only after WER determines that a sufficient number of error reports have been collected for an unresolved bug.
We take considerable care to avoid knowingly collecting personal identifying information (PII). This encourages user participation and reduces regulatory burden. For example, although WER collects hardware configuration information, client code zeros serial numbers, and other known unique identifiers to avoid transmitting data that might identify the sending computer. WER operates on an informed consent policy with users. Errors are reported only with user consent. All consent requests default to negative, thus requiring that the user opt-in before transmission. WER reporting can be disabled on a per-error, per-program, or per-computer basis by individual users or by administrators. Because WER does not have sufficient metadata to locate and filter possible PII from collected stack or heap data, we minimize the collection of heap data. Microsoft also enforces data-access policies that restrict the use of WER data strictly to debugging and improving program quality.
2.5. Providing solutions to users
Many errors have known corrections. For example, users running out-of-date software should install the latest service pack. The WER service maintains a mapping from buckets to solutions. A solution is the URL of a web page describing steps a user should take to prevent reoccurrence of the error. Solution URLs can link the user to a page hosting a patch for a specific problem, to an update site where users can get the latest version, or to documentation describing workarounds. Individual solutions can be applied to one or more buckets with a simple regular expression matching mechanism. For example, all users who hit any problem with the original release of Word 2003 are directed to a web page hosting the latest Office 2003 service pack.
3. Bucketing Algorithms
The most important element of WER is its mechanism for automatically assigning error reports to buckets. Conceptually WER bucketing heuristics can be divided along two axes. The first axis describes where the bucketing code runs: heuristics performed on client computers attempt to minimize the load on the WER servers and heuristics performed on servers attempt to minimize the load on programmers. The second axis describes the effect of the heuristic on the number of final buckets presented to programmers from a set of incoming error reports: expanding heuristics increase the number of buckets so that no two bugs are assigned to the same bucket; condensing heuristics decrease the number of buckets so that no two buckets contain error reports from the same bug. Working in concert, expanding and condensing heuristics should move WER toward the desired goal of a one-to-one mapping between bugs and buckets.
When an error report is first generated, the client-side bucketing heuristics attempt to produce a unique bucket label using only local information; ideally a label likely to align with other reports caused by the same bug. The client-side heuristics are important because in most cases, the only data communicated to the WER servers will be a bucket label. An initial label contains the faulting program, module, and offset of the program counter within the module. Additional heuristics apply under special conditions, such as when an error is caused by a hung application. Programs can also apply custom client-side bucketing heuristics through the WER APIs.
Most client-side heuristics are expanding heuristics, intended to spread separate bugs into distinct buckets. For example, the hang_wait_chain heuristic starts from the program’s user-input thread and walks the chain of threads waiting on synchronization objects held by other threads to find the source of the hang. The few client-side condensing heuristics were derived empirically for common cases where a single bug produces many buckets. For example, the unloaded_module heuristic condenses all errors where a module has been unloaded prematurely due to an application reference counting bug.
Errors collected by WER clients are sent to the WER service. The heuristics for server-side bucketing attempt to classify error reports to maximize programmer effectiveness. While the current server-side code base includes over 500 heuristics, the most important heuristics execute in an algorithm that analyzes the memory dump to determine which thread context and stack frame most likely caused the error. The algorithm finds all thread context records in the memory dump. It assigns each stack frame a priority from 0 to 5 based on its increasing likelihood of being a root cause. The frame with the highest priority is selected. Priority 1 is used for core OS components, like the kernel, priority 2 for core device drivers, priority 3 for other OS code like the shell, and priority 4 for most other code. Priority 5, the highest priority, is reserved for frames known to trigger an error, such as a caller of assert. Priority 0, the lowest priority, is reserved for functions known never to be the root cause of an error, such as memcpy, memset, and strcpy.
WER contains a number of server-side heuristics to filter out error reports unlikely to be debuggable, such as applications executing corrupt binaries. Kernel dumps are placed into special buckets if they contain evidence of out-of-date device drivers, drivers known to corrupt the kernel heap, or hardware known to cause memory or computation errors.
4. Statistics-Based Debugging
Perhaps the most important feature enabled by WER is statistics-based debugging. With data from a sufficient percentage of all errors that occur on Windows systems worldwide, programmers can mine the WER database to prioritize debugging effort, find hidden causes, test root cause hypotheses, measure deployment of solutions, and monitor for regressions. The amount of data in the WER database is enormous, yielding opportunity for creative and useful queries.
Programmers sort their buckets and prioritize debugging effort on the buckets with largest volumes of error reports, thus helping the most users per unit of work. Often, programmers will aggregate error counts by function and then work through the buckets for the function in order of decreasing bucket count. This strategy tends to be effective as errors at different locations in the same function often have the same root cause.
The WER database can help find root causes which are not immediately obvious from memory dumps. For example, in one instance we received a large number of error reports with invalid pointer usage in the Windows event tracing infrastructure. An analysis of the error reports revealed that 96% of the faulting computers were running a specific third-party device driver. With well below 96% market share (based on all other error reports), we approached the vendor who found a memory corruption bug in their code. By comparing expected versus occurring frequency distributions, we similarly have found hidden causes from specific combinations of third-party drivers and from buggy hardware. A similar strategy is “stack sampling” in which error reports for similar buckets are sampled to determine which functions, other than the first target, occur frequently on the thread stacks.
WER can help test programmer hypotheses about the root causes of errors. The basic strategy is to construct a test function that can evaluate a hypothesis on a memory dump, and then apply it to thousands of memory dumps in the WER database to verify that the hypothesis is not violated. For example, a Windows programmer debugging an error related to a shared lock in the Windows I/O subsystem constructed a query to extract the current holder of the lock from a memory dump and then ran the expression across 10,000 memory dumps to see how many reports had the same lock holder. One outcome of the analysis was a bug fix; another was the creation of a new server-side heuristic.
The WER database can measure how widely a software update has been deployed. Deployment can be measured by absence, measuring the decrease in error reports fixed by the software update. Deployment can also be measured by an increased presence of the new program or module version in error reports for other issues.
The WER database can be used to monitor for regressions. Similar to the strategies for measuring deployment, we look at error report volumes over time to determine if a software fix had the desired effect of reducing errors. We also look at error report volumes around major software releases to quickly identify and resolve new errors that may appear with the new release.
5. Evaluation and Impact
WER collected its first million error reports within 8 months of its deployment in 1999. Since then, WER has collected billions more. The WER service employs approximately 60 servers provisioned to process well over 100 million error reports per day. From January 2003 to January 2009, the number of error reports processed by WER grew by a factor of 30.
The WER service is over provisioned to accommodate globally correlated events. For example, in February 2007, users of Windows Vista were attacked by the Renos Malware. If installed on a client, Renos caused the Windows GUI shell, explorer.exe, to crash when it tried to draw the desktop. A user’s experience of a Renos infection was a continuous loop in which the shell started, crashed, and restarted. While a Renos-infected system was useless to a user, the system booted far enough to allow reporting the error to WER—on computers where automatic error reporting was enabled—and to receive updates from Windows Update (WU).
As Figure 2 shows, the number of error reports from systems infected with Renos rapidly climbed from 0 to almost 1.2 million per day. On February 27, shown in black in the graph, Microsoft released a Windows Defender signature for the Renos infection via WU. Within 3 days enough systems had received the new signature to drop reports to under 100,000 per day. Reports for the original Renos variant became insignificant by the end of March. The number of computers reporting errors was relatively small: a single computer (somehow) reported 27,000 errors, but stopped after being automatically updated.
WER augments, but does not replace, other methods for improving software quality. We continue to apply static analysis and model-checking tools to find errors early in the development process.1 These tools are followed by extensive testing regimes before releasing software to users. WER helps us to rank all bugs and to find bugs not exposed through other techniques. The Windows Vista programmers fixed 5000 bugs found by WER in beta deployments after extensive static analysis, but before product release.
Compared to errors reported directly by humans, WER reports are more useful to programmers. Analyzing data sets from Windows, SQL, Excel, Outlook, PowerPoint, Word, and Internet Explorer, we found that a bug reported by WER is 4.55.1 times more likely to be fixed than a bug reported directly by a human. This is because error reports from WER document internal computation state whereas error reports from humans document external symptoms.
Given finite programmer resources, WER helps focus effort on the bugs that have the biggest impact on the most users. Our experience across many application and OS releases is that error reports follow a Pareto distribution with a small number of bugs accounting for most error reports. As an example, the graphs in Figure 3 plot the relative occurrence and cumulative distribution functions (CDFs) for the top 20 buckets of programs from the Microsoft Office 2010 internal technical preview (ITP). The top 20 bugs account for 30%50% of all error reports. The goal of the ITP was to find and fix as many bugs as possible using WER before releasing a technical preview to customers. These graphs capture the team’s progress just 3 weeks into the ITP. The ITP had been installed by 9000 internal users, error reports had been collected, and the programmers had already fixed bugs responsible for over 22% of the error reports. The team would work for another 3 weeks collecting error reports and fixing bugs, before releasing a technical preview to customers.
An informal historical analysis indicates that WER has helped improve the quality of many classes of third-party kernel code for Windows. Figure 4 plots the frequency of system crashes for various classes of kernel drivers for systems running Windows XP in March 2004, March 2005, and March 2006, normalized against system crashes caused by hardware failures in the same period. Assuming that the expected frequency of hardware failures remained roughly constant over that time period (something we cannot yet prove), the number of system crashes for kernel drivers has gone down every year except for two classes of drivers: anti-virus and storage.
As software providers begin to use WER more proactively, their error report incidences decline dramatically. For example, in May 2007, one kernel-mode driver vendor began to use WER for the first time. In 30 days the vendor addressed the top 20 reported issues for their code. Within 5 months, as WER directed users to pick up fixes, the percentage of all kernel crashes attributed to the vendor dropped from 7.6% to 3.8%.
We know of two forms of weakness in the WER bucketing heuristics: weaknesses in the condensing heuristics, which result in mapping reports from a bug into too many buckets, and weaknesses in the expanding heuristics, which result in mapping more than one bug into the same bucket. An analysis of error reports from the Microsoft Office 2010 ITP shows that as many as 37% of these errors reports may be incorrectly bucketed due to poor condensing heuristics. An analysis of all kernel crashes collected in 2008 shows that as many as 14% of these error reports were incorrectly bucketed due to poor expanding heuristics.
While not ideal, WER’s bucketing heuristics are in practice effective in identifying and quantifying the occurrence of errors caused by bugs in both software and hardware. In 2007, WER began receiving crash reports from computers with a particular processor. The error reports were easily bucketed based on an increase in system machine checks and processor type. When Microsoft approached the processor vendor, the vendor had already discovered and documented externally the processor issue, but had no idea it could occur so frequently until presented with WER data. The vendor immediately released a microcode fix via WU—on day 10, the black bar in Figure 5—and within 2 days, the number of error reports had dropped to just 20% of peak.
6. Conclusion
WER has changed the process of software development at Microsoft. Development has become more empirical, more immediate, and more user-focused. Microsoft teams use WER to catch bugs after release, but perhaps as importantly, we use WER during internal and beta pre-release deployments. While WER does not make debugging in the small significantly easier (other than perhaps providing programmers with better analysis of core dumps), WER has enabled a new class of debugging in the large. The statistics collected by WER help us to prioritize valued programmer resources, understand error trends, and find correlated errors.
WER’s progressive data collection strategy means that programmers get the data they need to debug issues, in the large and in the small, while minimizing the cost of data collection to users. Automated error analysis ensures programmers are not distracted with previously diagnosed errors. It also ensures that users are made aware of fixes that can immediately improve their computing experience. As applied to WER, the law of large numbers says that we will eventually collect sufficient data to diagnose even rare Heisenbugs3; WER has already helped identify such bugs dating back to the original Windows NT kernel.
WER is the first system to provide users with an end-to-end solution for reporting and recovering from errors. WER provides programmers with real-time data about errors actually experienced by users and provides them with an incomparable billion-computer feedback loop to improve software quality.
Figures
 Figure 1. Typical WER authorization dialog.
Figure 1. Typical WER authorization dialog.
 Figure 2. Renos Malware: Number of error reports per day. Black bar shows when a fix was released through WU.
Figure 2. Renos Malware: Number of error reports per day. Black bar shows when a fix was released through WU.
 Figure 3. Relative number of reports per bucket and CDF for top 20 buckets from Office 2010 ITP. Black bars are buckets for bugs fixed in three-week sample period.
Figure 3. Relative number of reports per bucket and CDF for top 20 buckets from Office 2010 ITP. Black bars are buckets for bugs fixed in three-week sample period.
 Figure 4. Crashes by driver class normalized to hardware failures for same period.
Figure 4. Crashes by driver class normalized to hardware failures for same period.
 Figure 5. Crashes/day for a firmware bug. Patch was released via Wu on day 10.
Figure 5. Crashes/day for a firmware bug. Patch was released via Wu on day 10.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Join the Discussion (0)
Become a Member or Sign In to Post a Comment