Swift is a new, principled approach to building Web applications that are secure by construction. Modern Web applications typically implement some functionality as client-side JavaScript code, for improved interactivity. Moving code and data to the client can create security vulnerabilities, but currently there are no good methods for deciding when it is secure to do so.
Swift automatically partitions application code while providing assurance that the resulting placement is secure and efficient. Application code is written as Java-like code annotated with information flow policies that specify the confidentiality and integrity of Web application information. The compiler uses these policies to automatically partition the program into JavaScript code running in the client browser and Java code running on the server. To improve interactive performance, code and data are placed on the client. However, security-critical code and data are always placed on the server. The compiler may also automatically replicate code across the client and server, to obtain both security and performance.
1. Introduction
Web applications are client-server applications in which a Web browser provides the user interface. They are a critical part of our infrastructure, used for banking and financial management, email, online shopping and auctions, social networking, and much more. The security of information manipulated by these systems is crucial, and yet these systems are not being implemented with adequate security assurance. Indeed, 69% of all Internet vulnerabilities are said to be related to Web applications.20 The problem is that with current implementation methods, it is difficult to know whether an application adequately enforces the confidentiality or integrity of the information it manipulates.
Recent trends in Web application design have exacerbated the security problem. To provide a rich, responsive user interface, application functionality is moving into client-side JavaScript6 code that executes within the Web browser. JavaScript code is able to manipulate user interface components and can store information persistently on the client side by encoding it as cookies. These Web applications are distributed applications, in which client- and server-side code exchange protocol messages represented as HTTP requests and responses. In addition, most browsers allow JavaScript code to issue its own HTTP requests, a functionality used in the Ajax development approach (Asynchronous JavaScript and XML).
With application code and data split across differently trusted tiers, the developer faces a difficult question: when is it secure to place code and data on the client? All things being equal, the developer would usually prefer to run code and store data on the client, avoiding server load and client-server communication latency. But moving information or computation to the client can easily create security vulnerabilities.
For example, suppose we want to implement a simple Web application in which the user has three chances to guess a secret number between 1 and 10, and wins if a guess is correct. Even this simple application has subtleties. There is a confidentiality requirement: the user should not learn the secret until after the guesses are complete. There are integrity requirements, too: the comparison of the guess and the secret should be computed in a trustworthy way, and the number of guesses must also be counted correctly.
The guessing application could be implemented almost entirely as client-side JavaScript code, which would make the user interface very responsive and would offload the most work from the server. But it would be insecure: a client with a modified browser could peek at the true number, take extra guesses, or simply lie about whether a guess was correct. On the other hand, suppose guesses that are not valid numbers between 1 and 10 do not count against the user. Then it is secure and indeed preferable to perform the bounds check on the client side. Currently, Web application developers lack principled ways to make decisions about where code and data can be securely placed.
The Swift system is a new way to write Web applications that are secure by construction. Applications are written in a higher-level programming language in which information security requirements are explicitly exposed as declarative annotations. The compiler uses these security annotations to decide where code and data in the system can be placed securely. Developing programs in this way ensures that the resulting distributed application protects the confidentiality and integrity of information. The general enforcement of information integrity also guards against common vulnerabilities such as SQL injection and cross-site scripting.
Swift applications are not only more secure, they are also easier to write: control and data do not need to be explicitly transferred between client and server through the awkward extra-linguistic mechanism of HTTP requests. Automatic placement has a performance benefit as well. Currently, programmers have no help deciding how to place code and data in the system for best interactive performance. In Swift, the compiler automatically places code and data to optimize interactive performance, subject to security constraints, and automatically synthesizes secure protocols where communication is required.
Of course, others have noticed that Web applications are hard to make secure and awkward to write. Prior research has addressed security and expressiveness separately. One line of work has tried to make Web applications more secure, through analysis10, 12, 22 or monitoring9, 16, 23 of server-side application code. However, this work does not help application developers decide when code and data can be placed on the client. Conversely, the awkwardness of programming Web applications has motivated a second line of work toward a unified language for writing distributed Web applications.5, 8, 19, 24 However, this work largely ignores security; the programmer controls code placement, but nothing ensures the placement is secure.
Swift differs by addressing security and expressiveness together. One novel feature illustrating this is its selective replication of computation and data onto both the client and server. Replication is useful for validation of form inputs, which should happen on the client so the user does not have to wait for the server to respond to invalid inputs, but must also happen on the server because client-side validation is untrusted. With Swift, programmers write validation code only once. Compared to the current practice in which developers write separate, possibly inconsistent validation code for the client and server, Swift improves both security and expressiveness.
An earlier publication3 is a good source for further details about Swift, especially regarding the run-time system and optimization techniques.
2. Architecture
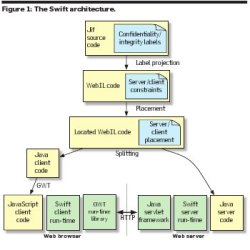
Figure 1 depicts the architecture of Swift. The programmer writes annotated Java source code, shown at the top of the diagram. Proceeding from top to bottom, a series of program transformations converts the code into the partitioned form shown at the bottom, with Java code running on the Web server and JavaScript code running on the client Web browser.
The source language of the program is an extended version of the Jif 3.0 programming language.13, 15 Jif extends the Java programming language with language-based mechanisms for information flow control and access control. Information security policies can be expressed directly within Jif programs, as labels on program variables. By statically checking a program, the Jif compiler ensures that these labels are consistent with flows of information in the program.
The original model of Jif security is that if a program passes compile-time static checking, and the program runs on a trustworthy platform, then the program will enforce the information security policies expressed as labels. For Swift, we assume that the Web server can be trusted, but the client machine and browser may be buggy or malicious. Therefore, Swift transforms program code so that the application runs securely, even though it runs partly on the untrusted client.
The first phase of program transformation converts Jif programs into code in an intermediate language we call WebIL. Like Jif, WebIL includes annotations, but the space of allowed annotations is much simpler, describing constraints on the possible locations of application code and data. For example, the annotation S means that the annotated code or data must be placed on the Web server. The annotation C?S means that it must be placed on the server, and may optionally be replicated on the client as well. It is convenient to program directly in WebIL, but this does not enforce secure information flow.
 2.3. Placement and optimization
2.3. Placement and optimization
The initial WebIL annotations are merely constraints on code and data placement. The second phase of compilation decides the exact placement and replication of code and data between the client and server, in accordance with these constraints. The system uses a polynomial-time algorithm to minimize the cost of the placement, by avoiding unnecessary network messages.
Once code and data placements have been determined, the compiler transforms the WebIL code into two Java programs, one representing server-side computation and the other, client-side computation. This is a fine-grained transformation. Different statements within the same method may run variously on the server and the client, and similarly with different fields of the same object. Sequential statements in the program source code may become separate code fragments on the client and server that invoke each other via network messages.
The compiler generates Java code to run on the client. This code is compiled to JavaScript code using the Google Web Toolkit (GWT).8 The client- and server-side code uses various libraries: Swift’s run-time libraries, GWT, and the Java servlet framework.
A running Swift program uses an Ajax approach to securely implement the functionality defined by the original source code. From the browser’s perspective, the application is a single Web page, with most user actions, such as clicking on buttons, handled by JavaScript code. This code issues its own HTTP or HTTPS requests to the Web server, which executes Java code to compute XML responses.
In order to enforce the security requirements in the Jif source code, information flows between the client and the server must be strictly controlled. In particular, confidential information must not be sent to the client, and information received from the client cannot be trusted. The Swift compilation process generates code that satisfies these constraints. These constraints are also enforced by the Swift run-time system, which ensures that information coming from the client is never trusted.
3. Writing Swift Applications
Programming with Swift starts with a program written in the Jif programming language.13, 15 A little background on Jif will therefore be helpful.
In Jif programs, information security requirements are expressed using labels from the decentralized label model (DLM).14 A label is a set of policies expressed in terms of principals. For example, the confidentiality policy alice→bob says that principal alice owns the labeled information but permits principal bob to read it. Similarly, the integrity policy alice←bob means that alice permits bob to affect the labeled information.
Labels can be attached to types, making Jif a security-typed language. For example, the following declaration uses a label containing two policies separated by a semicolon:
int {alice → bob,alice; bob ← alice} y;
It means that the information in y is considered sensitive by alice, who wants to restrict its release only to bob and alice; and further that it is considered trustworthy by bob, who wants to permit only alice to affect it.
The Jif compiler uses labels to statically check that information flows within Jif code are secure. For example, consider the following code fragment (using the same variable y):
int {alice}→bob x = y
This code causes information to flow from y to x. For the code to be secure, the label on x must restrict the use of data in x at least as much as the label on y restricts the use of y. This is true if (1) for every confidentiality policy on y, there is one at least as restrictive on x (which is the case because alice→bob is at least as restrictive as alice→bob,alice) and (2) for every integrity policy on x, there is one at least as restrictive on y (which is the case because x has no integrity policy).
Suppose that x instead had the label {alice→client}. The information flow from y to x would still be secure if the principal client acts for the principal bob, meaning that anything client does or says can be treated as coming from bob. In that case, alice→client is at least as restrictive as alice→bob. Acts-for relationships increase the expressive power of labels and allow static information flow checking to work even when trust relationships change over time.
Two principals are already built into Swift programs. The principal * (a.k.a. server) represents the maximally trusted principal in the system. The principal client represents the other end of the current-session—in ordinary, nonmalicious use, a Web browser under the control of a user. When reasoning about security, we can only assume that the client is the other end of a network connection, possibly controlled by a malicious attacker. Because the server is trusted, the principal * acts for client. The client may see information whose confidentiality is no greater than *→client, and can produce information with integrity no greater than *←client.
Labels defined in terms of principals are a key feature of the DLM. Because labels keep track of whose security is being enforced, they are useful for systems such as Web applications, where principals need to cooperate despite mutual distrust. By expressing labels in terms of principals, the DLM also enables connections between policies for information flow (labels), policies for trust and authorization (acts-for relationships), and processes for authentication. These connections are all important for Swift.
A Swift program may use and even create additional principals, for example, to represent different users of a Web application. For a user to log in as principal bob, server-side application code marked as trusted by bob must authenticate the user, establishing that the principal named by client acts for bob. Requests from that browser are then treated as coming from bob, and information readable by bob can be sent there. All this can be accomplished within the Jif programming model.
The key features of the Swift programming model can be seen in a simple Swift Web application. Figure 2 shows fragments of the source code for the number-guessing Web application described in Section 1. Java programmers may recognize this Jif code as similar to that of an ordinary single-machine Java application with a user interface dynamically constructed out of widgets such as buttons, text inputs, and text labels. Swift widgets are similar to those in the GWT,8 communicating via events and listeners. The key difference is that Swift controls how information flows through widgets.
The core application logic is found in the makeGuess method (lines 1539). Other than security label annotations, this is essentially straight-line Java code. To implement the same functionality with technologies such as JSP2 or GWT requires more code, in a less natural programming style with explicit control transfers between the client and server.
The code contains various labels expressing security requirements; for simplicity, only the principals client and * are used in these labels. For example, on line 3, the variable secret is declared to be completely secret (*→*) and completely trusted (*←*); the variable tries on the next line is not secret (*→client) but is just as trusted. Because Jif checks transitively how information flows within the application, the act of writing just these two label annotations constrains many other label annotations in the program. The compiler ensures that all label annotations are consistent with the information flows in the program.
The user submits a guess by clicking the button. A listener attached to the button passes the guess at line 50 to makeGuess. The listener reads the guess from a Number TextBox widget that only allows numbers to be entered.
The makeGuess method receives a guess num from the client. The variable num is untrusted and not secret, as shown by its label {*→client} on line 15. The label after the method name, also {*→client}, is the begin label of the method. It controls information flows created by the fact that the method was invoked.
The code of makeGuess checks whether the guess is correct, and either informs the user that he has won, or else decrements the remaining allowed guesses and repeats. Because the guess is untrusted, Jif will prevent it from affecting trusted variables such as tries, unless it is explicitly endorsed by trusted code. Therefore, lines 2137 have a checked endorsement that succeeds only if num contains an integer between 1 and 10. If the check succeeds, the number i is treated as a high-integrity value within the “then” clause. If the check fails, the value of i is not endorsed, and the “else” clause is executed. Checked endorsements are a Swift-specific extension to Jif that makes validating untrusted inputs both explicit and convenient.
Forcing the programmer to use endorse exposes a potential security vulnerability. In this case, the endorsement of i is reasonable because it is intrinsically part of the game that the client is allowed to pick any value in range.
Similarly, some information about the secret value secret is released when the client is notified whether the guess i is equal to secret. Therefore, the bodies of both the consequent and the alternative of the if test on line 23 must use an explicit declassify to indicate that information transmitted by the control flow of the program may be released to the client. Without the declassify, client-visible events—showing messages or updating the variable tries—would be rejected by the compiler.
The declassify and endorse operations are inherently dangerous. Jif controls the use of declassify and endorse by requiring that they occur in a code marked as trusted by the affected principals; hence the clauses authority (*) and endorse ({*←*}) on line 16. The latter, auto-endorse annotation means that an invocation of makeGuess is treated as trusted even if it comes from the client. Jif also requires integrity to perform declassification, enforcing robust declassification4: untrusted information cannot even affect security-critical release of information.
3.3. Swift user interface framework
Swift programs interact with the user via a user interface framework that abstracts away the details of the underlying HTML and JavaScript. Swift programming has a event-driven style familiar to users of UI frameworks such as Swing.
To allow precise compile-time reasoning about information flows within the user interface framework, all framework classes are annotated with security policies that track information flow that may occur within the framework. The framework ensures that the client is permitted to view all information that the user interface displays. Conversely, all information received from the user interface is annotated as having been tainted by the client.
4. WebIL
After the Swift compiler has checked information flows in the Jif program, the program is translated to an intermediate language, WebIL. WebIL extends Java with placement annotations for both code and data. Placement annotations define constraints on where code and data may be replicated. These constraints may be due to security restrictions derived from the Jif code, or to architectural restrictions (for example, calls to a database must occur on the server, and calls to the UI must occur on the client).
Whereas Jif allows expression and enforcement of rich security policies from the DLM,14 the WebIL language is concerned only with the placement of code and data onto two host machines, the server and the client. Thus, when translating to WebIL, the compiler projects annotations from the rich space of DLM security policies down to the much smaller space of placement constraints.
Using the placement constraint annotations, the compiler chooses a partitioning of the WebIL code. A partitioning is an assignment of every statement and field to a host machine or machines on which the statement will execute, or on which the field will be replicated.
WebIL can be used as a source language in its own right, allowing programmers to develop Web applications in a Java-like programming language with GUI support. This approach has benefits over traditional Web application programming, but does not enforce security as fully as Swift.
Each statement and field declaration in WebIL has one of nine possible placement annotations, shown in Table 1: C,S,Sh,C?Sh,C?S?,CS,CS?,C?S, and CSh. Each annotation defines the possible placements for the field or statement. There are three possible placements: client, server, and both. The intuition is that C and S mean the statement or field must be placed on the client and server, respectively, whereas C? and S? mean it is optional. An h signifies high integrity. Figure 3 shows the result of translating Guess-a-Number into WebIL, including placement constraints.
The placement of a field declaration indicates which host or hosts the field data is replicated onto. For example, if a field has the placement server, that field is stored only on the server; if it has the placement both, it is replicated on both client and server.
Similarly, the placement of a statement indicates what machines its computation is replicated onto. For compound statements such as conditionals and loops, the placement indicates the hosts for evaluating the test expression. On line 11 of Figure 3, the comparison of the guess to the secret number is given the annotation Sh, meaning that it must occur only on the server. Intuitively, this is the expected placement: the secret number cannot be sent to the client, so the comparison must occur on the server. On line 3, the annotation C?S? indicates that there is no constraint on where to test that num is non-null; that test may occur on the client, server, or both.
On statements, the annotations Sh, C?Sh, and CSh mark high-integrity code that must be executed on the server. The Swift compiler marks statements as high-integrity if their execution may affect data that the client should not be able to influence. For example, lines 514 of Figure 3 are high-integrity. The client’s ability to initiate execution of high-integrity statements is restricted by Swift run-time mechanisms.
4.2. Translation from Jif to WebIL
When the compiler translates from Jif to WebIL code, it replaces DLM security policies with corresponding placement constraint annotations. Based on the security policies of the Jif code, the compiler chooses annotations that ensure code and data are placed on the client only if the client cannot violate the security of the program.
Therefore, translation ensures that data may be placed on a client only if the security policies indicate that the data may be read by the principal client; data may originate from the client only if the security policies indicate that the data is permitted to be written by the principal client. Similar restrictions apply to code: code may execute on the client only if the execution of the code reveals only information that the principal client may learn; the result of a computation on the client can be used on the server only if the labels indicate that the result can be affected by the principal client.
The translation to WebIL also translates Jif-specific language features. Uses of the primitive Jif type label are translated to uses of a class jif.lang.Label. Declassifications and endorsements are removed, as they have no effect on the run-time behavior of the program. However, they do affect the labels of code and expressions, and therefore affect their placement annotations.
The compiler decides the partitioning by choosing a placement for every field and statement of the WebIL program. Placements are chosen to satisfy both the placement constraints and to improve performance. Since network latency is typically the most significant component of Web application run time, fields and statements are placed in order to minimize latency arising from messages sent between the client and server. For example, it is desirable to give consecutive statements the same placement.
Replicating computation can also reduce the number of messages. Consider lines 58 of the Guess-a-Number application in Figure 3, which check that the user’s input i is between 1 and 10 inclusive. To securely check that the client provides valid input, these statements must execute on the server. If the value entered by the user is not in the valid range, the server sends a message to the client to execute line 25, informing the user of the error. However, if lines 58 execute on both the client and server, no server client message is needed, and the user interface is more responsive.
Figure 4 shows the GuessANumber.makeGuess method after partitioning. A placement has been chosen for each statement. The field tries has been replicated on both client and server, requiring all assignments to it to occur on both hosts (lines 14 and 17). Also, the compiler has replicated on both client and server the validation code to check that the user’s guess is between 1 and 10 (lines 28). The validation code must be on the server for security, but placing it on the client allows the user to be informed of errors (on line 25) without waiting for a server response.
The compiler chooses placements for statements and fields in two stages. First, it constructs a weighted directed graph that approximates the control flow of the whole program. Each node in the graph is a statement, and weights on the edges are static approximations of the frequency of execution following that edge. Second, the weighted directed graph and the annotations of the statements and field declarations are used to construct an instance of an integer programming problem, which is then reduced to an instance of the maximum flow problem. This can be solved in polynomial time, directly yielding fields and statement placements.
5. Evaluation
The Swift compiler extends the Jif compiler with about 20,000 lines of noncomment nonblank lines of Java code. Both the Swift and Jif compilers are written using the Polyglot compiler framework.17 The Swift server and client run-time systems together comprise about 2,600 lines of Java code. The UI framework is implemented in 1,400 lines of WebIL code and an additional 560 lines of Java code that adapt the GWT UI library. We also ported the Jif run-time system from Java to WebIL, resulting in about 3,900 lines of WebIL code. The Jif run-time system provides support for run-time representations of labels and principals.
To evaluate our system, we implemented six Web applications with varying characteristics. None of these applications is large, but because they test the functionality of Swift in different ways, they suggest that Swift will work for a wide variety of Web applications. Because the applications are written in a higher-level language than is usual for Web applications, they provide much functionality (and contain many security issues) per line of code. Overall, the performance of these Web applications is comparable to what can be obtained by writing applications by hand. Therefore, we do not see any barrier to using this system on larger Web applications.
Guess-a-Number: Our running example demonstrates how Swift uses replication to avoid round-trip communication between client and server. Figure 4, lines 5-8, shows that the compiler automatically replicates the range check onto the client and server, thus saving a network message from the server to the client at line 25.
Shop: This program models an important class of real-world Web applications, and is the largest Swift program written to date: 1,094 lines of Jif source. It is an online shopping application with a back-end PostgreSQL database. Users must register and log in before updating their shopping cart and making purchases.
Poll: This is an online poll that allows users to vote for one of three options and view the current winner.
Secret Keeper: This simple application allows users to store a secret on the server and retrieve the secret later by logging in. This example shows that Swift can handle complex policies with application-defined principals, and that it can automatically generate protocols for password-based authentication and authorization from high-level information security policies.
Treasure Hunt: This game has a grid of cells. Some contain bombs and others, treasure. The user chooses cells to dig in, exposing their contents, until a bomb is encountered. The game has a relatively rich user interface.
Auction: This online auction application allows users to list items for auction and to bid on items from other users. The application automatically polls the server to retrieve auction status updates and to update the display.
Programs compiled by Swift do expand as run-time mechanisms are inserted, though avoiding this expansion was not a significant goal in the current implementation. Across the example applications, we found that expansion was roughly linear, with a server-side code expansion factor between 8 and 13. On the client side, about 800 bytes of JavaScript code were generated per line of Jif code. Much of the expansion occurs when Java code is compiled to JavaScript by GWT, so translating directly to JavaScript would probably help.
From the user’s perspective, the interactive performance of applications is primarily affected by network latency. Table 2 shows measurements of the number of network messages required to carry out the core user interface task in each application. For example, the core user interface task in Guess-a-Number is submitting a guess. The number of actual messages is compared to the optimum that could be achieved by writing a secure Web application by hand.
Messages sent from the server to the client are the most important measure of responsiveness because it is these messages that the client waits for. The table also reports the number of messages sent from the client to the server; these messages are less important because the client does not block when they are sent.
The number of server-client messages in the example applications is always optimal or nearly so. For example, in the Shop application, it is possible to update the shopping cart without any client-server communication. The optimum number of messages is not achieved for poll because the structure of Swift applications currently requires that the client hears a response to each request. For Guess-a-Number and Treasure Hunt, there are extra client-server messages triggering server-side computations that the client does not wait for, but server-client messages remain optimal.
One advantage of Swift is that the compiler can repartition the application when security policies change. We tested this feature with the Guess-a-Number example: if the number to guess is no longer required to be secret, the field that stores the number and the code that manipulates it can be replicated to the client for better responsiveness. Lines 9-13 of Figure 4 all become replicated on both server and client, and the message for the transition from line 13 to 14 is no longer needed. The only source-code change is to replace the label {*→*;*←*} with {*→ client; *←*} on line 3 of Figure 2. Everything else follows automatically.
6. Related Work
In recent years there have been a number of attempts to improve Web application security. At the same time, there has been increasing interest in unified frameworks for Web application development. As a unified programming framework that enforces end-to-end information security policies, Swift is at the confluence of these two lines of work. It is also related to prior work on automatically partitioning applications.
6.1. Information flow in Web applications
Several previous systems have used information flow control to enforce Web application security. This prior work is mostly concerned with tracking information integrity, rather than confidentiality, with the goal of preventing the client from subverting the application by providing bad information (e.g., that might be used in an SQL query). Some of these systems use static program analysis (of information flow and other program properties),10, 12, 22 and some use dynamic taint tracking, 9, 16, 23 which usually has the weakness that the untrusted client can influence control flow. Unlike Swift, none of this prior work addresses client-side computation or helps decide which information and computation can be securely placed on the client. Most of the prior work only controls information flows arising from a single client request, and not information flow arising across multiple client actions or across sessions.
6.2. Unified Web application development
Several recently proposed languages provide a unified programming model for implementing applications that span the multiple tiers found in Web applications. However, none of these languages helps the user automatically satisfy security requirements, nor do they support replication for improved interactive performance.
Links5 and Hop19 are functional languages for writing Web applications. Both allow code to be marked as clientside code, causing it to be translated to JavaScript. Links does this at the coarse granularity of individual functions, whereas Hop allows individual expressions to be partitioned. Links supports partitioning program code into SQL database queries, whereas Hop and Swift do not. Swift does not have language support for database manipulation, though a back-end database can be made accessible by wrapping it with a Jif signature. Neither Links nor Hop helps the programmer decide how to partition code securely.
Hilda24 is a high-level declarative language for developing data-driven Web applications. It supports automatic partitioning with approximate performance optimization based on linear programming. It does not support or enforce security policies, or replicate code or data. Hilda’s programming model is based on SQL and is only suitable for data-driven applications, as opposed to Swift’s more general Java-based programming model.
A number of popular Web application development environments make Web application development easier by allowing a higher-level language to be embedded into HTML code. For example, JSP2 embeds Java code, and PHP18 and Ruby on Rails21 embed their respective languages. None of these systems help to manage code placement, or help to decide when client-server communication is secure, or provide fully interactive user interfaces (unless JavaScript is used directly). Programming is still awkward, and reasoning about security is challenging.
The GWT18 makes construction of client-side code easier by compiling Java to JavaScript, and gives a clean Ajax interface. GWT neither unifies programming across the client-server boundary, nor addresses security.
That performance or security can be improved by partitioning applications across distributed computing systems is an old idea and certainly not original to Swift. Localizing security-critical functionality to trusted components has been explored in limited contexts (e.g., Balfanz1). Coign11 partitions general systems automatically at the component level, though not according to information security policies.
The key feature of Swift is that it provides security by construction: the programmer specifies security requirements, and the system transforms the program to ensure that these requirements are met. Some prior work has explored this idea in other contexts.
The Jif/split system25, 26 also uses Jif as a source language and transforms programs by placing code and data onto sets of hosts in accordance with the labels in the source code. Jif/split addresses the general problem of distributed computation in a system incorporating mutual distrust and arbitrary host trust relationships. Swift differs in exploring the challenges and opportunities of Web applications. Swift uses specialized construction techniques that exploit the trust assumptions it is based on. Supporting mutual distrust between the client and server would be an interesting extension; for example, client state could be protected in cookies. Replication is used by Jif/split only to boost integrity, whereas Swift uses replication also to improve responsiveness.
Fournet and Rezk7 have shown that simple imperative programs annotated with confidentiality and integrity policies, as in Jif/split, can be compiled into distributed, cryptographic implementations that soundly enforce these policies.
7. Conclusion
We have shown that it is possible to build Web applications that enforce security by construction, resulting in greater security assurance. Further, Swift automatically takes care of some awkward tasks: partitioning application functionality across the client-server boundary, and designing protocols for exchanging information. Thus, Swift satisfies three important goals: enforcement of information security; a dynamic, responsive user interface; and a uniform, general purpose programming model. No prior system delivers these capabilities.
What is needed for technology like Swift to be adopted widely? The two biggest impediments to adoption are first, the added annotation burden of writing security annotations, and second, the inefficiency of bulk data transfers between the server and the client.
Jif security annotations are mostly needed in method declarations, where they augment the information specified in existing type annotations. The Jif compiler is able to automatically infer most other annotations. In our experience, the annotation burden is less than the burden of managing client-server communication explicitly, even ignoring the effort that should be expended on manually reasoning about security. More sophisticated type inference algorithms might lessen the annotation burden further.
Transferring data in bulk between the client and the server can be less efficient than with a hand-coded implementation, because data transfers are tied to control transfers. The Swift implementation ensures the client and server stacks and heaps are in sync at each control transfer. It seems likely that Swift could be extended with mechanisms for delaying and securely batching updates to objects.
Because Web applications are being used for so many important purposes, better methods are needed for building them securely. Swift embodies a promising approach for this important problem.
Acknowledgments
We thank the SOSP reviewers, David Mazières, and Martín Abadi for insightful comments and useful suggestions.
This work was supported in part by the National Science Foundation under grants 0430161 and 0627649, in part by a grant from Microsoft Corporation, and in part by AF-TRUST (Air Force Team for Research in Ubiquitous Secure Technology for GIG/NCES), which receives support from the DAF Air Force Office of Scientific Research (FA9550-06-1-0244) and the NSF (0424422).
Figures
 Figure 1. The Swift architecture.
Figure 1. The Swift architecture.
 Figure 2. Guess-a-Number Web application.
Figure 2. Guess-a-Number Web application.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Join the Discussion (0)
Become a Member or Sign In to Post a Comment