
Scientific publishing has changed significantly in recent years. Two important changes are the increase in volume and the move to open access (OA).17,20 The latter often requires authors to pay a publishing fee, introducing new commercial opportunities and attracting new publishers. Some of these new publishers have been branded as predatory21 because they are viewed to be exploiting the OA model without following the best practices to ensure scientific quality. They often solicit and readily accept manuscripts by offering rapid review and publication, which can be problematic for maintaining the high scholarly standards needed to ensure lasting quality.
Key Insights
Publications in new open access venues have less impact on average than those published in traditional venues.
Affording these publications the same status as mainstream journals significantly distorts metrics such as the Field Weighted Citation Index.
There has been a significant increase in the number of authors on research papers in recent years. This further distorts citation metrics that typically do not consider the number of authors on a paper.
Here we study 1.4M computer science (CS) journal papers published between 2000 and 2023, based on the CS bibliography from the DBLP websitea and citation data from Semantic Scholar.b We find an increase in journal articles per year, from 20,000 in 2000 to 120,000 in 2023. Some of this comes from “traditional” journals (for example, from Elsevier or IEEE), but by 2023 one-third of articles came from the new OA journals. This growth alone is concerning, but does it affect publication quality? We analyze whether there are differences in quality between articles in new OA and traditional journals. Our analysis accounts for the move to hybrid models that include OA among traditional publishers in order to distinguish between these and newer OA-first publications.
Our main findings include a rapid increase in publication volume and an even more rapid increase in citations; a surprising increase in the average number of authors on CS papers, which we discuss in detail; and evidence of the impact differences between new OA and traditional articles, even when we account for the use of OA by some traditional publishers.
The article summarizes the emergence of OA publications in CS, offers a review of the main metrics used to evaluate research impact, provides details on the dataset used in our analysis, presents overall trends evident in the dataset, explores differences in citation impact from the data and, proposes several recommendations for more robust citation metrics in light of our findings.
Open Access Publication
OA publication became a reality because of the Internet and online publication.3 Core OA principles were laid out in the Budapest Open Access Initiative in 2001,2 and there are three main forms of OA:4,8 Green OA, in which a version of the article (usually non-final) is available in a repository (for example, arXiv) with no article processing charge (APC) levied; Gold OA, where the final version of an article is permanently and freely available, and authors will likely have paid an APC; and Diamond OA, in which articles are freely available, no APC is paid, and costs are covered by professional societies or academic institutions.
OA changes the economics of academic publishing by potentially eliminating subscriptions or one-off access payments. With Diamond OA, it was expected that initiatives within research communities could bear reduced production costs. For example, the Journal of AI Research (JAIR) launched online in 1993, with paper copies originally printed by AAAI Press but now by the nonprofit AI Access Foundation. In 2001, 40 editorial board members of the machine learning (ML) journal resigned, citing a lack of harmony between the needs of the ML community and the business model of publishers,1 leading to the Journal of Machine Learning Research (JMLR) and more immediate and universal access to articles. Unfortunately, journals such as JAIR and JMLR are rare in CS, and Diamond OA is not covered in the analysis presented here.
OA benefits scientific progress and democratizes research by making publications universally available, and funding agencies increasingly require research results to be made available as OA. However, OA is an interesting example of the law of unintended consequences. Instead of paying for access, researchers pay an upfront publication charge, creating a large market for paid academic publication in an increasingly competitive publish-or-perish academic world. Not surprisingly, this has attracted many new unscrupulous players and increased publication volume but without the guardrails of scientific quality or merit—the fatal flaw of OA, according to Beall.4 It is important to acknowledge that this is not an inherent problem with Gold OA; a profit-focused publisher could still provide good peer review and editorial oversight. However, the analysis presented here suggests this is often not the case.
Indeed, the emergence of unethical practices in Gold OA has led to the widespread use of the terms predatory journal and predatory publishers to describe publishers primarily motivated by the financial gain that can be derived from a high-volume OA business model.11,16 The problem is exacerbated because the demarcation between legitimate and predatory publications is increasingly unclear. Publishers such as Hindawi, Frontiers, and MDPI, which might have been branded predatory in the past, now host journals that are included by indexing services such as PubMed and Scopus. Reflecting this, grey area between traditional and predatory publishers, some publishers are referred to as grey rather than predatory.21 The landscape is further complicated because some traditional publishers have also set up Gold OA journals to benefit from this lucrative market. IEEE Access is perhaps the most visible example, and for this reason, in our analysis, we distinguish between traditional IEEE journals and IEEE Access, grouping the latter with other grey publishers. To further complicate things, many traditional journals have adopted a hybrid model, publishing some Gold OA articles with an APC. Happily, our analysis suggests that there are no quality issues with these OA papers in hybrid journals.
Publication Metrics
While the best way to evaluate the quality of a research paper is to read it carefully,24 methods for quantifying the significance or impact of a paper do have an important and established role. Ranking journals using citation metrics is well established as an important quality indicator, if not a guarantee. Here, we present an overview of such metrics, focusing on those that might be impacted by an increase in publication volume and variability in publication quality.
Field Weighted Citation Impact. The Field Weighted Citation Impact (FWCI) is a key metric in the SciVal research performance assessment service by Elsevier.19 SciVal assigns articles to subject categories and sub-categories and calculates FWCI using Eq. 119: is the number of citations received by article in the publication year plus the following three years, and is the expected number of citations in the same period based on other papers in the same sub-category as .
(1)
A “field weighting” of 1 indicates the world citation average for a particular field, while a score that is less than or greater than 1 indicates a citation count that is lower or higher than the field average, respectively. Importantly, FWCI does not differentiate between publishers, so MDPI or Elsevier papers within the same sub-category are treated similarly.
h-Index. The -index12 measures author productivity and citation impact based on an author’s most cited papers and the number of citations they have received. A scientist with papers has index if of their papers have citations each and the other () papers have citations each.
The -index has several good characteristics: It is a good measure of sustained research impact, and it discourages over-publication on a particular result (“salami slicing”). However, it assumes all citations have the same status, regardless of whether the paper is cited as a passing reference to related work or whether it is cited as a fundamental result that has influenced the citing research.
Another issue with the -index (and with FWCI) is that it does not account for differences in author counts. Every author in a multi-authored article receives full credit for its citation count, even though the contributions of all authors are rarely equal. Accordingly, several alternatives seek to adjust the -index for author count.6 Two formulae for achieving this are as follows:
(2)is -index normalized by the average author count of the included papers. is the pure -index where the normalization is the square root of the average author count, to dampen the impact of a small number of papers with very large author counts.6 Since long author lists are rare in computer science (CS), this square root may not be necessary; see section titled “More Robust Metrics.”
Network centrality. The methods discussed so far do not consider the quality or importance of citations. A citation from a high-impact paper may carry more weight than a citation from a minor paper. This issue has received much attention in research on network centrality measures, using ideas from social network analysis.14 In a social network, the edges/links refer to friendship or other social relationships between nodes (people). A node’s degree refers to its edge count. In citation networks, degree centrality corresponds to a count of citations (edges) between papers (nodes) without consideration of citation significance. However, if the citations come from nodes with high influence scores, we may wish to consider that by weighting these links more highly than citations from nodes with lower influence scores. Eigenvector centrality accounts for this.
A citation network is an adjacency network, where the papers are nodes and the edges are links. Adjacency networks can be represented as square matrices where entry represents a link between nodes and . Eigenvector centrality can be viewed as the probability of a random walk ending up on a particular node; intuitively, well-connected nodes should have higher probabilities. The largest eigenvector of the adjacency matrix represents these probabilities. Two variants of eigenvector centrality are PageRank and Katz centrality. PageRank has had a huge impact on information retrieval.7 Katz centrality is a compromise between degree and eigenvector centrality because it includes an attenuation factor to dampen the impact of influential nodes.23
Bergstrom et al. introduced Eigenfactor Metrics5 for scoring journal impact by quantifying how important a journal is in a citation network in terms of network centrality. Because this gives larger journals more influence, they propose the Article Influence Score, which normalizes the Eigenfactor Score by the number of articles published in the journal. Another journal metric that uses network centrality is the SJR score;10 it has the advantage that the SJR scores for most journals are freely available online at SCImagoJR.c
Influential citations. In the section titled “Overall CS Publications Trends,” we report a significant increase in reference counts with the move to online papers, highlighting the importance of identifying which references are the most meaningful. Semantic Scholar does this by using a “‘Highly Influential Citations’” measure based on a supervised ML method for identifying citations that either use or extend the cited work—influential citations—versus citations that merely cite related work for comparison purposes.22 Valenzuela and Etzioni found approximately 15% of citations to be influential and, this metric helps to differentiate between the new OA and other publications.
The Data
The dataset used in this study was generated using DBLP and Semantic Scholar (April through May 2024). A core set of papers was collected from DBLP by extracting all 1,896,440 journal articles. These articles were used to download corresponding Semantic Scholar records to obtain their citationsd and the records for each citing paper, resulting in 11,723,390 core and citing articles. We focus on the 1,389,339 articles published from 2000 to 2023; we refer to this as the seed set.
We defined traditional publishers (IEEE (excluding IEEE Access), Elsevier, Springer, ACM) and new OA publishers (Hindawi, IEEE Access, Frontiers, MDPI) to distinguish between journals adopting more conventional academic publication practices versus more recent paid OA models. We identified all articles in our dataset published in these target journals.
For these traditional publishers, the Semantic Scholar records allow us to identify articles that are OA; these are categorized as Trad (OA), and non-OA articles from traditional publishers, which we refer to as Trad.
This resulted in 755,890 Trad, 379,313 Trad (OA), and 254,136 New OA articles. We use this dataset to: analyze trends in the CS publication landscape since 2000, and to analyse the citation impact of traditional versus (new) OA publishers. Since traditional publishers have a longer history—therefore, a greater opportunity to attract citations—we focus on a subset of 850,369 articles published between 2015 and 2023; 391,602 Trad, 229205 Trad (OA), and 229,562 New OA articles.
Overall CS Publication Trends
Looking at at the overall trends in the CS publication landscape, there has been a significant increase in publication volume (Figure 1a). Output from traditional publishers has grown from about 20K papers in 2000 to more than 80K in 2023. Significant output from New OA publishers emerged after 2008 and increased steeply to 2020, reaching 40K papers per year. The decline in the 2019 data for traditional publishers is likely due to a data issue with Semantic Scholar, whereby some 2019 articles are incorrectly listed as 2020 articles. Figure 1c shows that the average number of authors per paper, for traditional and New OA collections, has almost doubled from just over two authors per paper in 2000 to more than four in 2023.

The number of references per paper has also been increasing (Figure 1d). There is a sharp increase in the number of references in the New OA group from 2008 coinciding with the rise of New OA papers in Figure 1a—presumably due to relaxed bibliographic limits—but the reason for the growth among traditional journals is less clear-cut, although the mean reference count for Trad (OA) papers does exceed that of Trad papers, just like the New OA papers.
Figure 1e shows citation counts per paper normalized by dividing by the number of years since publication. New OA papers have historically attracted fewer citations than papers in traditional venues, and while the situation improved somewhat around 2009, the difference remains. Moroever, Trad (OA) papers attract more citations than non-OA Trad papers, consistent with the notion that OA papers are more readily discoverable than non-OA papers. This impact difference is more apparent when we look at the normalized influential citation count in Figure 1f. The un-normalized versions of these graphs are shown in the Appendix online.e This suggests an impact disparity that is due to the publisher type (grey versus traditional publishers) rather than the publishing model per se.
Increase in publication volume. To further explore the increase in publication volume since 2020, in Figure 1b we show changes in publication volume by publisher for the two four-year periods before and after 2020. While Elsevier and IEEE are the largest publishers overall, Frontiers, MDPI, and IEEE Access have the largest relative growth. By growing at more than twice that of traditional publishers, New OA publishers are reshaping the CS landscape. MDPI is now the number three producer of journal articles in CS and may soon overtake IEEE and perhaps Elsevier.
The increase in author count. There is no obvious reason for the surprising authorship growth in CS. This could be due to a move toward multi-disciplinary research or larger research groups, which may be characteristic of modern CS research. It may be due to increased collaboration between academic and industry partners. Wu et al. document a shift toward larger research teams in recent years25 but point out that work from larger teams tends to be more incremental.
At the same time, if a valid number of authors on a paper in 2000 is two, is an average of four in 2023 equally valid? Is such an increase consistent with the need for co-authors to make significant intellectual contributions?15 If not, why might the primary authors be willing to share authorship with others? One possible explanation is that it reflects a desire to influence the future citation count of published papers.25 If self-citation increases citations, then the more co-authors, the more co-author-level self-citations.
To further explore this change in authorship practice, Figure 2 presents the mean author count by publisher for the four years from 2020 to 2023. While three of the top four publishers are New OA, it is clear that the difference between traditional publishers and New OA is not huge.

In Appendix B, we explore the impact of an increase in multi-disciplinary research and find that journals presenting multi-disciplinary research are perhaps more prominent now. However, even within these multi-disciplinary journals, there has been an increase in author count, so this increase seems to be pervasive.
Furthermore, in the Semantic Scholar records, the “Field of Study” for each paper is listed. Roughly 75% of papers have only “Computer Science” as the “Field of Study.” It seems reasonable to infer that papers with more than one “Field of Study” are inter- or multi-disciplinary. However, the proportion of such papers has actually dropped slightly from 27% to 25% between 2005 and 2020, suggesting that the increase in author count is not due to an increase in interdisciplinary research.
Impact Differences
Next, we compare New OA and traditional publishers under two criteria: citation network centrality and influential citations. The analysis is based on publications since 2015 because, as per Figure 1a, New OA publishers were not particularly active before 2015.
Network centrality analysis. Network centrality helps to identify influential nodes in a citation network with papers as nodes, in-links are citations, and the out-links are references. The result is a network with 850K nodes (papers) and 17M citations (edges), stored as an 850K 850K matrix. This network can be aggregated so that the nodes represent journals, with edges weighted by the number of citations from one journal to another. This network can be further aggregated so that the nodes are publishers; this publisher network has only eight nodes.
Estimating centrality in this publisher network is complicated because of differences of volume between publishers. The dataset contains 250K Elsevier papers, from 2015 onward, compared to 120k MDPI and 37K ACM papers. Since high-volume publishers will dominate centrality measures based on raw citation counts, we consider the ratio of in-links to out-links for our analysis. The numbers indicate the ratio of citations from the column publisher to the row publisher, with larger numbers (green) indicating greater influence. For example, the bottom left cell indicates that on average an IEEE paper receives 6.01 as many citations from a Hindawi paper as a Hindawi paper received from an IEEE paper. Likewise, ACM papers receive 3.29 as many links from MDPI as MDPI papers receive from ACM. And, in general, the larger values in the lower left quadrant indicate traditional publishers receive many more citations from New OA publishers than New OA publishers receive from traditional publishers.
The centrality of nodes in this network can be quantified using eigenvector centrality (see Figure 3b). This summarizes the picture in Figure 3a and draws a sharp distinction between the traditional publishers (IEEE, ACM, Elsevier, Springer), which have greater eigenvector centrality scores than the New OA publishers. Despite the publication volume of MDPI and IEEE Access, they do not have a significant impact. It also highlights that IEEE and IEEE Access are very different in this regard.
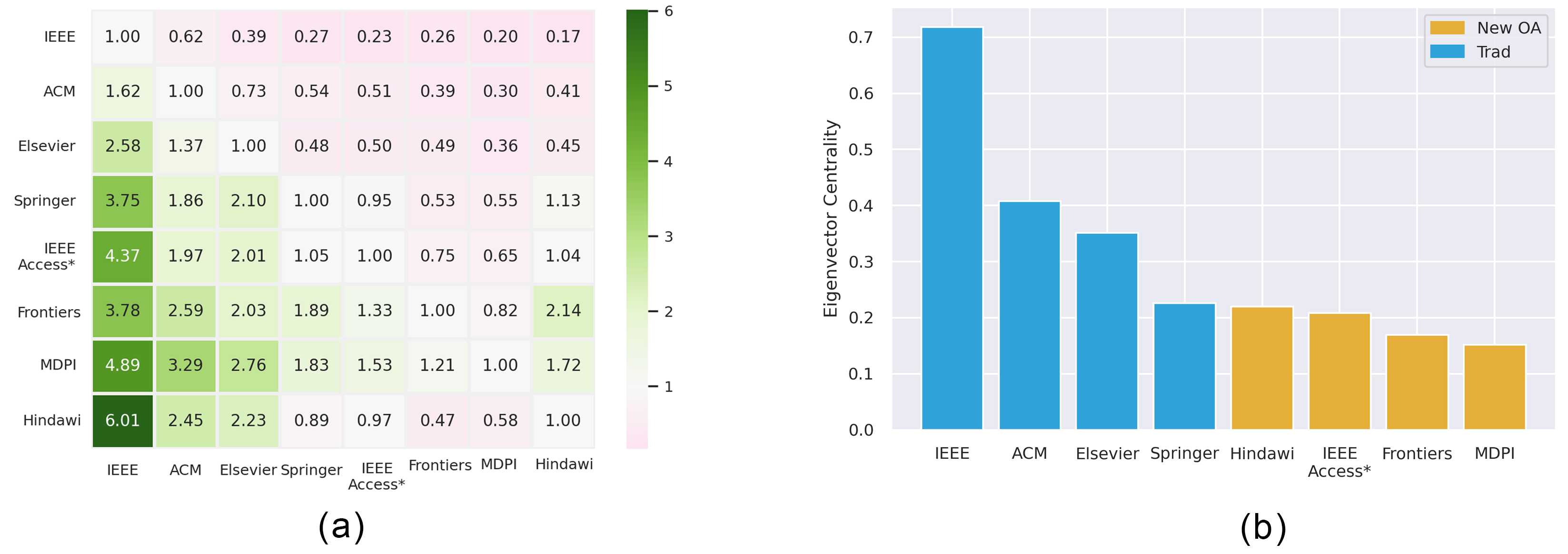
Figure 3. (a) The ratio of in-links (citations) to out-links (references) between publishers (since 2015), for example, an IEEE paper receives six times the number of citations from Hindawi papers and vice versa. The heatmap colors are centred on 1. (b) The eigenvector centrality of publishers in the graph shown in the heatmap.
Citations and influential citations. Online publishing has made citations easier to come by; there are more papers and more references per paper. This is one reason why Semantic Scholar differentiates between influential and regular/incidental citations.22 In our post-2015 dataset, there are 850,368 papers with 17,121,561 citations; 824,002 (4.8%) are marked as influential. If we only consider papers from our dataset with 1 influential citations, then approximately 12% of citations are influential, a closer match with Valenzuela and Etzioni. Figure 4a shows how this fraction varies by publisher; three of the top four publishers are traditional, while three of the bottom four are New OA.

Figure 4b looks at the status of the citing papers using their fraction of influential cites. At the top, papers that cite ACM papers tend to have higher fractions of influential citations compared with papers that cite MDPI or Hindawi papers, for example. Once again, three of the bottom four publishers are New OA publishers. Looking at overall citation counts in Figure 4b, the IEEE papers come out on top (30 citations/paper) followed by Elsevier, ACM, and IEEE Access; IEEE Access fares better than the other New OA publishers in this analysis.
We have tested the statistical significance of these differences in mean citation and mean influential citation counts using one-way ANOVA tests to check if any pair of means is different, followed by Tukey honestly significant difference (HSD) tests to make pairwise comparisons between publishers. For both ANOVAs, the -values are close to zero, suggesting at least some of the publishers have different population means. The HSD results include: the mean citation count for Elsevier papers is almost twice that of MDPI, which is statistically significant (); the mean citation count for traditional IEEE papers is almost twice that of IEEE Access, which is statistically significant (); the mean influential citation count for ACM papers is three times that of MDPI (). Detailed results are presented in an Appendix to the repository version of this paper.9
More Robust Metrics
Our analysis shows that established publication metrics such as the -index and FWCI are open to question because they are insensitive to author count or the citation source. Average author count has doubled since 2000, strengthening the case for considering author count. The citation analysis in the “Impact Differences” section suggests that citations should not be treated as equal, as happens with them currently.
The “Publication Metrics” section highlights several ways to address these issues, such as by normalizing -index to adjust for author count.6 A recent paper in PLOS ONE13 argues that a fractional allocation of -index based on author count is a better indicator than the standard -index.
Metrics based on network centrality such as the Eigenfactor Score and the Author Influence Score5 scale citations based on influence and provide a better indicator of article impact. As an example, when the SJR score is used to compare MDPI Sensors with the Communications of the ACM it reveals an interesting picture: according to Scopus, both publications have similar cites per paper, yet the SJR scores are respectively 0.79 and 2.96. Thus, this SJR score captures the differences illustrated in Figures 3a and 3b. Indeed, the Clarivate Journal Citation Reports use Eigenfactor and Author Influence scores, but only as secondary resources. Their wider application would address the issues highlighted here.
Conclusion
The CS publication landscape is changing. Journal output has increased more than five-fold from 2000 to 2023, partly due to OA publication models; a significant proportion of papers are now produced by New OA publishers. Concerns exist about a New OA downside, because the economics of OA publishing may incentivize quantity over quality. We find evidence to support this:
New OA publishers have experienced higher growth rates than their traditional counterparts.
On average, New OA papers in CS receive fewer citations than they produce; in network-centrality terms, New OA publishers have low status.
New OA papers receive fewer influential citations than traditional journals, and the citations they receive come from papers with fewer influential citations.
OA papers from traditional publishers do not suffer in this way; in fact, there is evidence that they attract more citations than their non-OA counterparts.
Thus, any evaluation of publication quality should account for these effects. Instead of relying on metrics which treat all citations as equal, it may be appropriate to use methods that do not treat all citations the same.18 Furthermore, while larger authorship counts may be justified for interdisciplinary research, they should not be so readily accepted for conventional research papers, especially if motivated by the desire to increase personal publication output and citation counts. One way to discourage this trend is to change how we measure publication impact by using metrics that apportion credit based on the number and positioning of authors.
In summary, given the increased volume and visibility of New OA papers, it may be important to educate researchers, especially young, early-career researchers—those most acutely exposed to the pressure of publish-or-perish—about these changes in the publication landscape. Moreover, the evidence reported here justifies changes in how publication quality is assessed to properly account for these landscape changes by considering authorship and impact more carefully.
Acknowledgments
Supported by Science Foundation Ireland through the Insight Centre for Data Analytics (12/RC/2289_P2).



Very useful analysis. It provides important factual information about issues that everyone discusses in the community; we need facts, not just opinions, and you provide many of them.
The picture you paint is not pretty. I was always skeptical of the big speeches (starting two decades ago) in favor of open access, often based on ideology (you looked bad if you asked questions — what decent person could be against anything that has “open” in its name?) Beyond the grandstanding, I am not sure, after having read the article, whether the change of model has really benefited the field and its advancement of knowledge.
We will see, but the community can be grateful to you for performing this essential analysis in an objective manner, providing us with a more solid basis for discussion the situation of publications in the field and efforts to improve it.
— Bertrand Meyer