Deep neural networks (DNNs) that use reinforcement learning (RL, which explores a space of random decisions for winning combinations) can create algorithms that rival those produced by humans for games, natural language processing (NLP), computer vision (CV), education, transportation, finance, healthcare, and robotics, according to the seminal paper Introduction to Deep Reinforcement Learning (DRL).
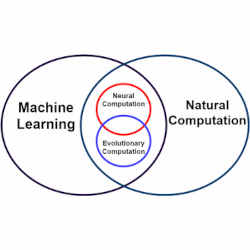
Unfortunately, the successes of DNNs are getting harder to come by, due to sensitivity to the initial hyper-parameters chosen (such as the width and depth of the DNN, as well as other application-specific initial conditions). However, these limitations have recently been overcome by combining RL with evolutionary computation (EC), which maintains a population of learning agents, each with unique initial conditions, that together “evolve” an optimal solution, according to Ran Cheng and colleagues at the Southern University of Science and Technology, Shenzhen, China, in cooperation with Germany’s Bielefeld University and the U.K.’s University of Surrey.
By choosing from among many evolving learning agents (each with different initial conditions), Evolutionary Reinforcement Learning(EvoRL) is extending the intelligence of DRL into hard-to-solve cross-disciplinary human tasks like autonomous cars and robots, according to Jurgen Branke, a professor of Operational Research and Systems at the U.K.’s University of Warwick, and editor-in-chief of ACM’s new journal Transactions on Evolutionary Learning and Optimization
Said Branke, “Nature is using two ways of adaptation: evolution and learning. So it seems not surprising that the combination of these two paradigms is also successful ‘in-silico’ [that is, algorithmic ‘evolution’ akin to ‘in-vivo’ biological evolution].”
Reinforcement Learning
Reinforcement learning is the newest of three primary learning algorithms for deep neural networks (DNNs differ from the seminal three-layer perceptron by adding many inner layers, the function of which are not fully understood by its programmers—referred to as a black box). The first two prior primary DNN learning methods were supervised—learning from data labeled by humans (such as photographs of birds, cars, and flowers, each labeled as such) in order to learn to recognize and automatically label new photographs. The second-most-popular learning method was unsupervised, which groups unlabeled data into likes and dislikes, based on commonalities found by the DNN’s black box.
Reinforcement learning, on the other hand, groups unlabeled data into sets of likes, but with the goal of maximizing the cumulative rewards it receives from a human-wrought evaluation function. The result is a DNN that uses RL to outperform other learning methods, albeit while still using internal layers that do not fit into a knowable mathematical model. For instance, in game theory, the cumulative rewards would be winning games. ‘Optimization’ is often used to describe the methodology obtained by reinforcement learning, according to Marco Wiering at the University of Groningen (The Netherlands) and Martijn Otterlo at Radboud University (Nijmegen, The Netherlands) in their 2012 paper Reinforcement Learning, although there is no way to prove that “optimal behavior” found with RL is the “most” optimal solution.
To this end, RL explores the unknown nooks and crannies of a solution space to see if they reap more optimal rewards, as well as to coax the DNN into more optimal solutions from its already accumulated knowledge that has proven to result in more rewards. Reinforcement learning achieves ever-higher cumulative rewards as it progresses toward optimization, according to Richard Sutton, a professor of Computing Science in Reinforcement Learning and Artificial Intelligence at Canada’s University of Alberta and a Distinguished Research Scientist at DeepMind, working with Andrew Bartow, a professor emeritus of computer science at University of Massachusetts (Amherst), in their 2012 paper Reinforcement learning: An introduction.
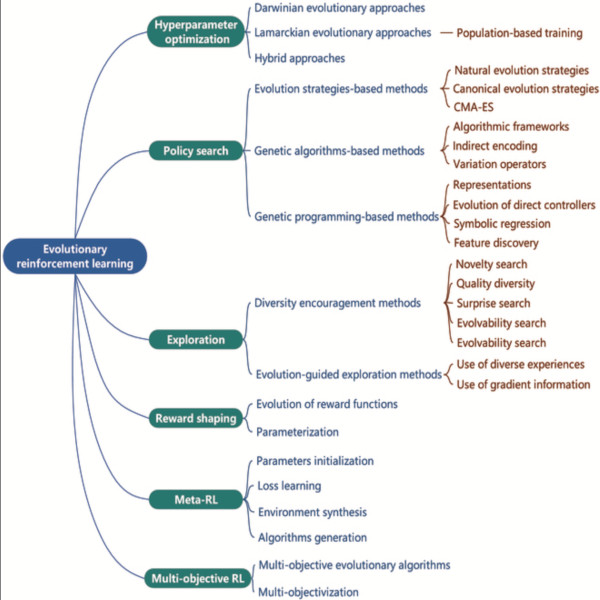
hyper-parameter optimization—a universal algorithm also used in the other five methodologies since it simultaneously realizes end-to-end learning while improving performance.
Policy search seeks to identify a policy that maximizes the cumulative reward for a given task.
Exploration encourages agents to explore more states and actions and trains robust agents to better respond to dynamic changes in environments.
Reward shaping is aimed at enhancing the original reward with additional shaping rewards for tasks with sparse rewards.
Meta-RL seeks to develop a general-purpose learning algorithm that can adapt to different tasks.
Multi-objective RL aims to obtain trade-off agents in tasks with a number of conflicting objectives.
Credit: Evolutionary Reinforcement Learning: A Survey
Evolutionary Computation
Evolutionary computation, on the other hand, creates a random population of problem-solving agents, then “evolves” them by subjecting each to “natural” selection—that is, discarding the worst, mutating the rest, and repeating the process. Each agent is measured against a fitness-function—as in the “survival of the fittest.” The process is repeated as many times as necessary until an optimal solution results, albeit one that is not guaranteed to be perfectly optimal.
When evolutionary computation is combined with reinforcement learning (EvoRL), the combined methodology evolves a population of agents—each with different application-specific initial conditions, thus obsoleting the need to manually restart a DRL that does not converge on a suitable optimum.
“EvoRL provides a powerful framework for addressing complex problems by taking advantage of the strengths of both RL and evolutionary methods. It allows agents to explore a wide array of policies, leading to the discovery of novel strategies and contributing to the development of autonomous systems,” said Giuseppe Paolo, a Senior AI Research Scientist in Noah’s Ark Lab at Huawei (Paris) and a guest editor of a special issue coming soon on Evolutionary Reinforcement Learning from ACM’s new journal Transactions on Evolutionary Learning and Optimization.
Adds another guest editor, Adam Gaier, a principle research scientist in Autodesk’s AI Lab (Germany), “We wanted to bring this combined field to the attention of researchers and practitioners in both fields as a way of encouraging further exploration. In the special issue, we feature an extensive review of the field, new original research, and an application of EvoRL to a real-world problem. As such, EvoRL is an increasingly active field which blends the power of Reinforcement Learning (RL) and Evolutionary Computation to tackle RL’s principal obstacles. While RL excels in complex tasks, it struggles with sensitivity to initial setup values, ascertaining the actions that lead to delayed rewards, and navigating conflicting goals. Evolutionary Algorithms (EAs), on the other hand, manage these issues but they falter when dealing with data scarcity and complex, high-dimensional problems. EvoRL elegantly combines RL’s optimization and EAs’ population-based methods, enhancing exploration diversity and overcoming EA’s constraints while amplifying RL’s strengths.”
While reinforcement learning alone usually follows the gradient provided by the evaluation function to effectively improve potential solutions, evolutionary computation first starts with a population of candidate solutions whose initial conditions are randomly chosen. The population is evaluated by the human-supplied fitness function. Those with the lowest fitness are discarded, while the rest are mutated through evolutionary computation and the process repeats until the point of diminishing returns in optimization is reached. This enables the evolutionary process to be less subject to getting stuck in local optima (an obstacle to gradient-based approaches) and provides “creativity,” according to Antoine Cully, senior lecturer in Robotics and Artificial Intelligence and director of the Adaptive and Intelligent Robotics Lab in the Department of Computing at the U.K.’s Imperial College London.
Said Cully, also a guest editor for the special issue, “The domain of Evolutionary Reinforcement Learning is a very exciting area of research as it combines the creativity and exploration capabilities of evolutionary algorithms, with the effectiveness of gradient descent from Deep Reinforcement learning, which allows complex neural-network policies to be optimized. We are just at the beginning of exploring the synergies between these two research areas, but it has already shown to be fruitful.”
According Cheng et al, there are six major variations of EvoRL is use today (as listed in the caption to the graphic above). Efficiency is a major future direction for refinement, since all six major EvoRL algorithms are computationally intensive. Improvements are needed in encodings, sampling methods, search operators, algorithmic frameworks, and fitness/evaluation methodologies. Benchmarks are also needed, but may be tough to hammer out, according to Cheng et al, since the six basic approaches use different hyper-parameters and application specific algorithms. Scalable platforms are also needed and are being developed, but again are mostly limited to one or two of the six major approaches.
R. Colin Johnson is a Kyoto Prize Fellow who has worked as a technology journalist for two decades.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment