
Reinforcement learning (RL) is machine learning (ML) in which the learning system adjusts its behavior to maximize the amount of reward and minimize the amount of punishment it receives over time while interacting with its environment. What we now call RL has roots in animal learning theories from psychology, and it played key roles in some of the earliest artificial intelligence (AI) systems. In contrast to supervised learning (SL), which works to reduce errors between responses and correct responses as given by training examples, RL does not rely on knowledge of correct responses; it instead relies on more general evaluations of behavior.
After its early AI applications, RL was largely neglected in favor of other approaches to ML and AI. This article describes how RL was effectively rediscovered as a powerful approach to ML, with specific focus on the role of funding from the U.S. Air Force Office of Scientific Research (AFOSR) and the National Science Foundation (NSF). I begin by relating the importance of both basic and applied research to a fundamental predicament in decision making, optimization, and RL known as the exploration-exploitation dilemma.
The Exploration-Exploitation Dilemma
Seen through the right lens, the exploration-exploitation dilemma is not only important in decision making, optimization, and RL, it also is relevant to the process of research itself. What makes the dilemma important is the considerable uncertainty that usually characterizes the objectives in these domains.
I first learned about the exploration-exploitation dilemma (sometimes referred to as the explore-exploit trade-off) from Professor John Holland in my first course as a computer science graduate student at the University of Michigan. Professor Holland became well-known for developing optimization algorithms, which he called genetic algorithms, inspired by biological evolution.
For both evolution and genetic algorithms to work, both exploitation and exploration are needed. Exploitation is needed to take advantage of—to exploit—what has been discovered so far to be high-performing solutions, which in the case of evolution are genotypes of high biological fitness. Exploration, on the other hand, is the engine of novelty that opens the door to discovering new genotypes of even greater fitness than those discovered so far. Populations without exploration would be trapped in their current state, losing the ability to adapt to environmental changes or new competition. Exploitation and exploration thus go hand in hand in evolution, in optimization, in RL, and in research.
One way evolution explores is through random genetic mutation; optimization algorithms sometimes correspondingly use randomness in the search process. But randomness is not essential for exploration. What makes a process exploratory is that its findings cannot be fully anticipated from the start. For example, an explorer can be guided by a detailed and accurate map that nevertheless includes terra incognita. The point is to occasionally try something new because it might be better than anything found so far. And so it is with RL.
At its base, RL is an optimization process. RL methods search for highly rewarding situation-action mappings by generating and testing alternatives. The need to search makes dealing with the exploration-exploitation trade-off an important element of RL algorithms, and many methods have been developed for mixing exploratory and exploitative behavior. For example, one of the simplest ways to combine exploitation and exploration in a search for a best action (that is, an action leading to the most reward) is to usually perform an action that is currently estimated to yield the most reward (exploitation), but to occasionally perform an action from among the other actions—that is, from among the actions not currently estimated to be the best (exploration).
The exploration-exploitation trade-off is paralleled in the distinction between basic, or fundamental, research and applied research. Just as a mix of exploitation and exploration is essential for the optimization aspects of evolution, the success of decisions by funding agencies relies on a mix of basic and applied research, either within agencies or across multiple agencies. Basic research is necessary to set science and engineering off in new, potentially profitable, directions. Applied research is necessary to use discoveries to achieve a goal—for example, to build a new technology.
As a case in point, the funding that supported the research that led to Richard Sutton and me receiving the 2024 ACM A.M. Turing Award for our work developing RL was for purely curiosity-driven basic research—that is, for exploration. Initial funding, beginning in 1977, was from the AFOSR, with the only “deliverables” being annual reports and a final report. Later, our research was funded by the NSF Division of Electrical, Communications, and Cyber Systems (ECCS). Here, also, the deliverables were reports, not devices, patents, or products that exploited the still-nascent results of our exploratory research. Basic research support made it possible for us to widely and deeply explore the breadth of the subject that eventually became known as RL, now the science underlying many remarkable uses (exploitation) in many domains.
The First Project
Our first project could only have been supported as basic research because its goal was to explore a theory of memory, learning, and intelligence that fell well outside of mainstream science and engineering. The particular theory we explored was developed by A.H. Klopf, a senior scientist for machine intelligence in the Avionics Directorate in Wright Laboratory at the Wright-Patterson Air Force Base. Klopf’s 1982 book The Hedonistic Neuron: A Theory of Memory, Learning and Intelligence4 elaborated his theory of brain function and intelligence. The objective of the project in which Sutton and I participated was to investigate this theory to evaluate its scientific merit and prospects for future development. With this funding for basic research, we were permitted to explore these ideas critically and compare them with the long history of prior work in learning and adaptive systems. Our task became one of teasing the ideas apart and understanding their relationships and relative importance.
Underlying Klopf’s theory was his rejection of the commonly held idea that homeostasis was the bedrock of physiological processes. Homeostasis is the state of equilibrium in which critical variables are held constant, or held within narrow limits on ranges of variability. Klopf argued that equilibrium seeking is only a subgoal of adaptive systems, and that the critical overriding goal is to maximize certain variables related to an organism’s “pleasure,” He coined the term “heterostasis,” meaning a state in which certain variables are held at their maximum values, as opposed to their values at equilibrium.
Not all of Klopf’s theory withstood our examination. But it didn’t take long for us to recognize that Klopf’s theory was different from how most ML methods worked. Most ML methods were designed to reduce errors over multiple trials using the SL approach. In SL, the learner computes the error associated with a given decision—that is, the difference between how the learning system responds to an input and how it should have responded to that input according to a given training example. An error is typically a number with a positive or negative sign. A positive error (actual response − desired response) means the learner’s response was too high, whereas a negative error means the learner’s response was too low. In contrast, what Klopf was suggesting (at least our interpretation of what he was suggesting) is that instead of attempting to correct errors by driving them to zero, the learning system receives rewards it tries to maximize, or more specifically, tries to maximize the sum of rewards received over time (where penalties, if there are any, are treated as negative rewards). On the surface, this may seem like a minor departure from SL, but in fact it is a profound difference: Rewards and penalties need not be based on knowledge of how the learner should respond. Whatever is the source of the rewards, it does not need to know what would constitute the desired behavior.
Consider, for example, how a movie-rating website might assign a numerical score to a movie giving the percentage of professional critic reviews that are positive. The score does not indicate what the movie should have been, nor what would have made it better. (Of course, human critics base their reviews on many factors, including opinions about what a film lacks and what would have made it better, but the rating website’s score does not include this information.) If a filmmaker wants to maximize the scores of its movies, then the filmmaker effectively uses RL, in contrast to using SL. A filmmaker tries out various movies over time in a trial-and-error process to try to raise the scores of its movies: The filmmaker needs to explore. (Note that the phrase “trial-and-error” is misleading because the process does not rely on errors as we defined them above; a better phrase would be “trial-and-evaluation.”)
Learning from evaluative information instead of from examples of desired behavior is important for three main reasons. First, it means RL can be applied to problems for which it is not possible to obtain the kinds of training examples needed for SL. Second, an RL system has to explore by probing its environment through trial-and-error (that is, trial-and-evaluation). Third, the exploitation-exploration trade-off therefore plays an essential role in RL.
Our Idyllic Period of Exploration
The principal investigators (PIs) of the initial AFOSR-funded project were three UMass Amherst computer science professors: Michael Arbib, William Kilmer, and Nico Spinelli. Professor Arbib, author or editor of almost 40 books, founded the UMass Center for Systems Neuroscience in the 1970s, which provided a rich interdisciplinary environment in which computer scientists and engineers could interact with neuroscientists and cognitive scientists. Professor Kilmer had worked with the renowned neurophysiologist and cybernetician Warren McCulloch, and Professor Spinelli was a physician and neurophysiologist. At the time, the UMass Center for Systems Neuroscience provided one of a very few environments encouraging this kind of interdisciplinary exploration. It was a rich environment in which to evaluate Klopf’s and related theories.
After obtaining a Ph.D. in computer science at the University of Michigan, I was hired in 1977 as a postdoctoral researcher supported by the UMass AFOSR-funded project. Shortly afterward, I was joined by Richard Sutton, who had just been admitted to the UMass Computer Science graduate program after obtaining a BS in psychology with a minor in computer science from Stanford University. Sutton and I, joined a bit later by Charles Anderson, a recent graduate of the University of Nebraska with a BS in computer science, benefited from the unusual opportunity to devote nearly full-time effort to examining Klopf’s, and many related, ideas from all angles.
It was a rare opportunity (and sorely missed after I became a UMass faculty member) for me to study without pressure to attend faculty meetings, go to conferences, or even to publish (as it was easy to produce the required reports given all we were learning). We continued to consult with the PIs of the AFOSR project, but seeing that we novices were on a roll so to speak, they gave us nearly complete freedom.
As graduate students, Sutton and Anderson had to fulfill some course requirements, but they mostly enjoyed this freedom too. They were supported as graduate research assistants through the AFOSR-funded project, and later through grants from the NSF. I became an associate professor in 1982, so I was able to be their official faculty advisor as they completed their doctoral degrees, with dissertations resulting from this research experience. Sutton’s 1984 dissertation “Temporal Credit Assignment in Reinforcement Learning”9 developed the highly influential Temporal Difference Algorithm,10 which has become a key component of many modern systems using RL. Anderson’s 1986 dissertation “Learning and Problem Solving with Connectionist Systems”1 combined RL with the then-recent developments in training multi-layer neural networks by means of the error back propagation algorithm. His work is the progenitor of the modern methods of Deep RL.
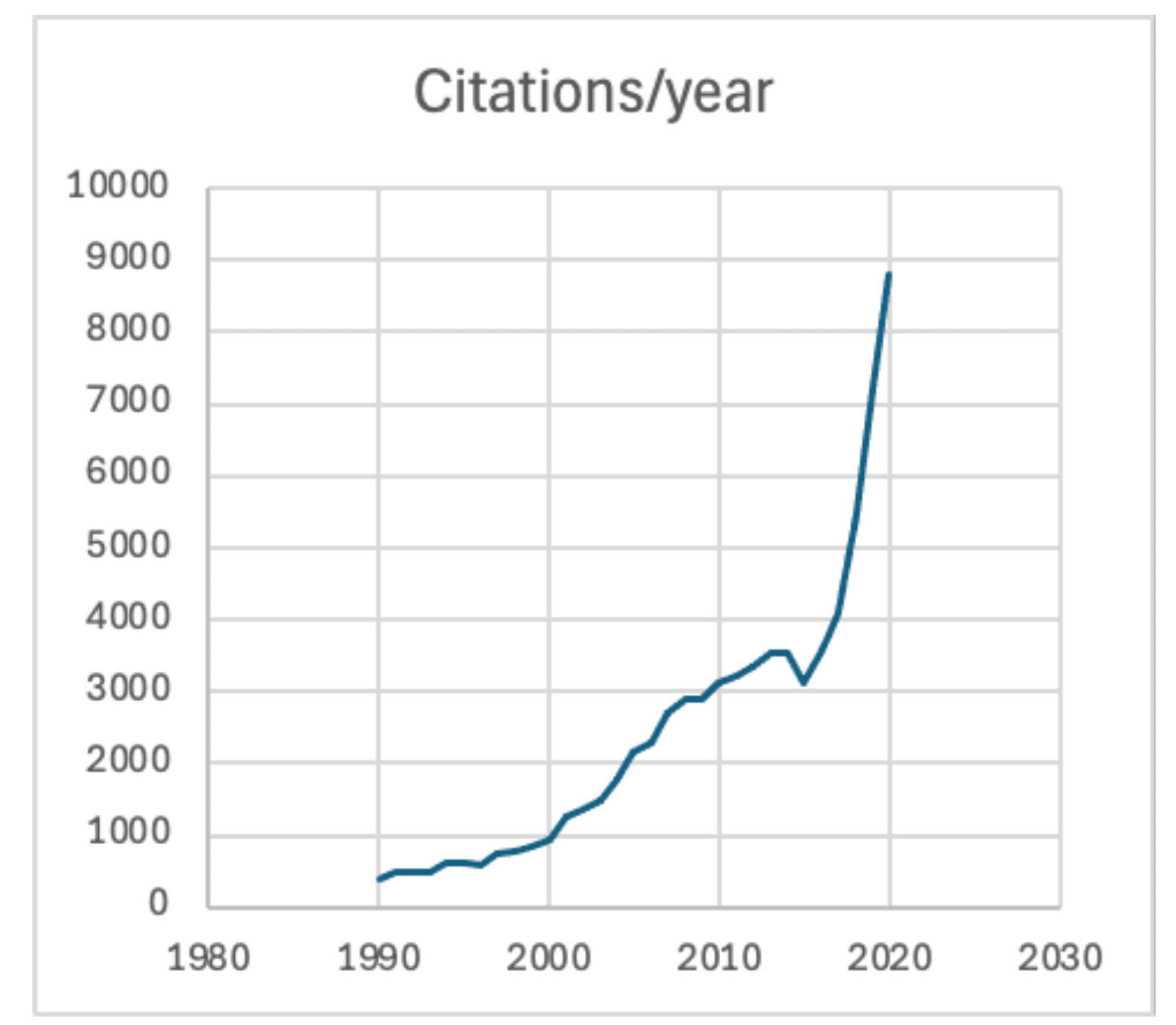
Figure. Yearly citations to publications in which I am an author or co-author [source: Google Scholar].
At the end of this relatively idyllic period of pure exploration, Sutton and I, sometimes including Anderson and other graduate students who joined the team, published a number of papers in prominent venues covering everything they had discovered. Many of these papers have been widely cited. Among the most cited is our 1983 paper demonstrating RL applied to a classic control problem.2 It is notable that the citation rate to our work was initially quite low, but as RL became more widely understood and deployed, the citation rate accelerated. The figure illustrates the number of citations to publications in which I am an author or co-author over time (as reported by Google Scholar). This illustrates that there can sometimes be a long “incubation” period from the time that ideas are first developed until they find widespread acceptance and use.
Beyond the First Project
After this initial period of exploration, RL research at UMass continued. A number of very talented students were admitted to the UMass Ph.D. program, and the subject was taken up by students at other institutions around the world. Notable were the connections established between RL and more traditional mathematical and engineering methods. In particular, we studied RL’s connections to theories of stochastic optimal control, including Markov decision processes, dynamic programming, and Monte Carlo methods. We wanted to “speak the language” of these more established subjects to gain the interest, and possible participation, of experts in these subjects, as well as to understand what RL might offer that these traditional methods did not.
Along with studying connections to mathematical and engineering methods, we studied connections to the long and rich history of ideas, experimental findings, models, and systems from psychology and AI. Indeed, the basic ideas of RL derive from animal-learning theories developed by psychologists, namely the reinforcement theories of classical, or Pavlovian, conditioning and instrumental, or operant, conditioning.
In fact, we found that the earliest ML systems, those produced in the 1950s and 1960s, were inspired by the reinforcement theories of animal learning then predominant in American psychology—for example, Skinner et al.7 and Thorndike.13 For example, to the best of my knowledge, the earliest implementation of ML on a digital computer used an algorithm based on instrumental conditioning.3 Even before digital computers existed, electro-mechanical learning machines had been constructed based on what was known about animal learning—for example, Smith.8 It was only later that SL became the most influential paradigm of ML. Modern RL benefits from animal-learning theories too but it incorporates new findings in psychology and neuroscience, as well as decades of progress in AI.
In particular, we were strongly influenced by the role RL played in early AI. Notable was Arthur Samuel’s landmark program that learned to play the game of checkers via self-play using what we now call RL.6 Another major influence was the research and perspective of AI pioneer and 1969 Turing Award recipient Marvin Minsky. In particular, his famous 1961 “Steps” paper5 examines his early exploration of RL. We also discovered that as early as 1948, Alan Turing proposed a “pleasure-pain” system (where pleasure is reward and pain is punishment) as the foundation of machine intelligence.14 If this had been implemented on a computing machine (none were yet available to him), it would have been much like a modern RL system. Turing’s ideas for AI undoubtedly influenced all subsequent development of RL.
As our understanding advanced, Sutton and I decided it was time for an RL book. Work on the book took place over a period of about five years, culminating with its 1998 publication11 by MIT Press in its “Adaptive Computation and Machine Learning” series. The success of that book, together with later advances and growing worldwide interest in RL, led to our significantly expanded second edition, published in 2018.12
The Gift of Exploration
The exploration-exploitation dilemma continues to be a fundamental issue in decision making, learning, and adaptation. Exploration is needed to discover what is new; exploitation is needed to transform what is new into practical and beneficial action. The initial development of modern RL was purely exploratory. Klopf’s heterostatic theory of the brain and intelligence was out of the mainstream of both neuroscience and AI. The projects at UMass to assess this theory critically depended on basic research support from AFOSR and NSF.
The exploration set in motion subsequent development that has produced technological fruit across a growing collection of applications in many domains, including, but not limited to, healthcare, marketing, transportation, industrial automation, finance, gaming, and robotics. RL development continues as theory is extended, better algorithms are created, new applications are fielded, and methods are developed to mitigate the risks that online trial-and-error exploration can create.
A fundamental underlying premise of federally funded basic research is that exploration, in the form of basic research, is the driver of technological progress. Indeed, the preamble to the 1950 Act creating the NSF notes that a key part of its mission is “to initiate and support basic scientific research and programs to strengthen scientific research potential.” The ongoing trajectory of RL provides a convincing demonstration of the validity of this principle.




Join the Discussion (0)
Become a Member or Sign In to Post a Comment