
The current COVID-19 pandemic demonstrates that understanding data is important not only for scientists, but for everyone. To understand the meaning of the data provided by popular media channels regarding the pandemic, a basic understanding of data science principles is needed, in addition to basic skills for reading and interpreting tables and graphs.
The huge, recent growth in available data and machine power is increasing the demand for data scientists who can generate value from this data. This demand, in turn, is leading many institutions to offer data science programs (Berman et al., 2018). Data science education, however, is a challenging and very young field of research.
In this blog we highlight ten challenges of data science education. The challenges are clustered into three categories: (a) Discipline, (b) Skills, and (c) Environment of data science education, creating the abbreviation DSE, which also stands for Data Science Education.
Category 1 – Discipline
The discipline challenges deal with difficulties in teaching and learning data science, and stem from the interdisciplinary structure of data science.
Challenge 1: Interdisciplinarity
Data science is an interdisciplinary science laying in the intersection of three disciplines: computer science, mathematics & statistics, and the domain knowledge of the data (Berman et al., 2018). Due to this complex structure, not surprisingly, researchers have expressed many different views, opinions, and presentations regarding the exact structure of the field. Figure 1 reflects the common spirit of these diagrams. Based on this variety of perspectives on the structure of data science, a variety of data science curricula have been developed (Tang & Sae-lim, 2018). While the diagram seems to be symmetric, the actual balance required between the different topics in a data science program is still under debate.
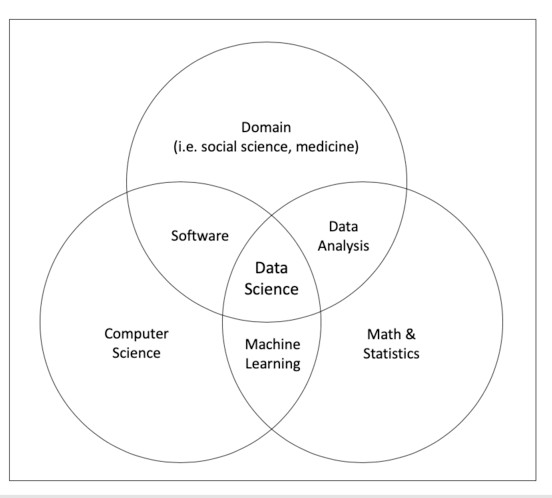
Figure 1. A Venn diagram for data science
Challenge 2. Data Domain
Although the data domain in the Venn diagram presented in Figure 1 is represented by only one circle, in practice, data science is relevant for many diverse domains, such as economics, education, psychology, medicine, and sports. Skiena (2017) notes that one of the basic principles of doing data science is the need to understand the domain of the data. This variety of domains, however, makes it difficult to integrate the domain knowledge into the curriculum and to convey the domain’s importance for solving data science problems to the students.
Challenge 3. Concept Comprehension
Educational research on the components of data science reveals that learners face difficulties when learning each of the component fields. The computer science education community is well familiar with challenges of teaching computer science. With respect to statistical thinking, the psychological research literature discusses many biases, one of which is the base-rate neglect which reflects the widespread fallacy of ignoring the base rate (the proportions of the different types within the population) when solving problems that require the use of Bayesian reasoning (Kahneman & Tversky, 1973). Bayesian reasoning is crucial, however, for data selection and interpretation of the results of machine learning algorithms, and the challenge is, therefore, how to increase (if at all possible) the learners’ awareness to their own biases.
Challenge 4. Cognitive Load
The cognitive load theory attempts to explain the interaction between our working memory and long-term memory when learning new concepts (Sweller, Van Merriënboer, Paas, van Merriënboer, & Paas, 2019). Our working memory is limited, unlike the capacity of our long-term memory, which is unlimited in comparison and is organized in schemas with different levels of complexity. Before a schema is stored in the long-term memory, it is first processed in the working memory.
Considering that students tend to be both novice programmers and novice statisticians and have almost no domain knowledge (Challenge 2), it follows that they have not yet constructed schemas of the main concepts in these fields. Since solving even a simple data science problem requires code writing and the calculation of statistical tests on data taken from some domain, it is reasonable to assume that novices experience a cognitive load since their working memory is required to deal with multiple items. When the cognitive load is too high, the cognitive resources needed for the construction of new schemas cannot be allocated and the learning process is affected.
Category 2 – Skills
Skill challenges refer to the skills required to become a professional data scientist.
Challenge 5. Non-Technical Skills
Among other things, data scientists are required to master non-technical skills, such as critical thinking, attentive reading, and effective communication. Ethics and research skills are especially important in data science and will therefore be discussed separately in the next paragraphs.
Critical thinking is a good example for illustrating the challenge of teaching and learning non-technical skills in data science education. For example, it is well known that models produced by machine learning algorithms are not always comprehensible (Elad, 2017). Elad writes that “in most cases, deep learning-based solutions lack mathematical elegance and offer very little interpretability of the found solution or understanding of the underlying phenomena”. Data science students must therefore use critical thinking when evaluating such machine learning models (which, as mentioned, sometimes are not easily understood).
Challenge 6. Ethics
The need for a professional code of ethics for data science stems from the use of personal data, continues through issues related to ownership of data, and ends with the responsibility for how they are used. Since ethical norms and standards are a vertical topic that should be integrated into any data science topic studied, the challenge is to find the correct balance between teaching it separately in specific courses (e.g., the edX course “Data Science Ethics” offered by the University of Michigan) and integrating it into all courses in appropriate situations (e.g., Saltz et al., 2019 and Grosz et al., 2019).
Challenge 7. Research Skills
Any meaningful work in data science includes the basic stages of a research project, which include asking research questions, gathering data, analyzing data, and presenting the results. Data science students should therefore acquire some research skills as part of their education as data scientists. Research skills, however, are usually acquired in graduate school or during the final stages of undergraduate studies. If we introduce data science at the undergraduate level, we should consider teaching research mindset and research methods as well. Specifically, issues such as deciding on the volume and type of data needed for the research and selecting and applying appropriate models and statistical tests, should be introduced into introductory data science courses.
Category 3 – Environment
The environment challenges of a data science program address the teaching methods and the diverse populations of data science learners and teachers.
Challenge 8. Real-Life Tasks
Since data science students are required to deal with domain knowledge (see Challenge 2), it seems that project-based learning (PBL) may be a suitable method for teaching data science. PBL is a teaching method that has learners solve problems taken from real life situations, and as such, it offers many advantages, including active learning and increased motivation (Ramamurthy, 2016). Nevertheless, the application of PBL in data science education introduces several challenges, such the project assessment, which is known to be a difficult task.
Challenge 9. Learners
The learner population, which is quite diverse, includes all future citizens and ranges from humanities and social sciences students, who have little or no background in computer science, math and statistics, through science majors in physics and chemistry, for example, who have a good mathematical background but limited computer science background, to engineering students, who have the needed background all around. Furthermore, data science students study in diverse educational settings: some attend formal frameworks (schools and universities), while others study in non-formal frameworks (such as meetups, boot camps, and MOOCs).
To gain a meaningful understanding of data science concepts, such as machine learning, an extensive computational and mathematical background is necessary. Didactic transposition is one mechanism that may be used to overcome a background gap, if such exists. In general, didactic transposition refers to the adaptation of professional knowledge to actual teaching situations (Chevallard, 1989). Since it is unrealistic to expect all learners to gain this background knowledge, we must didactically transpose such advanced content for different learner populations, as was illustrated in the context of computer science by Hazzan, Dubinsky and Meerbaum-Salant (2010).
Challenge 10. Data Science Teachers
Since data science is a young field, data science teachers today do not necessarily hold bachelor’s degrees in data science themselves, but rather come from diverse academic and industrial backgrounds. Thus, a tradition of data science pedagogy has not yet been shaped and its main teaching principles have not yet been formulated. Consequently, data science teacher preparation programs have not yet been developed and established.
Summary
This blog describes 10 challenges of data science education. Clearly, additional challenges and categorizations exist. Our research attempts to identify these challenges by exploring different teaching frameworks for different populations. We hope that this blog encourages the discussion about data science education.
References
Berman, F., Stodden, V., Szalay, A. S., Rutenbar, R., Hailpern, B., Christensen, H., … Raghavan, P. (2018). Realizing the potential of data science. Communications of the ACM, 61(4), 67–72. https://doi.org/10.1145/3188721
Chevallard, Y. (1989). On didatic transposition theory: some introductory notes. International Symposium on Selected Domains of Research and Development in Mathematics Education.
Elad, M. (2017). Deep, Deep Trouble. Retrieved August 31, 2019, from https://sinews.siam.org/Details-Page/deep-deep-trouble
Grosz, B. J., Grant, D. G., Vredenburgh, K., Behrends, J., Hu, L., Simmons, A., & Waldo, J. (2019). Embedded EthiCS. Communications of the ACM, 62(8), 54–61. https://doi.org/10.1145/3330794
Hazzan, O., Dubinsky, Y., & Meerbaum-Salant, O. (2010). Didactic transposition in computer science education. ACM Inroads, 1(4), 33–37. https://doi.org/10.1145/1869746.1869759
Kahneman, D., & Tversky, A. (1973). On the psychology of prediction. Psychological Review, 80(4), 237–251. https://doi.org/10.1037/h0034747
Ramamurthy, B. (2016). A Practical and Sustainable Model for Learning and Teaching Data Science, The 47th ACM Technical Symposium on Computer Science Education, SIGCSE 2016, 169–174.
Saltz, J., Skirpan, M., Fiesler, C., Gorelick, M., Yeh, T., Heckman, R., … Beard, N. (2019). Integrating Ethics within Machine-learning Courses. ACM Transactions on Computing Education, 19(4), 1–26. https://doi.org/10.1145/3341164
Skiena, S. S. (2017). The Data Science Design Manual. https://doi.org/10.1007/978-3-319-55444-0
Sweller, J., Van Merrienboer, J. J. G., Paas, F. G. W. C., van Merriënboer, J. J. G., & Paas, F. G. W. C. Cognitive Architecture and Instructional Design: 20 Years Later, 31 Educational Psychology Review § (2019). Educational Psychology Review. https://doi.org/10.1007/s10648-019-09465-5
Tang, R., & Sae-lim, W. (2018). Data science programs in U . S . higher education : An exploratory content analysis of program description , curriculum structure , and course focus, 32(2016), 269–290. https://doi.org/10.3233/EFI-160977
Orit Hazzan is a professor at the Technion’s Department of Education in Science and Technology. Her research focuses on computer science, software engineering and data science education. For additional details, see https://orithazzan.net.technion.ac.il/ . Koby Mike is a Ph.D. student at the Technion’s Department of Education in Science and Technology under the supervision of Orit Hazzan; his research focuses on data science education.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment