
I have been drawing versions of this picture for at least 15 years…
Credit: Doug Meil
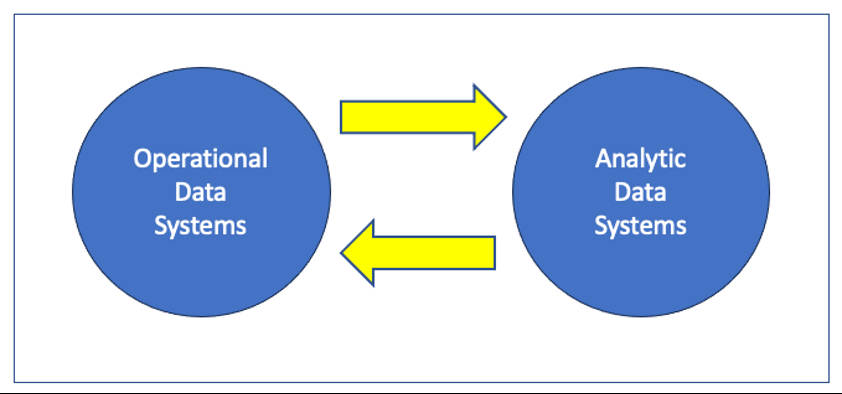
The picture represents the related but distinct use-cases of operational and analytic data systems, and I use this picture to frame conversations describing what the circles represent, the relationship between the two systems, and most importantly the challenges in implementation and management.
Operational Data Systems
Examples of Operational Data Systems include Enterprise Resource Planning (ERP) and other financial systems that most corporations use to manage things like contracts, purchasing, inventory, and payroll. In healthcare, these could be Electronic Medical Records (EMR) and other clinical systems. Device telemetry, ranging from the very small to the very large, continues to grow as an important source of data. Common attributes of Operational Data Systems are being systems of record for their respective functions, as well as data creators.
Analytic Data Systems
Operational Data Systems frequently come with built-in reports and analytic capabilities, and thus contain some functionality in the right-hand “analytic” circle, so to speak. But what if you want more? That’s where Analytic Data Systems come into use, which either combine and analyze multiple data sources, or provide additional analysis of a single source. Analytic Data Systems start as data consumers of Operational Data Systems and other reference sources, but then also generate new data points along the way.
Major components of Analytic Data Systems can include, but are not limited to:
Data Integration
Data integration is important because if there is no data there are no analytics.
Data Engineering
Data engineering is a catch-all phrase describing things that need to happen to prepare data for later use. When people make the joke “80% of data science is data preparation,” this (and data integration) is what they are talking about.
Data transformation (aka ETL – Extract Transform Load) is a major component of data engineering, particularly when conforming multiple sources of data into a common model.
Entity resolution is a fancy way of either consolidating and/or linking records, particularly from multiple sources. Well-known examples are customer and patient matching. A frequently quoted paper for entity resolution is A Theory For Record Linkage by Fellegi and Sunter (1969).
Temporal grouping of events is another common activity, and grouping events based on time boundaries for creating “sessions” is the go-to example for web-logs. A common example in healthcare is the calculation of episodes of care, which performs grouping of patient data over time but with specific diagnosis and treatment criteria.
Data augmentation is a large category that could include standardizing data to codesets or terminologies, utilization of Natural Language Processing (NLP) to generate more discrete data out of unstructured text, or the calculation of derived records (e.g., if one has height and weight observations, a BMI could be calculated).
Analytics
The phrase analytics is arguably even larger and vaguer than data engineering.
Reports and dashboards are arguably analytics, as well any summarizations prepared to support them.
Rule-based calculations are found throughout healthcare (e.g., clinical measures), are certainly a form of analytics.
The giant ever-increasing circle of machine learning algorithms is another example.
The list can assuredly go on. If one has data that is effectively prepared, one can analyze and slice and dice until the cows come home, and then some…
Challenges – Operational to Analytic Data Path
There are, of course, a few potential obstacles on the path to implementing Analytic Data Systems.
Access to Data – Technical
On-premise systems have their issues, but one issue tends not to be data accessibility. On the other hand, cloud-based vendor solutions can speed the customer onboarding process, but subsequent data integration can get much more complicated, and not always for the reasons that you might expect.
See “Vendor Solutions In A Cloudy World” for more details.
Access to Data – Governance
This is another case of “no data, no analytics,” but for compliance reasons. Just because data is technically accessible doesn’t necessarily mean it can be utilized for all analytic cases.
See “Data Governance And The Psychology Of Tension Management” for more details.
Data Infrastructure
Data engineers and analysts need a place to put their stuff. This is fortunately much less of a problem than it used to be a decade or so ago given advances in cloud computing, and the cloud data warehousing pattern of object stores for massive and relative cheap data storage combined with dynamically scalable query engines. The good news is there a lot of choices. The bad news is there are a lot of choices. Within an enterprise, it also leads to new and exciting problems—specifically, which data warehouse infrastructure, and on which cloud provider? The answer is as often political as it is technical.
Data Completeness and Cleanliness
Analytics are often the first time data from a source system has been reviewed comprehensively, which will raise concerns of Data Completeness and Cleanliness, two distinct but related topics. How many times is a particular attribute populated? And if predominantly non-null, what is actually in there? Be careful about making assumptions regarding what busy users will type in a text box.
At the extreme end of this spectrum, the source system might just be wrong despite all reasonable end-user efforts. See “The UK Post Office Scandal: Software Malpractice At Scale” for more details.
Batch vs. Streaming
Batch-processing vs. stream-processing is a never-ending topic, and one that data engineers love arguing about. Batch processing excels at comprehensive analysis, and stream-processing is needed when data needs to be processed now or now-ish. Both are valuable patterns and have their use-cases, so the answer might be one, the other, or both.
Testing
Are you sure the output is correct? Can you prove it? Data lineage is a big part of addressing these questions.
Scaling and Automation
Scaling and automation are two distinct but related topics.
Modern cloud-based data warehouse patterns have done much to provide technical scaling options. Cloud object stores offer near limitless storage. Frameworks like Apache Spark provide distributed processing capabilities. It doesn’t mean that wiring all this together will be easy, but it’s possible.
Process scaling is something else. There may be inherently single-threaded steps in the workstream. See “When Data Worlds Collide: Critical Sections In Analytic Workflows” for more details.
The lessons of DevOps/SRE are foundational concepts for process improvement. It’s not just about improving human efficiency, it’s about removing as much manual intervention possible, and this is best done with automation, which requires software engineers (or at least software skills).
Challenges – Analytic to Operational Data Path
Is Anybody Looking At The Results?
Analytic output without usage is the sound of one hand clapping. Without follow-up, even the best analytics will be for naught.
How Exactly Are Users Viewing The Results?
The details really matter on this. Sometimes the end-users of operational and analytic data systems are the same people, so whether there they have to tab between applications, or whether the different systems support single-signon is a big deal to their workflow. And don’t assume that just because an awesome dashboard exists that people know where to find it, even if they need it.
Operational Data Improvements
Remember all those oddball data values found above? It’s time to do something about them. There are two non-mutually-exclusive courses of action. The first involves providing feedback to users (and their managers) about how specifically a given system is actually being used, with some “please do” and “please do nots.” The second involves changing and improving the underlying system to expand capability as well as make it easier to use. Especially if the latter is vendor software, such improvements may take some effort, but one can dream.
In Conclusion
In highly effective environments, the operational and analytic data cycles never end. The best advice is to keep going. Erratic delivery is a confidence-eroding activity with stakeholders, and morale-draining for development teams. See “Anna Karenina On Development Methodologies” for more commentary on that.
References
- BLOG@CACM
- “When Data Worlds Collide: Critical Sections In Analytic Workflows”
- “Vendor Software Solutions In A Cloudy World”
- “Data Governance And The Psychology Of Tension Management”
- “The Need For Combined Data And Analytic Governance”
- “The UK Post Office Scandal: Software Malpractice At Scale”
- “Enabling AI Projects In An Enterprise”
- “Anna Karenina On Development Methodologies”
- Scaling & Automation
- Google Site Reliability Engineering
Doug Meil is a software architect in healthcare data management and analytics. He also founded the Cleveland Big Data Meetup in 2010. More of his BLOG@CACM posts can be found at https://www.linkedin.com/pulse/publications-doug-meil



Join the Discussion (0)
Become a Member or Sign In to Post a Comment