
The emergence of ChatGPT marked a transformative milestone for artificial intelligence (AI), showcasing the remarkable potential of large language models (LLMs) to generate human-like text. This wave of innovation has revolutionized how we interact with technology, seamlessly integrating LLMs into everyday tasks such as vacation planning, email drafting, and content creation. While English-speaking users have significantly benefited from these advancements, the Arabic world faces distinct challenges in developing Arabic-specific LLMs. Arabic, one of the languages spoken most widely around the world, serves more than 422 million native speakers in 27 countries and is deeply rooted in a rich linguistic and cultural heritage.12 Developing Arabic LLMs (ALLMs) presents an unparalleled opportunity to bridge technological gaps and empower communities. The journey of ALLMs has been both fascinating and complex, evolving from rudimentary text-processing systems to sophisticated AI-driven models. This article explores the trajectory of ALLMs, from their inception to the present day, highlighting the efforts to evaluate these models through benchmarks and public leaderboards. We also discuss the challenges and opportunities that ALLMs present for the Arab world.
Foundations of Arabic NLP
The story of Arabic natural language processing (NLP) began in 1985 when pioneers like Sakhr Softwarea tackled the unique challenges posed by Arabic’s rich morphology and complex syntax. Early systems, such as morphological analyzers, laid the groundwork for computational tools by addressing tasks like word segmentation and root extraction—critical for processing a language with intricate grammatical structures. As illustrated in Figure 1, the early 2000s saw the rise of statistical models, with techniques such as n-grams and word stemming being widely used for various natural language processing (NLP) tasks such as text classification, information retrieval, and machine translation. These models offered improvements over rule-based approaches but were constrained by limited data availability and struggled to generalize across Arabic’s diverse dialects and linguistic complexities. Despite these challenges, statistical methods provided a stepping stone for future innovations, setting the stage for more advanced approaches. The 2010s marked a paradigm shift with the adoption of deep language models, bringing with them powerful tools such as word embeddings and the Farasa Arabic word processing tool,b which significantly enhanced the accuracy and adaptability of NLP systems. Techniques such as LSTMs and CNNs enabled breakthroughs in sentiment analysis, machine translation, and dialect identification, allowing for more nuanced understanding of Arabic text. However, the inherent diversity of Arabic, including its numerous dialects and morphological richness, continued to pose challenges, underscoring the need for even more sophisticated and scalable models.

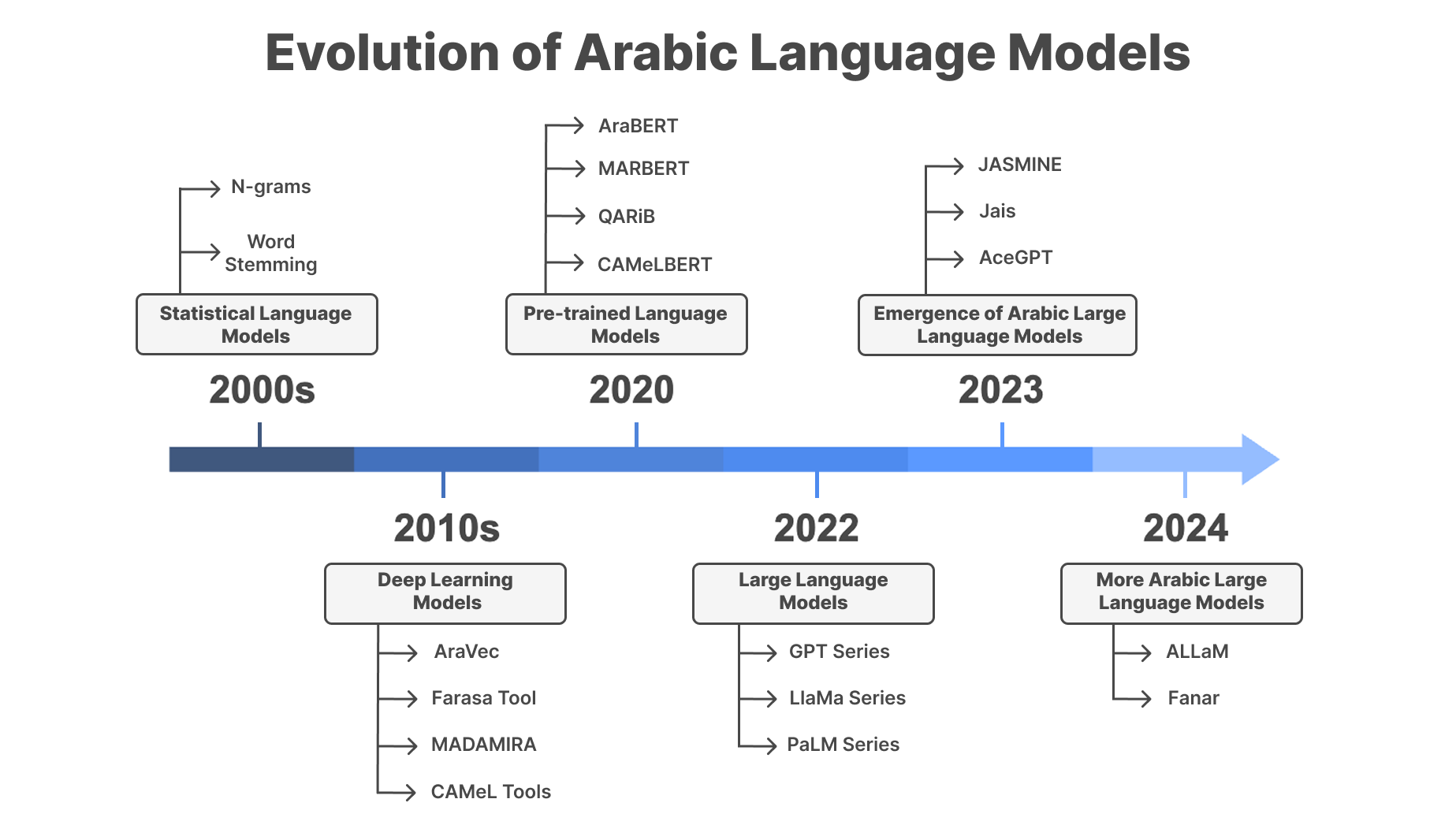
Figure 1. Evolution of Arabic language models.
The Rise of Transformers and ALLMs
Building on the challenges faced by earlier models in handling Arabic’s rich linguistic diversity, the advent of transformer architectures in 2017 marked a turning point for NLP. With the introduction of the self-attention mechanism, transformers offered a more robust framework for understanding the complexities of Arabic text, paving the way for a new era of Arabic-specific models. These architectures allowed models to better understand context and relationships within text, significantly improving performance across a wide range of tasks.
Among the most influential transformer-based models were bidirectional encoder representations from transformers (BERT), which revolutionized NLP by setting new benchmarks in understanding language nuances. Building on this success, specialized Arabic models such as AraBERT9 and QARIB1 were developed, significantly improving performance in tasks such as sentiment analysis, named entity recognition, and dialect identification. Additionally, tools such as CAMeLc and Farasad offered support for various Arabic language-processing tasks. These models became essential tools across a wide range of applications, showcasing the transformative potential of BERT-inspired architectures in Arabic NLP.
Following the release of ChatGPT in 2022, the Arab world saw significant advancements in Arabic language processing. Models such as JASMINE11 and Jais25 set new benchmarks for Arabic language understanding and generation. JASMINE excelled in commonsense reasoning and text-classification tasks, while Jais showcased advanced capabilities in instruction-response tasks. Jais-chat, a fine-tuned variant, demonstrated remarkable fluency in conversational contexts, and Atlas-Chat introduced optimizations for handling dialectal Arabic, particularly in casual and everyday use cases.
Newer models, such as AceGPT,16 ALLaM,10 Fanar,26 Peacock,7 and Dallah6 have expanded the scope of ALLMs further. AceGPT and ALLaM leverages reinforcement learning from AI feedback to enhance instruction-following and contextual understanding. Fanar specializes in understanding Arabic dialects and generative Arabic tasks while also being a multimodal ALLM, capable of handling both text and image-based tasks. Peacock, another multimodal ALLM, integrates visual and linguistic capabilities, demonstrating success in tasks such as visual question answering and image captioning.
These advancements stress the growing diversity in ALLMs, with each model tailored to address specific linguistic or cultural challenges. The taxonomy now spans general-purpose models, conversational agents, domain-specialized systems, and multimodal platforms, each contributing uniquely to the Arabic NLP ecosystem. Despite these advancements, challenges persist, such as the need for better handling of dialectal variations and contextual nuances. However, these models represent significant progress toward fully unlocking the potential of Arabic NLP.
Datasets and Benchmarks for ALLMs
Data acts as the cornerstone for building LLMs, serving as their linguistic and knowledge-based foundation. Various forms of datasets, such as those used for pretraining, supervised fine-tuning (SFT), and benchmarking, serve as the foundation for developing LLMs. As illustrated in Figure 2, ALLMs tackle a wide spectrum of downstream tasks, including language generation, understanding, classification, and social-cultural analysis. For ALLMs, a common trend has been adapting datasets originally created for English LLMs through translation. It is mainly due to the scarcity of digital Arabic content needed to train LLMs of substantial size (for example, several billion parameters). Another notable trend in ALLM development is the combined use of English and Arabic datasets. Additionally, some efforts incorporate code datasets to enhance the model’s reasoning capabilities.

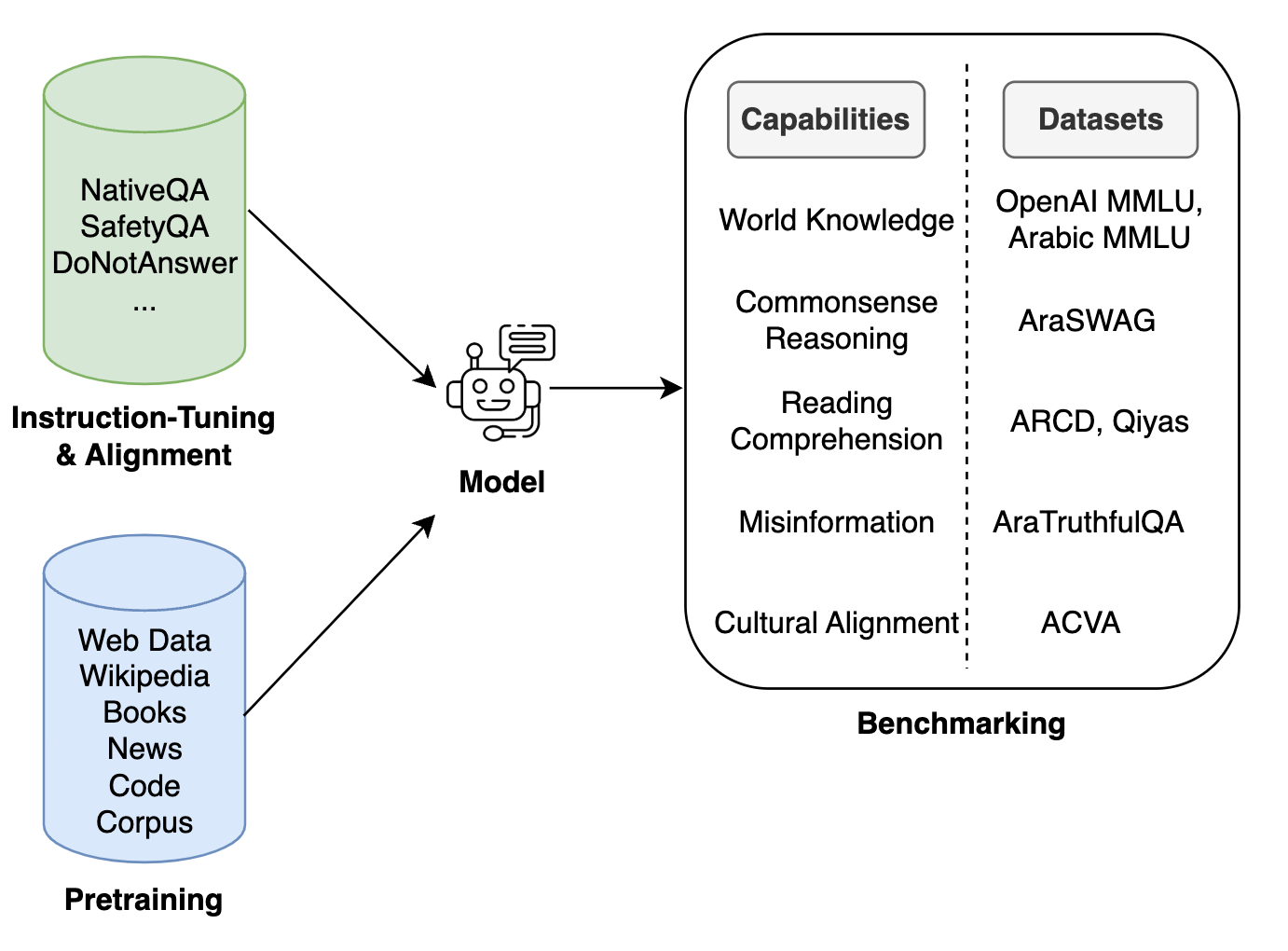
Figure 2. Overview of the various capabilities and downstream tasks tackled by ALLMs.
Pretraining. For pretraining, the datasets include Web content (for example, Common Crawl), Wikipedia, books, news, and code, covering a wide range of disciplines.19 Every ALLM development initiative curates, filters, and processes these datasets within their custom pipelines. A common practice across these initiatives is data de-duplication and various types of filtering (for example, Jais employs rule-based filtering, whereas Fanar uses syntactic, semantic, and model-based filtering). For machine translation, Fanar places greater emphasis on in-house systems for translating English to Modern Standard Arabic (MSA) and MSA to dialects. Additionally, efforts across different ALLMs have focused on including dialectal datasets to enhance their capabilities in handling Arabic dialects.e Although translating data can introduce Western cultural biases, developing ALLMs with billions of parameters would not have been possible without translated data. Moreover, models trained without translated data tend to exhibit higher training loss.10
SFT. Instruction tuning is essential for enabling an LLM to engage in dialogue-style interactions with users. Across all ALLM initiatives, the curation of SFT datasets often began with publicly available English datasets (for example, SuperNaturalInstructions,f Natural Questions,g P3,h xP3i), which were subsequently translated into Arabic.25,26 Some initiatives also developed their own inhouse datasets. For instance, Jais created NativeQA, a set of question–answer pairs focused on the UAE and the surrounding region, as well as SafetyQA and DoNotAnswer, to ensure the model avoids engaging in unsafe conversations, including discussions on self-harm, sexual violence, or identity attacks. For cultural alignment, relevant efforts include the development of CIDER to ensure alignment with Arabic norms.8
Benchmarking. Benchmarks play a critical role in evaluating language model performance across various tasks. For Arabic, benchmarks have evolved significantly over time, reflecting the increasing sophistication of models. Early benchmarks like AraBench23 focused on specific tasks, such as machine translation, while later benchmarks, such as ALUE,24 ARLUE,2 and ARGEN,20 offered broader evaluation scopes across multiple tasks. With the rise of ALLMs, specialized benchmarks emerged to assess advanced capabilities: ORCA for text classification,13 Dolphin for natural language generation,21 and benchmarks such as AlGhafa5 and Qiyas3 for multiple-choice evaluation.
Following this evolution, recent ALLM benchmarks increasingly focus on evaluating reasoning and domain-specific competencies. These benchmarks assess a wide range of capabilities, including World Knowledge (OpenAI MMLUj and ArabicMMLUk), Common Sense Reasoning (AraSWAG),11 MQA-KEAL4 Reading Comprehension (ARCD),l Misinformation (AraTruthfulQA),10 and Cultural Alignment capabilities (ACVA).16 Domain-specific benchmarks such as ArabLegalEval,15 as well as multimodal frameworks like CAMEL-Bench14 and Peacock,7 have further expanded evaluation possibilities. Manual human evaluation has gained significant attention, with approaches ranging from open-ended interactions to comparative assessments. For instance, Fanar’s benchmarking involved more than 300 testers from various Arab countries providing feedback, while ALLaM employed comparative evaluation between model responses. While standard NLP dataset evaluation has received less attention, community efforts through resources such as AlGhafa, LAraBench and LLMeBenchm are addressing this gap. Focusing on the dialectal evaluation of various capabilities of ALLMs, benchmarks such as AraDICEn leverage a post-edited machine-translation approach to curate data for MSA, Egyptian, and Gulf Arabic. Additionally, a cultural benchmark has been introduced alongside AraDICE, further enriching the evaluation.
Despite these advances, challenges persist, including limited dialectal representation and reliance on machine translations, highlighting the need for more authentic and diverse evaluation frameworks. Figure 3 visualizes the pipeline of training and evaluating ALLMs. It begins with the collection and preparation of pretraining datasets, followed by instruction tuning using SFT datasets. These steps result in an ALLM capable of various tasks, which are then assessed using a range of benchmarks. The figure highlights how pretraining and SFT are sequentially fed into the model, producing outputs that are later evaluated through task-specific benchmarks to ensure a comprehensive assessment of linguistic capabilities, reasoning, and cultural alignment.

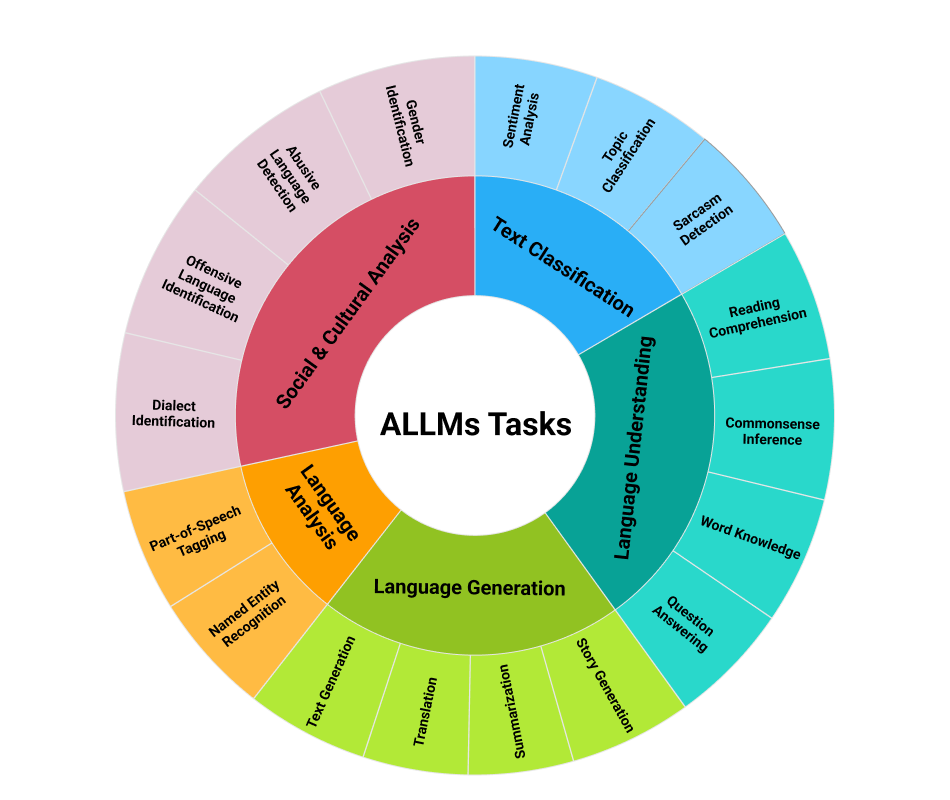
Figure 3. Pipeline for training and evaluation of ALLMs.
Challenges and Opportunities in Building Arabic LLMs
The development of ALLMs faces several interconnected challenges, which must be addressed to unlock their full potential. These challenges include data scarcity, dialectal variation, tokenizer inefficiencies, technical limitations, cultural and safety alignment, and human evaluation constraints. However, despite these obstacles, ALLM development presents transformative opportunities to bridge language technology gaps, foster regional collaboration, and create models that serve the diverse needs of Arabic-speaking communities. Below, we outline key areas where innovation and strategic action can drive progress.
Data scarcity. One of the most pressing challenges in developing ALLMs is data scarcity. Arabic lacks abundant, well-annotated resources, particularly for regional dialects and informal language use. A significant portion of Arabic knowledge remains undigitized, making it inaccessible for training large-scale models. Data limitations arise across three critical phases:
During pretraining, the limited availability of diverse, digitized text reduces the model’s foundational capabilities.
During instruction tuning, the scarcity of high-quality, task-specific annotated data hinders adaptability.
During alignment, the lack of culturally nuanced datasets makes it difficult to ensure ethical and safe AI behavior.
To address data scarcity, it is crucial to invest in comprehensive data curation initiatives that encompass MSA, Classical Arabic, and regional dialects to ensure a balanced and diverse dataset composition. Expanding the data pool requires digitizing undigitized Arabic knowledge, including manuscripts, oral traditions, and cultural archives. Additionally, developing targeted data pipelines for pretraining, instruction tuning, and alignment can help mitigate these challenges at each stage. Collaborative efforts between academia, industry, and government institutions can further enhance the availability of high-quality Arabic corpora, supporting the development of more robust ALLMs.
Handling dialects. Arabic consists of numerous regional dialects with distinct linguistic features. Since current models are primarily trained on MSA, they struggle to understand or generate colloquial or dialectal inputs. This limitation restricts the applicability of ALLMs for real-world use, as users frequently interact using dialects rather than MSA.
Addressing dialectal variations requires the inclusion of diverse dialectal datasets during both pretraining and fine-tuning stages. Leveraging dialect identification models and synthetic data-generation techniques can enhance dialectal coverage. Additionally, the development of multidialectal benchmarks would enable more effective evaluation of dialect-handling capabilities in ALLMs. Models fine-tuned on specific dialects, or equipped with zero-shot dialect adaptation techniques, could further enhance robustness in dialectal Arabic understanding and generation.
Cultural and safety alignment. The Arabic language is deeply intertwined with cultural and religious contexts. Models trained on Western-centric or multilingual data often fail to capture these nuances. While English data provides broader knowledge, it also introduces cultural biases that can misalign ALLMs with the values and expectations of Arabic-speaking communities. This misalignment can lead to inappropriate model outputs, misunderstandings, or even content that contradicts social and ethical norms in Arabic-speaking regions.
Improving cultural and safety alignment requires the adoption of advanced debiasing techniques to mitigate Western-centric biases introduced by English training data. Additionally, ensuring that ALLMs accurately reflect and respect Arabic cultural and religious values demands a stronger representation of culturally relevant content in training datasets. This can be achieved by incorporating region-specific guidelines, enhancing Arabic-specific content filtering, and involving native speakers in evaluation and alignment processes to refine model behavior.
Multimodality in Arabic. The development of multimodal ALLMs remains relatively underexplored, facing challenges related to data scarcity, dialectal diversity, and cultural misalignment. Most existing multimodal datasets are western-centric, limiting models’ ability to interpret Arabic-specific visual and textual content, such as traditional symbols, calligraphy, and region-specific attire. Additionally, dialectal complexity poses difficulties, as models trained on MSA struggle with spoken dialects in videos, advertisements, and social media.
Further, cultural biases in training data result in models that fail to align with Arabic social and ethical norms, leading to potential misinterpretations or inappropriate outputs. Addressing these challenges requires curating high-quality Arabic multimodal datasets that incorporate linguistic and cultural diversity. Initiatives like Peacock7 and Dallah6 represent early efforts but require expansion. Dialect-aware multimodal adaptation and culturally informed model alignment can enhance Arabic LLMs’ contextual understanding.
Discussion
Comparing advancements in Arabic and English LLMs. While ALLMs have made notable strides in language understanding and generation, they still lag behind their English counterparts in planning, reasoning, and agentic frameworks. Advanced English LLMs, such as GPT-4o and DeepSeek-V2, exhibit strong multi-step reasoning and problem- solving capabilities, enabling them to tackle complex mathematical, logical, and decision-making tasks. OpenAI’s recent o1 model, for example, integrates deliberation mechanisms to enhance reasoning, making it highly effective in structured problem-solving.
In contrast, ALLMs are still developing their commonsense reasoning abilities, as highlighted by efforts such as ArabicSense, MQA-KEAL, and AraDICE, which introduce benchmarks to improve reasoning performance. Similarly, planning capabilities—essential for breaking down and executing multi-step tasks—remain an area where ALLMs fall short. While navigation-based models such as NavGPT have demonstrated some progress in structured task execution with Arabic instructions, they still struggle with complex planning and reasoning-intensive applications.
Finally, agentic frameworks, which enable AI models to autonomously plan and execute actions with minimal human intervention, are still largely unexplored in Arabic NLP. A recent work explored planning and navigation tasks with instructions in both English and Arabic and demonstrate that some multilingual models struggle with reasoning and planning in the Arabic language due to limitations in their reasoning capabilities, poor performance, and parsing issues.17
Frameworks such as LangChain and AutoGPT, which have facilitated the development of AI-powered agents in English, do not yet have Arabic-adapted equivalents. Addressing these gaps will require dedicated research, dataset expansion, and tailored model training to ensure that ALLMs can match the sophistication of their English counterparts in these critical AI advancements.
Lessons from multilingual LLM initiatives. Efforts to develop LLMs for languages beyond English offer valuable insights that can inform ALLM development. Notable projects include SeaLLM for Southeast Asian languages22 and EuroLLM (for European languages).18 These models focus on addressing linguistic bias, enhancing cultural alignment, and optimizing resource efficiency for underrepresented languages.
SeaLLM, for example, extends vocabulary coverage and applies specialized instruction tuning to improve its understanding of Southeast Asian languages while respecting local norms. EuroLLM focuses on multilingual tokenization, balancing language representation, and improving translation across diverse European languages. ALLMs can benefit from these initiatives in several ways. First, extended vocabulary and specialized fine-tuning could enhance Arabic dialect representation. Second, comprehensive data collection and multilingual tokenization would help Arabic LLMs better capture linguistic nuances. Lastly, cultural and legal alignment techniques from these models could improve ethical considerations in Arabic AI systems.
The societal impact of Arabic LLMs. Despite these challenges, ALLMs hold significant potential across multiple sectors, offering transformative applications in education, governance, healthcare, and cultural preservation. In education, they can enhance language learning, bridge literacy gaps, and democratize knowledge accessibility. In governance, they can improve public service delivery, streamline communication, and support e-governance initiatives. In healthcare, they can enable language-specific solutions such as medical transcription and effective patient communication in Arabic. Moreover, in cultural preservation, these models can digitize and preserve endangered dialects and oral traditions, contributing to heritage conservation.
However, realizing this potential requires overcoming several barriers, including the availability of high-quality, domain-specific datasets; ethical considerations in AI-driven governance; and ensuring the accuracy and reliability of medical applications. Additionally, the cultural sensitivity of ALLMs remains a key concern, particularly in educational and governmental use cases, where misinformation or bias could have significant consequences. Addressing these challenges will require ongoing research, interdisciplinary collaboration, and region-specific adaptation of AI policies to ensure ALLMs can serve these domains effectively and responsibly.
Building a sustainable Arabic AI ecosystem. Achieving this societal impact requires a strong and sustainable Arabic AI ecosystem. Despite recent progress, limited regional collaboration and infrastructure across Arabic-speaking countries continue to hinder large-scale development. While resource-rich nations have invested in AI research, the absence of a cohesive research network and weak industry-academia integration prevent widespread progress. Additionally, the challenge of attracting and retaining AI talent in the Middle East further limits local expertise, leading to a reliance on external research initiatives rather than homegrown advancements.
A key step to overcoming these barriers is the establishment of a collaborative AI ecosystem. A pan-Arab data consortium could facilitate the sharing of resources, datasets, and infrastructure, allowing researchers across the region to contribute to and benefit from large-scale ALLM development. Strengthening partnerships between governments, academic institutions, and industry leaders can help bridge infrastructure gaps and accelerate innovation.
Equally important is the development and retention of AI talent. To ensure a steady pipeline of skilled researchers and engineers, the region must invest in regional AI education and training programs. Establishing AI research centers, offering competitive funding, and creating career pathways for AI professionals will encourage local talent to remain and contribute to the Arabic NLP field. Furthermore, fostering international collaborations while ensuring local expertise is developed will be key to advancing ALLM capabilities in the long term.
Regional collaboration in AI development. Regional collaboration has played a crucial role in advancing LLMs for non-English languages, enabling resource-sharing and joint development across multiple nations. The SeaLLM initiative in Southeast Asia and EuroLLM in Europe serve as strong examples of how cross-border cooperation can enhance multilingual AI systems.
SeaLLM was developed through collaboration between Southeast Asian nations, pooling resources, sharing datasets, and co-funding research to create a multilingual model tailored to the region’s linguistic diversity. This collective effort ensured high-quality representation for languages with limited AI infrastructure, allowing for more inclusive language technology. Similarly, EuroLLM focuses on supporting the official languages of the EU, optimizing multilingual tokenization and balancing language representation to create a model that effectively serves diverse linguistic communities.
Arabic AI research has seen significant advancements, with multiple institutions and organizations contributing to the growth of ALLMs. However, unlike coordinated initiatives such as SeaLLM and EuroLLM, most efforts in the MENA region are being developed independently, leading to opportunities for stronger regional collaboration. Given the shared linguistic and cultural heritage across Arabic-speaking countries, a pan-Arab AI consortium could further enhance cooperation by centralizing dataset curation, optimizing computational resources, and aligning research priorities. By fostering data-sharing agreements, joint model development, and regional funding opportunities, the MENA region can build on its existing progress to drive large-scale ALLM advancements. Strengthening cross-border research networks and leveraging shared linguistic resources would significantly enhance Arabic AI’s scalability and impact, ensuring models that better serve the diverse needs of Arabic-speaking communities.
Ensuring responsible development and evaluation of Arabic LLMs. As ALLMs continue to evolve, their development must be guided by responsible and culturally aware evaluation frameworks. Establishing culturally and linguistically appropriate benchmarks is essential for assessing model performance and ensuring that ALLMs align with the linguistic diversity of the region. To complement this, scalable frameworks for human evaluation should be developed, incorporating feedback from native speakers and domain experts to refine model outputs.
Additionally, technological advancement must be balanced with cultural sensitivity to create inclusive models that effectively serve Arabic-speaking communities. Given the sociocultural diversity of the Arab world, regional cooperation is necessary to align AI advancements with the ethical, linguistic, and societal needs of different populations. By prioritizing both innovation and cultural awareness, ALLMs can be developed in a way that maximizes their societal benefits while minimizing potential risks.
Bridging the research-to-market gap in ALLM deployment. The transition from ALLM research to industrial applications faces significant challenges despite research advances. Most deployments remain limited to narrow tasks rather than comprehensive commercial applications, with models such as ALLaM and Jais being exceptions rather than the norm. This gap stems from high computational demands exceeding regional business resources, integration challenges with existing systems, and the absence of standardized evaluation frameworks for real- world performance metrics.
This limited adoption creates a cyclical problem where sectors that could benefit substantially, such as healthcare, education, and customer service, continue using legacy systems instead of advanced language models. Bridging this gap requires developing deployment-optimized model variants, creating industry-specific benchmarks reflecting real-world requirements, and fostering collaborative ecosystems to transform promising research into commercially viable products serving Arabic-speaking communities.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment