
Applied Data Mining to Product Reviews
When it comes to big data, one of the greatest things we can do as computer scientists creating products is to distill all the information down to what is important.
Of course the challenge with these sorts of problems always lies in the details. This article goes into a few of the challenges associated with applying data mining to product reviews.
If you aren’t familiar with Decide.com, we are a startup that applies machine learning and algorithms to help predict prices and models of products to answer “when to buy” and now we have rolled out our first version of “what to buy” Decide Score, which would measure the relative value and quality of the product
Let’s get into the details of this new “what to buy” Decide Score, since that is what is interesting.
The goal of the project was simple:
Create an easy-to-understand score for helping people find what-to-buy from expert and user reviews collected from many sources from all over the web.
At first glance, this may seem simple: collect a bunch of reviews and then mash them together to create a score. But there are some nuances, which make this difficult, so let’s go through each step.
Collecting all the data from many different sources, in many different formats.
Of course that problem can be solved with some basic normalization and data scrubbing, so I won’t elaborate more on this point. If you want to read more on data collection, you can check out this post on some crawling basics.
Matching each review to the “right” product.
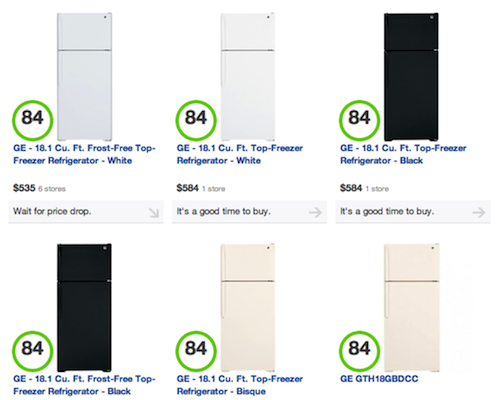
Normalizing model names and product titles can be a challenge (for example, in the image below there are many different model names for the Sony Bravia TV).

And this can be exacerbated in some categories like Tablets, where and iPad can be 3G, wireless, or have different amounts of storage. One could just apply the reviews to each specific product, but then it would be possible to end up in a world where different variants of the same product had different scores (which should be downright confusing to end users).
So the first step in this process is to use machine learning to group products together based on similarities in their names and descriptions.
Handling different types and sources of reviews.
All reviews are not created equal. An easy delineation was for us to separate the user from the expert reviews. In our calculation we consider expert and user reviews as 2 different sources (even if from the same site) and this is because each can be weighted differently given the inherent credibility and trustworthiness of the sources.
And since each review source has a bias, it is necessary to normalize the scores so inputs are consistent. For example, reviews on the Home Depot website are generally higher (an average rating of 4.2) versus other sites, such as CNet which has an average of 3.5 for expert reviews. So it is necessary to normalize both the user and expert reviews.
An example of this process shown below:
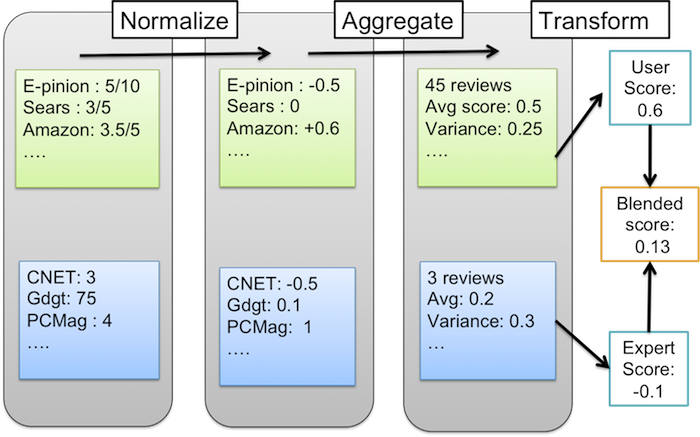
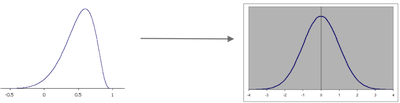
User and expert reviews are treated separately and then normalized to remove bias, and then finally aggregated into the score. With each input being normalized to an average of 0, and standard deviation of 1 (so it is a normal distribution as shown in the image). And this blended score can them be used to create the Decide Score using a weighting scheme.
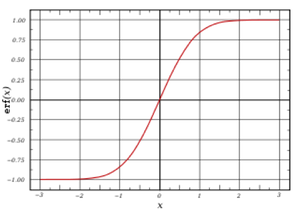
And then finally all of those values are processed with a sigmoid function to get a more human readable score out of 100. We have parameterized the function to set the mean score as 70 and two standard deviations above the mean to be a 95. And this is done separately for each product category to get the following consistent score criteria:
- Average score per category = 70
- Really good product = 95
- Max score 100
- Min score 0
Making Decide Scores smarter
And that all seems well and good, but since you are good at math you may be asking yourself some questions (or at least we asked ourselves these questions) –
- How do we account for the number of reviews for a product? Products with very few reviews (such as newly released products) may end up having scores that are disproportionately high or low because of the limited data set.
- How do we account for variance in the review scores of a product? If a product A and B have the same average review rating, but opinions on A are more polarized, then we may want to rate B higher.
- How do we deal with product age? Newer products may not have as many reviews as older ones. As older products move towards the end of their lifecycle we should not rate them highly as newer version, even if they are as well-reviewed.
Since we are in the business of recommending what to buy (which often is a newer model) it was critical we address these problems. In addition, user and expert reviews tend to have different characteristics. The number of user reviews for a product tend to be much greater than the number of expert reviews. And high quality expert review sources tend to be more credible. Consequently, we use a different set of techniques to deal with these issues for these two types of review sources.
Being smarter about user reviews
The way we deal with both variance and limited sample size in analyzing user reviews is to calculate the confidence interval of the average rating via a standard error calculation. This confidence interval is expressed as a lower and upper bound of the average review rating.
Products with fewer reviews and/or higher variance in review scores will naturally have a wider gap between the lower and upper bound. We use the lower bound of this confidence interval as our aggregate user contribution to the decide score. Note, we can run into situations where there is 0 measured variance in the set of user reviews (e.g. product has only 2 reviews, both 5-stars). To handle this, we add a small number of artificial reviews to every product before performing this calculation.
The way we handle product age in dealing with user reviews relies on a basic assumption. Products that are nearing the end of their lifecycle will have fewer reviews relative to their peers, and recent review scores are more relevant than older ones. Consequently, if we only look at recent reviews when calculating the lower bound on the confidence interval, our standard error measurement naturally degrade as products become less relevant to the average consumer.
Being smarter about expert reviews
Unlike user reviews, it is unlikely that we will see multiple expert reviews with the exact same 5 star rating (and if we did, at least those sources are more credible). However, the number of expert reviewers in any particular category is much smaller, and they may be published a month or further after a product has been released.
Consequently, we have two main challenges with creating an average expert rating. First, we want to reward products that have more expert reviews (we’re more confident in a product with 2 4-star expert reviews than a product with only 1 4-star review). Second, we don’t want to penalize newer products unduly before their expert reviews are published.
To deal with the first concern, we artificially inject artificial expert reviews and calculate an average expert rating based on the combined set of artificial and real review ratings. In machine learning parlance, we calculate an m-estimate of the average review rating.
To deal with the second concern, the number of artificial reviews that we inject is dependent on the age and category of the product. This way newer products may not need as many expert reviews to get the same expert contribution as an older product with more expert reviews.
In Summary
Of course this is an algorithm and methodology we are working on improving, but it is just one application of many different ideas in data mining that can be applied to generate real consumer value.
If you have suggestions, thoughts, or ideas, please leave them in the comments.
A special thanks goes to three amazing data scientists–Dave Hsu, Hsu Han Ooi, and Sam Clark– for reviewing and contributing to this post and the innovation behind it.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment