A glance around any operating theatre reveals many visual displays for accessing pre- and intra-operative images, including computer tomography (CT), magnetic resonance imagery (MRI), and fluoroscopy, along with various procedure-specific imaging applications. They support diagnosis and planning and provide a virtual “line of sight” into the body during surgery. Although surgeons rely on the capture, browsing, and manipulation of these images, they are constrained by typical interaction mechanisms (such as keyboard and mouse).
Key Insights
- Beyond demonstrating technical feasibility, touchless interaction in surgery should be designed to work within operating-theatre practices.
- Gesture design should consider not only individual interaction with medical images but how they are used in the context of collaborative discussion.
- Gesture design across one and two hands should accommodate expressive richness, as well as the surgeon’s hands, but is constrained by the close proximity of the surgical team and movement restrictions due to sterile practice.
At the heart of the constraints is the need to maintain a strict boundary between what is sterile and what is not. When surgeons are scrubbed and gloved, they cannot touch these input devices without breaking asepsis. To get around it, several strategies are available for interacting with images, though they are often not ideal; for example, surgeons commonly request other members of the surgical team (such as radiographers and nurses) to manipulate images under their instruction.7,11 While it can succeed, it, too, is not without complications. Team members are not always available, producing frustration and delay. Issuing instructions, though fine for relatively discrete and simple image-interaction requests, can be cumbersome and time consuming. More significant, indirect manipulation is not conducive to the more analytic and interpretive tasks performed by surgeons using medical images. The way they interact with, browse, and selectively manipulate them is closely bound up with their clinical knowledge and clinical interpretation.
Research shows surgeons need direct control of image data to mentally “get to grips” with what is going on in a procedure,7 something not achievable by proxy. For direct hands-on control, some clinicians pull their surgical gown over their hands, manipulating a mouse through the gown.7 The rear of the gown, which is non-sterile, touches the mouse (also non-sterile), while the front of the gown and the hands, which are sterile, remain separated from those surfaces (see Figure 1). Such practices are not risk free. For non-invasive procedures, these practices are considered justified due to the clinical benefits they bring in terms of time savings and direct control of the images. For more invasive procedures, such practices are less appropriate. In circumstances where surgeons need hands-on control of images, surgeons must remove gloves and rescrub, taking precious time. For long procedures, possibly involving multiple occasions for interacting with images, the procedure can be delayed significantly, increasing both financial cost and clinical risk.
Giving surgeons direct control over image manipulation and navigation while maintaining sterility within the operating theatre is a key goal,20 one that has captured the imagination of research groups and commercial entities worldwide. For some, the approach is to insert a barrier between the sterile gloves of the surgeon and a nonsterile interaction device (such as IDEO’s optical mouse-in-a-bag solution5). While such solutions reflect a certain elegance in their simplicity, there remain certain practical concerns at the patient bedside. In addition, barrier-based solutions involve certain inherent risks due to the potential for damage to the barrier. Other approaches have sought to enable interaction techniques in the operating theatre that avoid the need for contact with an input device altogether. The seeds of this interest were in evidence in the mid-2000s when computer-vision techniques were first used for controlling medical-imaging systems by tracking the in-air gestures of the surgeon. Graetzel et al.,4 in an early example of touchless medical imaging, let surgeons control standard mouse functions (such as cursor movement and clicking) through camera-tracked hand gestures. Shortly afterward, more sophisticated air-based gestures were used for surgical-imaging technology in the form of Wachs et al.’s Gestix system.21 Rather than just emulate mouse functionality, Gestix introduced possibilities for more bespoke gesture-based control (such as for navigation, zooming, and rotation).
These initial systems paved an important path, and, more recently, the number of systems and research efforts considering touchless control of medical images for surgical settings has grown significantly, as covered by Ebert et al.,1,2 Gallo,3 Johnson et al.,7 Kipshagen et al.,9 Mentis et al.,11 Mithun et al.,13 O’Hara et al.,15 Ruppert et al.,16 Stern et al.,17 Strickland et al.,18 and Tan et al.19 One enabler of this growth is the Kinect sensor and software development kit,12 which has lowered barriers to entry, including financial cost, development complexity, and need to wear trackable markers. The Kinect sensor is based on a laser and horizontally displaced infrared (IR) camera. The laser projects a known pattern onto the scene. The depth of each point in the scene is estimated by analyzing the way the pattern deforms when viewed from the Kinect’s IR camera.
When scene depth is estimated, a machine-learning-based algorithm automatically interprets each pixel as belonging to the background or to one of the 31 parts in which the controlling person’s body has been subdivided. This information is then used to compute the position of the “skeleton,” a stickman representation of the human controller. Kinect has helped overcome some of the inherent challenges of full-depth skeleton capture with purely camera-based systems. With this range of systems, common themes have emerged, along with opportunity to explore a more diverse set of approaches to this particular problem area of touchless interaction during surgery. The concern is no longer to demonstrate the technical feasibility of such solutions but how to best design and implement touchless systems to work within the particular demands and circumstances that characterize practices in the operating theatre. Reflecting them, and with the growing interest in the technology, we highlight some lessons learned, as well as issues and challenges relevant to the development of these systems, beginning with key projects.
A leading example involves the system used for multiple kinds of surgery at Sunnybrook Hospital in Toronto18 in which a Kinect helps navigate a predefined stack of MRI or CT images, using a simple constrained gesture set to move forward or backward through the images and engage and disengage from the system, an important issue revisited later.
Any image transformation (such as rotating, zooming, or other parameter adjustments) is not available in the system unless these manipulations are integrated into the predefined image stack. The simplicity of the Sunnybrook system reflects a genuine elegance. The limited number of gestures yields benefits in terms of ease of use and system learnability. Such a constrained-gesture set can also offer certain reliability benefits: enabling use of reliably distinctive gestures while avoiding “gesture bleed,” where gestures in a vocabulary share common kinaesthetic components, possibly leading to system misinterpretation. Given that the system is one of only a few actively deployed and in use today, such reliability concerns are paramount in the design choices made by its developers. Note, too, adoption of two-handed gestures in the design of the gestural vocabulary, a technique that can yield certain benefits, as well as constrain the way the system is used in surgical contexts, a key theme covered later.
While the Sunnybrook system reflects elegant simplicity, such an approach must also address inherent limitations. Interaction with medical images in surgical settings often extends beyond simple navigation, requiring a much richer set of image-manipulation options beyond rotate/pan/zoom to potentially include adjustment of various image parameters (such as density functions to reveal features like bone, tissue, and blood vessels, and opacity). Such possibilities may even include marking up or annotating images during procedures. Moreover, manipulation may apply to whole images or more specific regions of interest defined by the clinician. With these possibilities in mind, several recent projects involving Kinect-based touchless interaction with surgical images have developed a much larger gesture set to accommodate the increased functionality, as well as to interface with standardized open source Digital Imaging and Communications in Medicine (DICOM) image viewers and Picture Archive and Communication System (PACS) systems (such as Medical Imaging TOolkit and OsiriX). Notable examples are systems developed by Ebert et al.,1,2 Gallo et al.,3 Ruppert et al.,16 and Tan et al.19
Incorporating these richer functional sets is impressive but involves notable challenges. One concerns the notion of expressive richness, or how to map an increasingly large set of functionalities (often involving the continuous adjustment of levels of a parameter) onto a reliably distinctive gesture vocabulary. Several approaches have been applied in these systems (such as use of modes to distinguish gestures and input modalities, including speech and composite multihanded gestures). For example, using one- and two-handed tracking not only yields the benefits of bi-manual interaction but enables a richer set of expressive possibilities. In both Ebert et al.1,2 and Gallo et al.,3 the gesture set employs both one- and two-handed gestures. Different gesture combinations (such as single-hand, two hands together, and two hands apart) can then be used to denote particular image parameters that can be adjusted according to their respective positioning in the x, y, and z planes. More recent versions of the Ebert et al.1 system include further expressive capabilities through algorithms that recognize more finger-level tracking in which spread hands are distinguishable from, say, open-palm hands.
Along with the larger gesture sets enabled by this expressiveness comes concern over the learnability of the systems,14 particularly as new system functionalities may have to be accommodated. We see attempts to deal with these issues in the systems of Ruppert et al.16 and Tan et al.,19 building up compound gestures that combine dominant and non-dominant hands in a consistent and extendable way. The non-dominant hand is used for selecting particular functions or modes, while the dominant hand moves within the x, y, and z planes, for the continuous adjustment of image parameters. In this way common gestures can be applied across a range of functionalities, making the system more learnable and extendable.
It is not so much that more than one person wants to control images simultaneously but that sometimes one person must be able to fluidly hand over control to another person.
What emerges is the use of one- and two-handed gestures as an important theme in the design and understanding of touchless medical systems we pick up again later. In particular, while the varied approaches appear to be motivated by certain control pragmatics (such as need for expressive richness and learnability), what is not apparent is how particular design decisions are motivated by principles of bimanual interaction design10 or more significantly the broader set of socio-technical issues that arise when considering how these systems might be used in the context of an actual surgical procedure.
Another possibility is the use of voice recognition, as seen in the work of Ebart et al.2 and in our own work.15 However, voice-recognition software involves special challenges in noisy operating theatres so, when used in isolation, may not be suitable for manipulation of continuous parameters. But most significant in the use of voice in these systems is how it can be combined with gestural modality to achieve control; for discrete actions and functions (such as changing mode and functionality) voice control could deliver important benefits.
Socio-technical Concerns
A central concern goes beyond simply developing touchless control mechanisms to overcome sterility requirements. First, they need to be situated in the context of working practices performed by the surgical team and in the setting of an operating theatre. Such settings and practices shape and constrain system design choices involving, say, tracking algorithms, gesture vocabulary, and distribution of interaction across different input modalities, including voice and gesture. While many of the systems discussed here were developed in collaboration with and successfully used by clinical partners, the rationale behind their design choices often remains implicit with respect to the settings and work practices in which they are deployed. As the field grows, it is worth reflecting on these issues and making them more explicit. To do this we draw on our experience developing a system for use in vascular surgery and how its design choices relate to particular socio-technical concerns following observations in the operating theatre. The focus on our own experience is for illustrative purposes, our intention being to highlight lessons for the broader set of technologies we discuss.
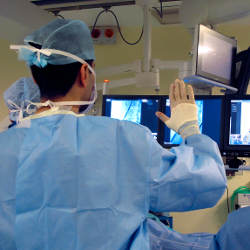
The system we developed was for use during image-guided vascular surgery at Guy’s and St. Thomas’ Hospital (GSTT) in London, U.K. During such a procedure, the surgeon is continuously guided by live fluoroscopy and x-ray images on a bank of monitors above the patient table. On one of them, a volumetric rendering of the aorta (from preoperative CT data) is overlaid on continuously updated x-ray images to help the surgeon visualize where the inserted wires and stents are located with respect to the actual structure of the aorta. This combined overlay is manipulated through the system’s Kinect-based gesture and voice recognition (see Figure 2 and Figure 3).
In designing the system we had to address notable socio-technical concerns with broader significance for how to think about system development, including collaboration and control, engagement and disengagement, and image inspection with one hand, two hands, and hands-free.
Collaboration and control. In many systems, the design focus is on providing a single point of control for the surgeon in the operating theatre. While this remains an important goal, surgery involves significant collaborative aspects of imaging practices (such as in Johnson et al.7 and Mentis et al.11). It is not so much that more than one person wants to control images simultaneously but that sometimes one person must be able to fluidly hand over control to another person; for example, if the surgeon is busy with the procedure and patient management, other clinical support may have to assume control of the images. Other times, the clinician leading the procedure might hand over certain responsibilities to a specialist or trainee. A second significant collaborative issue concerns collaborative clinical interpretation and discussion in which the various members of the surgical team point and gesticulate around the displayed images.
In the GSTT system we sought to address them by tracking the skeletons of multiple team members, using color-coding to give them a distinct pair of cursors corresponding to their hands. This color-coding of cursors allows collaborators to point and gesticulate at different parts of the image as they discuss, interpret, and plan an appropriate course of action. At any point, they can raise their hands and issue a spoken command to request control of the system so, as with the other systems covered here, there is a notion of a single dominant controller of the images. However, even in this mode, other team members can point and gesture through visible cursors, assuming control at any time through voice command, if required by the procedure.
System engagement, disengagement. Gesturing before a screen is not always for the purpose of system control. Along with gesture in support of conversation, movement before a screen may result from other actions performed in the context of the procedure or as the surgeon attempts to transition between gestures. These actions raise the possibility of the system inadvertently recognizing them as system-control gestures. Key in the design of the systems then is the need for mechanisms to move between states of system and engagement and disengagement, reinforced with appropriate feedback to signal the system state.
Multiple approaches are seen in various systems, each bringing its own set of pros and cons; for example, in the Sunnybrook system,18 the developers incorporated a deliberately unusual gesture above the head to engage/disengage the system. Such a gesture is not likely to occur in the course of other activity so can be considered useful in terms of avoiding inadvertent triggering. In developing our system, we tried a number of approaches with varying success; for example, to engage the system to recognize gestures, we initially used a right-handed “waving” gesture that suffered from “gesture transition,” whereby the movement necessary to initiate the hand-wave gesture was sometimes recognized as a discrete gesture in and of itself.
This misinterpretation relates to the notion of “gesture spotting,” or detection of the start and end points of a gesture through low-level kinaesthetic features (such as acceleration8). While gesture-spotting techniques are improving, it remains an inherently difficult challenge for system developers. One way to address it is through non-classification-based techniques, whereby continuous image parameters correspond to continuous positioning of the controller’s hands. But such approaches are prone to the gesture-transition problem for a multiple reasons (such as when parameter adjustment extends beyond the reach of natural arm movements in either plane and particular areas of the screen are used for additional feature access). To address them, we incorporated a clutching mechanism in which arms are withdrawn close to the body to declutch the system, allowing movement transition without corresponding image manipulation by the system.
We also adopted a time-based lock in which surgeons hold their hands in position for a few seconds. While successful in other domains of gestural interaction, our evaluations with surgeons found a natural tendency for them to pause and inspect the image or hold a pose to point at a specific feature in the image. These behaviors clashed with the pause-based lock gesture, leading us to modify the system so engaging and disengaging control is achieved through a simple voice command that complements the gesture vocabulary and works well when a discrete change of state is needed.
Other developers have also explored automatic determination of intention to engage and disengage from a system; a good example is the work of Mithun et al.,13 discussing contextual cues (such as gaze, hand position, head orientation, and torso orientation) to judge whether or not a surgeon intends to perform a system-readable gesture. Such approaches show promise in avoiding unintentional gestures, though determining human intent on the basis of these cues remains a challenge; for example, contextual cues are likely to be similar when talking and gesticulating around the image during collaborative discussion (such as when intending to interact with the system).
One hand, two hands, hands-free. Some systems discussed here make use of both one- and two-handed gestures. Besides increasing the richness of gesture vocabulary and exploiting important properties of bimanual action during interaction, important clinical considerations are at play in the ways systems are designed for one or two hands; for example image interaction is sometimes needed when a surgeon holds certain medical instruments, raising questions as to how many hands are available to perform certain gestural operations at a particular moment. The design of the gestural vocabulary is not just a question of having the right number of commands to match functionality but also how to reflect the clinical context of use as well.
Our GSTT system uses a range of one- and two-handed gestures. For panning and zooming an image, our observations and interviews with surgeons suggested these manipulations are typically done at points when instruments and catheter wires can be put down. For fading the opacity of the overlay and annotating the overlay with markers (such as to highlight a point of correspondence on the underlying fluoroscopy image), the surgeon may be holding onto the catheter, thereby leaving only one hand free. For these clinical reasons the system uses two-handed gestures for panning and zooming, but for opacity fading, the gesture can be performed with the hand that is free. For marking the image overlays the system combines one-handed tracking with a voice command, allowing the command to be carried out while holding the catheter.
This is not to say touchless control should be available at all times clinicians are using other instruments. There are indeed many points in a procedure when image manipulation could be a distraction to the task at hand. But there are opportunities for a combination to be considered by system developers; as a consequence, the specification of gesture vocabulary across both hands must be defined with clinical significance. Different kinds of surgical procedures clearly involve different constraints in terms of how and when image-manipulation opportunities can be combined with the use of surgical instruments, thus calling for careful consideration of how to accomplish input, especially when both hands may be holding instruments. In such circumstances it might be possible to exploit voice commands for hands-free manipulation (providing they are suitable to the discrete properties of voice commands) or combine voice with other input (such as foot pedals, gaze input, and head movement). The point is when designing these systems developers must take an approach based not simply on technical but also on clinical demands as to whether one, two, or no hands are free for image interaction.
At the operating table, away from the operating table. This points to another important consideration—the physical location of surgeons when they need to interact with different imaging systems (see Figure 4). Aside from the use of tools at the operating table, the operating table can be a crowded environment, with surgeons often in close proximity to other members of the surgical team. Not only can this affect a system’s approach to tracking but also impose constraints on the kinds of movement available for gesture design (such as physical restrictions of working in close proximity to others and those due to strict sterile practice). In sterile practice, hand movements must be restricted to the area extending forward from the surgeon’s torso between the hips and chest level; shoulders, upper chest, thighs, and back are considered greater risks for compromising sterility, so movements in these areas (and thereby gestures) must be avoided. Moreover, the operating table itself hides the lower half of the surgeon’s body, while away from the table the surgeon reveals more of the whole body to the tracking system. Kinect offers two tracking modes: default, optimized for full-body-skeleton tracking, and seating, optimized for upper-torso tracking (head, shoulders, and arms). While full-body tracking suits the situation in Figure 4a, the upper torso-tracking mode is better suited for the one in Figure 4b.
The surgeon’s position at the operating table is defined by the clinical demands of the procedure so is not always in an ideal position in front of the gesture-sensing equipment in terms of distance and orientation. System developers may have to account for and accommodate such variations in the design of gestures and tracking capabilities. The examples here are intended to illustrate the broader issues, though developers may want to consider other clinically dependent and theatre-dependent configurations (such as a surgeon sitting in front of a PACS, system, as in Figure 1).
Conclusion
The goal is not simply to demonstrate the feasibility of touchless control in clinical settings; important design challenges range from the gesture vocabulary to the appropriate combination of input modalities and specific sensing mechanisms. We have shown how they can play out in the development of the systems but must be addressed further, especially as used in real-world clinical settings. This is not a straightforward matter of requesting clinicians specify what they want by way of a gesture vocabulary.
While clinician participation in the design process is essential it is not just a matter of offloading gesture design to clinicians. Rather, it is about system developers understanding how the work of clinical teams is organized with respect to the demands of the procedure and the particular properties of the physical setting (such as a clinical team’s positioning and movement around the patient, colleagues, and artifacts).
Developers must also view these systems not simply as sterile ways to perform the same imaging as they would without them but must understand what clinicians are trying to achieve through their imaging practices and how they are shaped by features of the procedure with respect to sterility. Combining this principle with an understanding of the technical properties of touchless systems, system developers can then drive design with a view to how they enable image interpretation, communication, and coordination among clinical team members.
Related is the need to evaluate the system as it will be used in the real world. The concern here is less basic usability than how it could change the practice of the surgical team, what it needs to do to accommodate the team, and the factors that constrain the way the system is used. One important consideration here is fatigue, or “gorilla arm,” due to prolonged use in theatre that could affect system use, as well as other physical features of surgical practice.
While our focus here is overcoming the constraints of sterility in the operating theatre, a much broader issue involves infection control in hospital settings involving multiple devices, systems, and applications—from large displays to mobile units like tablet computers—for which touchless interaction mechanisms could play a role not just for medical professionals but for patients as well. Interesting examples include the GestureNurse system6 in which a robotic surgical assistant is controlled through gesture-based commands.
Consider, too, 3D imaging in the operating theatre. Interpreting the enormous number of images produced by scanning technologies is cumbersome through traditional slice-by-slice visualization-and-review techniques. With the volumetric acquisition of scans, the data is increasingly visualized as 3D reconstructions of the relevant anatomy that are better exploited through full 3D interaction techniques. Although a number of systems allow manipulation of 3D anatomical models they tend to do so through the standard two degrees of freedom available with traditional mouse input. The tracking of hands and gestures in 3D space opens up a much richer set of possibilities for how surgeons manipulate and interact with images through the full six degrees of freedom.
Moreover, with the addition of stereoscopic visualization of 3D renderings, system developers can further address how to enable clinicians to perform new kinds of interactions (such as reaching inside an anatomical model). They might also consider how touchless gestural interaction mechanisms provide new possibilities for interacting with objects and anatomical structures at a distance or otherwise out of reach (such as on a wall-size display and a display unreachable from the operating table). Opportunities do not involve just interaction with traditional theatres and displays but radical new ways to conceive the entire design and layout of operating theatres of the future.
Figures
 Figure 1. Surgical gown used to avoid touching non-sterile mouse with sterile gloved hand.
Figure 1. Surgical gown used to avoid touching non-sterile mouse with sterile gloved hand.
 Figure 2. Gesture system for manipulating 3D overlay in vascular surgery.
Figure 2. Gesture system for manipulating 3D overlay in vascular surgery.
 Figure 3. Gesture system for vascular surgery in theatre.
Figure 3. Gesture system for vascular surgery in theatre.
 Figure 4. Interacting with medical images: (a) away from the operating table; and (b) at the operating table.
Figure 4. Interacting with medical images: (a) away from the operating table; and (b) at the operating table.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Join the Discussion (0)
Become a Member or Sign In to Post a Comment