
In the past, the range of tasks that a computer could carry out was limited by what could be hard-coded by a programmer. Now, recent advances in machine learning (ML) make it possible to learn patterns from data such that we can efficiently automate tasks where the decision process is too complex to manually specify. After sensational successes in computer vision and natural language processing (NLP), the impact of artificial intelligence (AI) systems powered by ML is rapidly widening towards other domains.
Key Insights
The field of AI fairness aims to measure and mitigate algorithmic discrimination, but the technical formalism this requires has come under increasing criticism in recent years.
In the prototypical, technical approach to AI fairness, eight inherent limitations can be identified that inhibit its potential to truly address discrimination in practice. These range from concerns over the assessment of performance, the need for sensitive data, to the limited power of technical formalization in high-impact decision processes.
The limitations delineate the role technical tools for fairness should play and serve as a disclaimer for their current paradigm.
Today, AI is already being used to make high-stakes decisions in areas such as predictive policing,31 employment,20 and credit scoring.40 These are highly sensitive applications, in which decisions must be fair; that is, non-discriminatory with respect to an individual’s protected traits such as gender, ethnicity, or religion. Indeed, the principle of non-discrimination has a long history and intersects with many viewpoints: as a value in moral philosophy,5 as a human right,13 and as a legal protection.44 Evidently, algorithms that play a role in such decision processes should meet similar expectations, which is why AI fairness is prominently included as a value in the AI ethics guidelines of many public- and private-sector organizations.27 Yet AI systems that blindly apply ML are rarely fair in practice, to begin with because training data devoid of undesirable biases is hard to come by.26 At the same time, fairness is difficult to hard-code, because it demands nuance and complexity.
AI systems that blindly apply ML are rarely fair in practice, to begin with because training data devoid of undesirable biases is hard to come by.
Hence, fairness is both important and difficult to achieve, and as such it is high on the AI research agenda.36 The dominant approach to AI fairness in computer science is to formalize it as a mathematical constraint, before imposing it upon the decisions of an AI system while losing as little predictive accuracy as possible. For example, assume that we want to design an AI system to score people who apply to enroll at a university. To train this AI system, we may want to learn from data of past decisions made by human administrators in the admission process. Yet, if those decisions consistently undervalued women in the past, then any system trained on such data is likely to inherit this bias. In the prototypical fair classification setting, we could formalize fairness by requiring that men and women are, on average, admitted at equal proportions. A simple technical AI fairness approach to meet this constraint is to uniformly increase the scores given to women. The resulting decisions may then be considered fair, and little accuracy is likely to be lost.
Fairness is both important and difficult to achieve, and as such it is high on the AI research agenda.
Yet this approach rests on simplistic assumptions. For instance, it assumes that fairness can be mathematically formalized, that we collect gender labels on every applicant, that everyone fits in a binary gender group, and that we only care about a single axis of discrimination. The validity of such assumptions has recently been challenged, raising concerns over technical interventions in AI systems as a panacea for ensuring fairness in their application.10,34,38
Despite this criticism, the idea of tackling fairness through mathematical formalism remains popular. To an extent, this is understandable. Large-scale data collection on humans making high-impact decisions could enable us to study biases in the allocation of resources with a level of statistical power that was previously infeasible. If we could properly mitigate biases in AI systems, then we may even want fair AI to replace these human decision makers, such that the overall fairness of the decision process is improved. At the very least, technical solutions in fair AI seem to promise pragmatic benefits that are worth considering.
Therefore, the aim of this article is to estimate how far (technical) AI fairness approaches can go in truly measuring and achieving fairness by outlining what inherently limits it from doing so in realistic applications. With this lens, we survey criticisms of AI fairness and distill eight such inherent limitations. These limitations result from shortcomings in the assumptions on which AI fairness approaches are built. Hence, they are considered fundamental, practical obstacles, and we will not frame them as research challenges that can be solved within the strict scope of AI research. Rather, our aim is to provide the reader with a disclaimer for the ability of fair AI approaches to address fairness concerns. By carefully delineating the role that it can play, technical solutions for AI fairness can continue to bring value, though in a nuanced context. At the same time, this delineation provides research opportunities for non-AI solutions peripheral to AI systems, and mechanisms to help fair AI fulfill its promises in realistic settings.
Limitations of AI Fairness
Figure 1 provides an overview of the prototypical AI fairness solution.36 In this setting, an AI method learns from data, which may be biased, to make predictions about individuals. Task-specific fairness properties are computed by categorizing individuals into protected groups, such as men and women, and then comparing aggregated statistics over the predictions for each group. Without adjustment, these predictions are assumed to be biased, because the algorithm may inherit bias from the data and because the algorithm is probably imperfect and may then make worse mistakes for some of the groups. Fairness adjustment is done using preprocessing methods that attempt to remove bias from the data, inprocessing methods where modifications are made to the learning algorithm such that discriminatory patterns are avoided, and postprocessing methods that tweak the predictions of a potentially biased learning algorithm.
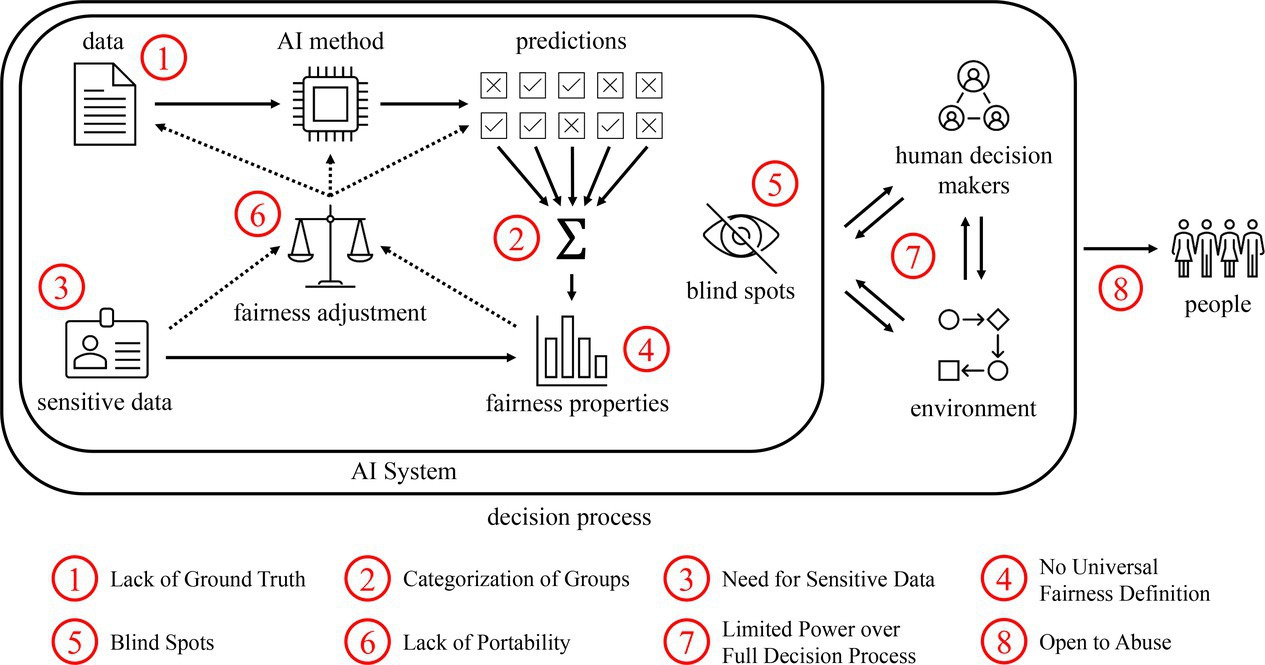
We consider eight inherent limitations of this prototypical fair AI system, which each affect its various components and levels of abstraction as illustrated in Figure 1. To start, we observe that bias in the data results in biased approximations of the ground truth, leading to unfair conclusions about the performance and fairness properties of the AI system. Fairness measurements are also problematic because they involve distinguishing people into groups and require sensitive data of individuals to do so. In fact, there is generally no universal definition of fairness in exact terms. Avoiding any discrimination is anyhow unrealistic, as it demands that the possible sources of bias are well-understood without any blind spots. Even if fairness can be adequately elaborated for one setting, the same solutions will often not be portable to another. More generally, AI systems are only a component of a larger decision process, for example, where biases can arise in the interaction with human decision makers and the environment, that is no longer within the scope of the AI. In this larger scope, we conclude that AI fairness can be abused, through negligence or malice, to worsen injustice.
Lack of ground truth. As is now widely understood by the AI fairness community, datasets that involve humans are often plagued by a range of biases that may lead to discrimination in algorithmic decisions.36 Importantly, this bias may prevent an unbiased estimation of the ground truth, that is, the prediction that should have been made for an individual. It is then difficult to make unbiased statements about the performance of an algorithm.10 For example, in predictive policing, when trying to predict whether someone will commit a crime, the dataset may use ‘arrested’ as the output label that must be predicted. Yet when one group is policed more frequently, their arrest rates may not be comparable to an advantaged group, meaning it cannot be assumed to be an unbiased estimate of the ground truth ‘committed a crime’.14 This raises concerns whether predictive policing can ever be ethical after long histories of biased practices.
The lack of a ground truth is a significant problem for fair AI, as it often depends on the availability of the ground truth to make statements about fairness.
In general, the lack of a ground truth is a significant problem for fair AI, as it often depends on the availability of the ground truth to make statements about fairness. For instance, a large disparity between false positive rates formed the basis of criticism against the COMPAS algorithm, which was found to incorrectly predict high recidivism risk for black defendants more often than for white defendants.31 However, lacking a ground truth to compute those rates in an unbiased way, one cannot even measure algorithmic fairness in this setting.21 Caution is thus warranted in the interpretation of any metrics where ground truth should be used to compute them. This holds for overall performance metrics such as accuracy, but also for many fairness statistics.
Categorization of groups. Bias has been considered in algorithms since at least 1996. Yet, it was the observations that biases are found throughout real datasets and then reproduced by data-driven AI systems that led to the rapid development of AI fairness research.4 AI systems are typically evaluated and optimized with a formal, mathematical objective in mind, and so this field demands formalizations of fairness that somehow quantify discriminatory biases in exact terms.
Assuming the AI system is meant to classify or score individuals, a strong formalization of fairness is the notion of individual fairness, which asserts that “any two individuals who are similar with respect to a particular task should be classified similarly.”15 Though principled, such definitions require an unbiased test to assess whether two individuals are indeed similar. However, if such a test were readily available, then we could directly use that test to construct an unbiased classifier. Developing a test for strong definitions of individual fairness is thus equally as hard as solving the initial problem of learning a fair classifier.
The vast majority of AI literature is instead concerned with the more easily attainable notion of group fairness, which requires that any two protected groups should, on average, receive similar labels.36 Group fairness expresses the principles of individual fairness6 by looking at the sum of discrimination toward an entire group rather than individual contributions. Though this increased statistical power makes group fairness much more practical to measure and satisfy, it comes with its own problems, which we discuss next.
Simpson’s paradox. An obvious problem with group fairness is that, through aggregation, some information will be lost. To illustrate, we discuss the example of the University of California, Berkeley admission statistics from the fall of 1973.19 These statistics showed that the overall acceptance rate for men was higher (44%) than for women (35%), suggesting there was a pattern of discrimination against the latter. However, when we consider the acceptance rates separately per departmenta in Figure 2, there does not seem to be such a pattern. In fact, except for departments C and D, the acceptance rate is reportedly higher for women. From this perspective, it could be argued that women are mostly favored. The fact that conclusions may vary depending on the granularity of the groups is referred to as Simpson’s Paradox.
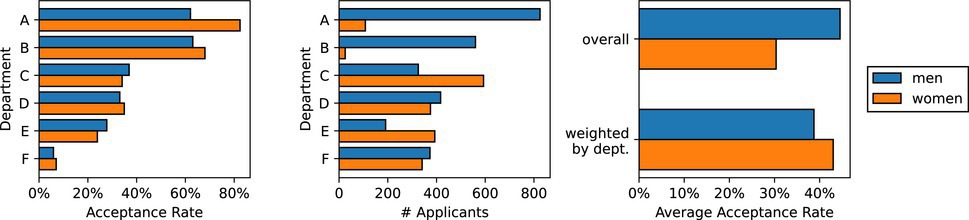
The paradox arises from the difference in popularity between the departments. Women more commonly applied to departments with low acceptance rates (for example, departments C through F), which hurt their overall average acceptance rate. Yet, when taking the weighted average by accounting for the total number of applicants of both men and women, we see that women score higher. As noted by Wachter et al.,44 the point of this example is not that some forms of aggregation are better than others. Rather, we should be wary that aggregation, such as the kind that is found in group fairness, may influence the conclusions we draw.
Fairness gerrymandering. An especially worrisome property of group fairness is that, by looking at averages over groups, it allows for some members of a disadvantaged group to receive poor scores (for example, due to algorithmic discrimination), so long as other members of the same group receive high-enough scores to compensate. Such situations are considered fairness gerrymandering28 if specific subgroups can be distinguished as systematically disadvantaged within their group.
Group-fairness measures may thus be hiding some forms of algorithmic discrimination.The toy example in Figure 3 illustrates this. It is constructed such that men and women receive positive decisions at equal average rates (here 50%), just like when we view the groups of lighter-skinned and darker-skinned people separately. A system giving such scores might therefore be seen as fair, because group fairness measures no discrepancy based on gender or skin tone. However, this per-axis measurement hides the discrimination that may be experienced at the intersection of both axes. In the case of Figure 3, lighter-skinned men and darker-skinned women proportionally receive fewer positive predictions than the other intersectional groups. Because darker-skinned women are also in the minority, they receive even fewer positive predictions proportionally. Consider, then, that in the real world, we often do see significant discrimination along separate axes. The discrimination experienced by those at the intersection may then be far worse. Indeed, empirical evidence shows, for example, that darker-skinned women often face the worst error rates in classification tasks.8
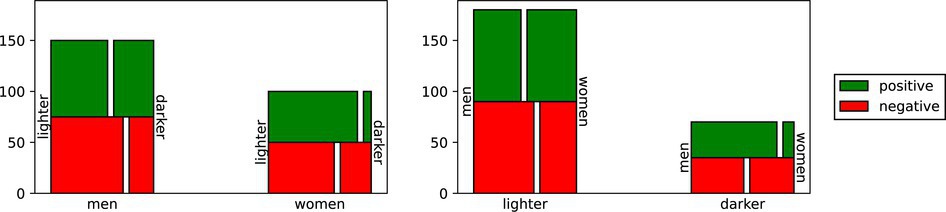
The field of intersectional fairness addresses the (magnified) discrimination experienced by those at the intersection of protected groups.8 A straightforward approach is to directly require fairness for all combinations of subgroups. While this addresses some of the concerns for the example in Figure 3, it is not a realistic solution. Such definitions of intersectional fairness give rise to a number of subgroups that grows exponentially with the number of axes of discrimination,28 thereby losing the statistical power we were hoping to gain with group fairness.
Discretization concerns. Socio-technical views of intersectional fairness also criticize the assumption that people can neatly be assigned to groups at all. This assumption helps in mapping legal definitions of discrimination to a technical context, yet it thereby also inherits the issues that result from rigid identity categories in law.25 In fact, most protected characteristics resist discretization. Gender and sexual orientation are unmeasurable and private,37 disability is highly heterogeneous,9 and ethnicity labels are subjective and may be reported differently depending on the time and place.34
While the fear of gerrymandering in group fairness encourages highly granular (intersections of) identity groups, an ‘overfitting’ of identity categorization should also be avoided. It must be better understood how machine learning, which aims at generalization, can model such individual nuances.
Need for sensitive data. Fair AI research is fueled by the use of sensitive data; that is, data on people’s traits that are protected from discrimination. Almost all methods require such data to measure and mitigate bias.36Indeed, exact fairness definitions involve categorizing people into groups, which requires us to know, for every person, which group they actually identify with (if any).
Yet it is hardly a viable assumption that sensitive data is generally available for bias mitigation purposes in the real world. Clearly, the collection of such highly personal data conflicts with the ethical principle of privacy,42 despite the fact that privacy and fairness are often considered joint objectives in ethical AI guidelines.27 Fairness should not blindly be given priority here, since disadvantaged groups may prefer to avoid disclosing their sensitive data due to distrust caused by structural discrimination in the past.2 For example, outing the sexual orientation or gender identity of queer individuals can lead to emotional distress and serious physical or social harms.41
Indeed, practitioners report that individuals are often hesitant to share sensitive data, most frequently because they do not trust that it will be in their benefit.3 Privacy and availability concerns are thus consistently cited as significant obstacles to implementing fair AI in practice.26,32,37 Sensitive data has received special protection in the past, such as in European data protection law.b In stark contrast, the European Commission’s recently proposed AI Actc now includes a provision that specifically allows for the processing of sensitive data for the purpose of ensuring “the bias monitoring, detection and correction in relation to high-risk AI systems.”
No universal fairness definition. So far, we have discussed mathematical definitions of fairness in simple terms; that is, as constraints that compare simple statistics of different demographic groups. These constraints are motivated through the idea that the AI system is distributing resources, which ought to be done in a fair way. However, does this mean that each group should receive an equal amount of resources, or should we try to be equitable by taking the particular need, status, and contribution of these groups into account?45 This irresolution has led to a notoriously large variety of fairness notions. For just the binary classification setting, one survey from 201843 lists 20 different definitions, each with its own nuance and motivations. For example, statistical parity 15 requires equality in the rate at which positive predictions are made. On the other hand, equalized odds requires false positive and false negative rates to be equal. It therefore allows for different rates at which groups receive positive decisions, so long as the amount of mistakes is proportionally the same. Both notions are defensible depending on the context, but they are also generally incompatible: If the base rates differ across groups (that is, one group has a positive label in the data more often than another), then statistical parity and equalized odds can only be met simultaneously in trivial cases.29
In fact, many notions have shown to be mathematically incompatible in realistic scenarios.21 This has led to controversy, for example, in the case of the COMPAS algorithm. As mentioned previously, it displayed a far higher false-positive rate in predicting recidivism risk for black defendants than white defendants.31 Yet the COMPAS algorithm was later defended by noting that it was equally calibrated for both groups; that is, black and white defendants that were given the same recidivism risk estimate indeed turned out to have similar recidivism rates.17 Later studies proved that such a balance in calibration is generally incompatible with a balance in false-positive and negative rates, except in trivial cases.29From a technical point of view, these results imply that there cannot be a single definition of fairness that will work in all cases. Consequently, technical tools for AI fairness should be flexible in how fairness is formalized, which greatly adds to their required complexity.
Moreover, it may not even be possible to find a ‘most relevant’ fairness definition for a specific task. Indeed, human-subject studies show that humans generally do not reach a consensus on their views of algorithmic fairness. From studies collected in a surveyed by Starke et al.,39 it appears that people’s perceptions of fairness are heavily influenced by whether they personally receive a favorable outcome. The ‘most relevant’ fairness definition may therefore be the product of a constantly shifting compromise7 resulting from a discussion with stakeholders. It is also noted that these discussions may be hampered by a lack of understanding of technical definitions of fairness.
Blind spots. It will now be clear that fairness is inherently difficult to formalize and implement in AI methods. We thus stress the need for nuance and iteration in addressing biases. However, such a process assumes that possible biases are already anticipated or discovered. Businesses have raised concerns that, though they have processes and technical solutions to tackle bias, they can only apply them to biases that have already been foreseen or anticipated.32 Without an automated process to find them, they are limited to following hunches of where bias might pop up. Holstein et al.26 cite one tech worker, saying “You’ll know if there’s fairness issues if someone raises hell online.” Though well-designed checklists may help to improve the anticipation of biases,35 it is safe to assume that some blind spots will always remain. Since unknown biases are inherently impossible to measure, we cannot always make definitive guarantees about fairness in their presence. The fairness of AI systems should thus constantly be open to analysis and criticism, such that new biases can quickly be discovered and addressed.
In fact, some biases may only arise after deployment. For example, the data on which an algorithm is trained may have different properties than the data on which it is evaluated, because the distribution of the latter may be continuously changing over time.30 Similarly, any fairness measurements taken during training may not be valid after deployment.12 The AI Act proposed by the European Commission would therefore rightly require that high-risk AI systems are subjected to post-market monitoring, in part to observe newly arising biases. The fairness properties of an AI system should thus continuously be kept up to date.
Lack of portability. As we have argued, fairness should be pursued for a particular AI system after carefully elaborating the assumptions made and after finding compromise between different stakeholders and viewpoints (for example, because fairness is difficult to formalize). However, this means that our desiderata for a fair AI system become highly situation-specific. As pointed out by Selbst et al.,38 this limits the portability of fairness solutions across settings, even though portability is a property that is usually prized in computer science. Consequently, the flexibility of fair AI methods that we called for earlier in this article may not be achievable by simply choosing from a zoo of portable fairness solutions.
Fairness should be pursued for a particular AI system after carefully elaborating the assumptions made and after finding compromise between different stakeholders and viewpoints.
In industry, there is already empirical evidence that ‘off-the-shelf’ fairness methods have serious limits. For example, fairness toolkits such as AIF360,d Aequitas,e and Fairlearnf offer a suite of bias measurement, visualization, and mitigation algorithms. However, though such toolkits can be a great resource to learn about AI fairness, practitioners found it hard to actually adapt them to their own model pipeline or use case.33
Limited power over full decision process. Fair AI papers often start by pointing out that algorithms are increasingly replacing human decision makers. Yet, decisions in high-risk settings, such as credit scoring, predictive policing, or recruitment, are expected to meet ethical requirements. Such decision processes should thus only be replaced by algorithms that meet or exceed similar ethical requirements, such as fairness. However, it is unrealistic to assume that decision processes will be fully automated in precisely those high-risk settings that motivate fair AI in the first place. This is because fully automated AI systems are not trusted to be sufficiently accurate and fair.7 The EU’s General Data Protection Regulationg even specifically grants the right to, in certain circumstances, not be subject to fully automated decision making.
In most high-risk settings, algorithms only play a supportive role and the final decision is subject to human oversight.22 However, unfairness may still arise from the interaction between the algorithm and the larger decision process (for example, including human decision makers) that is outside its scope.38 For example, a study conducted by Green and Chen23 asked participants to give a final ruling on defendants in a pre-trial setting. After being presented with an algorithmic risk assessment, participants tended to (on average) assign a higher risk to black defendants than the algorithm. The reverse was true for white defendants.
Hence, in an unjust world, it is meaningless to talk about the fairness of an algorithm’s decisions without considering the wider socio-technological context in which an algorithm is applied.16 Instead, it is more informative to measure the overall fairness properties of a decision process, of which an algorithm may only be a small component among human decision makers and other environmental factors.11
In an unjust world, it is meaningless to talk about the fairness of an algorithm’s decisions without considering the wider socio-technological context in which an algorithm is applied.
Open to abuse. Like most technology, solutions for algorithmic fairness are usually evaluated with the understanding that they will be used in good faith. Yet the sheer complexity of fairness may be used as a cover to avoid fully committing to it in practice. Indeed, opportunistic companies implementing ethics into their AI systems may resort to ethics-shopping; that is, they may prefer and even promote interpretations of fairness that align well with existing (business) goals.18 Though they may follow organizational ‘best practices’ by establishing ethics boards and collecting feedback from a wide range of stakeholders, an actual commitment to moral principles may mean doing more than what philosophers are allowed to do within corporate settings.5 Fundamentally, solutions toward ethical AI have a limited effect if a deviation from ethics has no consequences.24
The sheer complexity of fairness may be used as a cover to avoid fully committing to it in practice.
The complexity of fairness may not only lead to obscure commitments toward it; its many degrees of freedom may also be abused to create or intensify injustice. In this article, we argued that ground truth labels are often unavailable, lending power to whomever chooses the proxy that is used instead. Moreover, as we also discussed, the groups in which people are categorized grants the power to conceal discrimination against marginalized subgroups. Following another thread in this article on the need for sensitive data to measure fairness, we also warn that this necessity could motivate further surveillance, in particular on those already disadvantaged.10 Overall, significant influence is also afforded in deciding how fairness is actually measured, as a universal definition may not exist.
Conclusion
It is evident from our survey of criticism toward fair AI systems that such methods can only make guarantees about fairness based on strong assumptions that are unrealistic in practice. Hence, AI fairness suffers from inherent limitations that prevent the field from accomplishing its goal on its own. Some technical limitations are inherited from modern machine learning paradigms that expect reliable estimates of the ground truth and clearly defined objectives to optimize. Other limitations result from the necessity to measure fairness in exact quantities, which requires access to sensitive data and a lossy aggregation of discrimination effects. The complexity of fairness means that some forms of bias will always be missed and that every elaboration of fairness is highly task-specific. Moreover, even a perfectly designed AI system often has limited power to provide fairness guarantees for the full decision process, as some forms of bias will remain outside its scope. Finally, the extensive automation of high-stakes decision processes with allegedly fair AI systems entails important risks, as the complexity of fairness opens the door to abuse by whomever designs them.
These inherent limitations motivate why AI fairness should not be considered a panacea. Yet we stress that also the many benefits of AI fairness must not be overlooked, since it can remain a valuable tool as part of broader solutions. In fact, many of the limitations we identify and assumptions we question are not only inherent to fair AI, but to the ethical value of fairness in general. The study of AI fairness thus forces and enables us to think more rigorously about what fairness really means to us, lending us a better grip on this elusive concept. In short, fair AI may have the potential to make society more fair than ever, but it needs critical thought and outside help to make it happen.
Acknowledgments
This research was funded by the ERC under the EU’s 7th Framework and H2020 Programmes (ERC Grant Agreement no. 615517 and 963924), the Flemish Government (AI Research Program), the BOF of Ghent University (BOF20/DOC/144 and BOF20/IBF/117), and the FWO (G0F9816N, 3G042220).



Join the Discussion (0)
Become a Member or Sign In to Post a Comment