
Databases are often assumed to have definite content. The reality, though, is that the database at hand may be deficient due to missing, invalid, or uncertain information. As a simple illustration, the primary address of a person may be missing, or it may conflict with another primary address, or it may be improbable given the presence of nearby businesses. A common practice to address this challenge is to rectify the database by fixing the gaps, as done in data imputation, entity resolution, and data cleaning. The process of rectifying the database, however, may involve arbitrary choices due to computational limitations, such as errors in statistical or machine-learning models, or mere lack of information that even humans cannot cope with in full confidence. In turn, answers to queries over the deficient database may depend on the choices made to rectify it; thus, the answers to queries may vary from one choice to choice, even though both choices may be equally legitimate.
In the pursuit of principled solutions, there has been a continuous research effort to develop fundamental approaches for handling database deficiency with no (or with less) arbitrariness. The purpose of this review article is to highlight some of the ways in which the possible world semantics has been deployed as a principled approach to overcome database deficiency in different contexts. In this approach, we acknowledge that we need to rectify the deficiency: fill in missing information, delete wrong records (hereafter tuples or facts), correct erroneous values, and so on. Yet, since many rectifications may exist and since we do not know which is the correct one, we do not commit to a specific one. Instead, we view our deficient database as a representation of the results of all conceivable rectifications, each such rectification giving rise to a legitimate candidate of a valid database that we call a possible world.
Since the possible worlds differ from each other, a query may produce different collections of answers (which are also tuples) when applied to different possible worlds. Therefore, query answering requires the use of an aggregation method to combine the query results over the possible worlds. The intersection of all possible results is the prototypical example of such an aggregation method. In this context, the tuples in the intersection are called the “certain answers” because they are obtained in every possible world, regardless of what rectification has led to it. Intersection is the most studied aggregation method because of its intuitive meaning: it extracts the answers for which validity is not affected by the database anomaly. For example, if we have uncertainty regarding the apartment number of a person , we can still be certain about living in Paris in the same apartment as . Intersection is the main, but not the only, aggregation method discussed in this survey. The union is a different type of aggregation, where we are interested in the “possible answers,” that is, the answers that are obtained in at least one possible world. Probabilistic variants of the possible world semantics have also been studied in depth; here, each rectification has a probability (that can be determined from the database content), and then the aggregation is done by marginal inference: to each tuple, we associate the probability that it is an answer when the query is applied to a random possible world.
Key Insights
Possible world semantics give meaning to queries over incomplete, inconsistent, or uncertain databases. Such databases are viewed as compact representations of all their possible rectifications; the “certain answers” are the query answers that hold true in every possible rectification.
Queries that are computationally tractable under standard database semantics may become intractable under possible world semantics. In many cases, the tools of computational complexity can be applied to delineate the boundary between tractability and intractability.
Election databases form a new setting for the framework of possible worlds. This setting brings social choice theory and relational databases together and supports reasoning about elections with partial voter preferences and with contextual information about the candidates.
It is often the case that the original (deficient) database constitutes a compact representation of the set of possible worlds, and that this set is infeasible to materialize or store; for example, the number of possible worlds can be exponential in the size of the representation or even infinite. Consequently, finding the certain answers to queries poses a significant computational challenge because an efficient aggregation of the answers over all possible worlds has to be performed without actually accessing each possible world, but by directly processing the compact deficient database. Such processing might be attainable for some queries but unattainable for others, and in such cases we would like to distinguish between queries with tractable and intractable certain answers. The distinction is often achieved via dichotomy theorems that classify the complexity of the certain answers of every query in some large family of queries.
We will illustrate the possible-world semantics in four different settings. While not exhaustive, these four settings represent substantially different mechanisms for forming possible worlds. In the setting of data exchange, logical inference rules are used to form the possible worlds: we have a database under one schema that has to be transformed into a database under a different schema, and the possible worlds are the candidate solutions according to rule-based constraints specifying the relationship between the two schemas. In the setting of inconsistent databases, minimal intervention is used to form the possible worlds: we have a database that violates integrity constraints, and the possible worlds are the different ways to repair the inconsistent database. In the setting of probabilistic databases, we have a representation of a probability distribution over the collection of all databases. Here we focus on the most studied model, the tuple-independent databases: each record has a confidence value that is interpreted as a probability, and different records are probabilistically independent. Finally, in the setting of election databases, completions of partial orders are used to form possible worlds: we have ordinary databases that describe information about voters, candidates, and winners in elections, but only partial knowledge about voter preferences is known, thus there is uncertainty about who the winning candidates are. Note that the framework of election databases augments computational social choice with relational database context. In particular, it generalizes the necessary winners and the possible winners problems studied by researchers in computational social choice, because we can now ask for the certainty or possibility of properties of the winners (for example, their partisan affiliation or position on some issue) and not just their mere identity (for example, whether candidate or candidate is a winner).
In each setting considered here, we use the lens of computational complexity to highlight the algorithmic aspects of aggregating the answers to conjunctive queries, an extensively studied class of queries that form the core of most relational database queries.
An online appendix (available at https://dl.acm.org/doi/10.1145/3624717) contains additional discussion about topics not covered in this article and an expanded list of references.
Basic Notions
Relational databases and queries.
We start with some terminology from relational databases. A schema is a collection of relation symbols , each with an associated arity (number of columns). A database over the schema , also called an instance of (or just an instance if is clear from the context), associates with each relation symbol a finite relation with the same arity as . We identify an instance with its finite set of facts , where each such fact asserts that the tuple belongs to the relation of associated symbol . In this case, we say that is an -fact of . We write to denote that for every relation symbol , every -fact of is also an -fact of . We also view a database as a finite relational structure in the sense of mathematical logic (for example, see Abiteboul et al.1).
A -ary query over a schema maps every instance of into a -relation . Every tuple of is referred to as an answer. As a special case, a query of arity zero is viewed as a Boolean query that is either true (has the empty tuple as an answer) or false (has no answers) on the given instance . In logical terms, a Boolean query is simply a Boolean statement (true or false) about the database. When analyzing a query, we typically ignore the database schema and, without loss of generality, assume that it consists of the relation symbols that are mentioned in the query formulation.
We will focus on the class of conjunctive queries, also known as select-project-join queries. They are at the core of the most frequently asked queries on relational databases, and are directly supported by SQL. For example, consider the schema with the binary relations and , and consider also the following query that finds the neighboring countries of France:
SELECT B.id2
FROM Country C, Borders B
WHERE C.id = B.id1 and C.name = "France"
This query is expressed as a conjunctive query using the formula
(1)More generally, a conjunctive query is a logical formula of the form
where is a sequence of free variables, disjoint from (the sequence of existentially quantified variables), and each is an relational atom, that is, an expression of the form where is a -ary relation symbol and each is either a constant or a variable from or . We refer to each as an atom of the query. Semantically, an answer is a tuple that makes the formula true when assigned to . We also assume that every variable in occurs in at least one atom – this is a standard safety assumption. A Boolean conjunctive query has no free variables, hence it has the form . A conjunctive query has a self-join if two different atoms use the same relation symbol . For example, the query of Equation (1) has no self-joins, but it would if we added the atom for retrieving the id’s and the names of the returned countries. Some of the results will require the assumption that the considered queries have no self-joins.
Possible worlds and certain answers.
The standard query evaluation problem involves a query and an instance , and the problem is to compute the answer of on . We explore settings where query evaluation involves a query and a collection of databases, instead of a single database. These databases can be thought of as possible worlds on which a query can be evaluated. What is the semantics of a query posed on different worlds? Clearly, we need a notion that provides a method for aggregating the answers obtained on each possible world. The certain answers is the most extensively studied such notion, where intersection is used as the aggregation method.
Definition 2.1.
Let be a -ary query and let be a collection of databases. The certain answers of on is the set
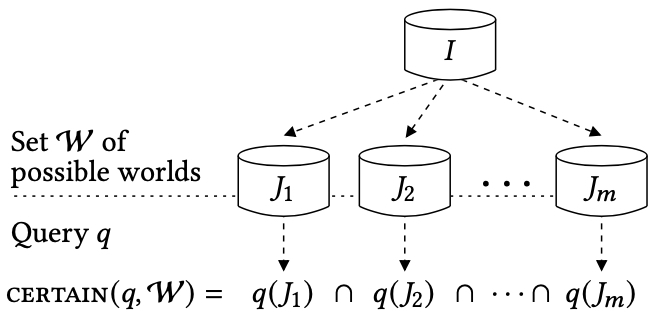
We will discuss the cost of computing the certain answers. On the face of their definition, computing the certain answers requires evaluating the query on each possible world. This may be a formidable task because the number of possible worlds can be very large or even infinite. In several different settings, however, the collection of the possible worlds admits a compact representation . This suggests a different approach: compute the certain answers of a query on by working with the compact representation , instead of examining each possible world in .
We assume familiarity with basic notions in complexity theory, such as the complexity classes P, NP, coNP, and #P, and the meaning of hardness and completeness for complexity classes.18 We follow the convention of analyzing database problems in terms of their data complexity, which means that the input consists of the instance while everything else, such as the schema and the query, are fixed.35 In particular, when we analyze computational problems associated with queries, each query gives rise to a separate computational problem, and this problem might be tractable for one query and intractable for another query.
Nulls and Data Exchange
In many settings, the possible worlds under consideration involve the use of null values that, intuitively, are placeholders for missing values. Database systems supported null values from the very beginning. Moreover, the pioneering work of Imielinski and Lipski20 gave semantics to null values by means of possible worlds. Their framework introduced the concept of marked nulls, later called labeled nulls, that behave like variables: two occurrences of the same labeled null represent the same missing value, while distinct labeled nulls represent missing values that may be different or equal.
We will use the symbols to denote labeled nulls. An incomplete database is a collection of relations such that each tuple in each relation of consists of constants and labeled nulls, that is, each is a constant or a labeled null. Let be the collection of all databases obtained from by replacing each labeled null by some constant. Therefore, the incomplete database is a compact representation of the possible worlds in . In this scenario, it is not hard to prove that the certain answers of a conjunctive query on can be computed by evaluating the query directly on the compact representation , where each labeled null in is treated as a distinct actual value (constant). More precisely, , where is the set of of all null-free tuples of . For more details, Abiteboul et al.1
In the SQL standard, nulls are not labeled, that is, there is a single null each occurrence of which should be viewed as a distinct labeled null. It should be noted that SQL queries do not adopt the certain-answer semantics, but rather the semantics of three-valued logic, where every comparison to a null value results in “unknown” rather than “true” or “false”. There has been a large body of work, such as Libkin’s,28 in which the SQL semantics are compared and contrasted with the certain-answer semantics.
The preceding uses of nulls have been extensively studied, and we will not focus on these here. Instead, we will focus on the use of labeled nulls in data exchange, which is the problem of transforming data structured under a source schema into data structured under a different target schema . To be able to generate meaningful solutions to the data exchange problem, we may need to invent new values that are not in the source database; this is achieved by using labeled nulls that mark entries as invented values, instead of actual known values. Still, there might be many different solutions, and we view each solution as a possible world. In particular and unlike the possible worlds in the framework of Imielinski and Lipski, each possible world may include labeled nulls (that are treated as ordinary values by database queries).
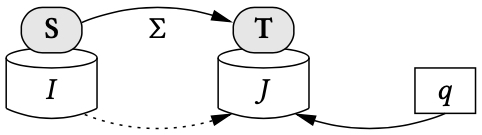
Data exchange is formalized using schema mappings, that is, triples of the form , where is a set of constraints that specify the data transformation from to .14 If is a source instance, then a solution for with respect to is a target instance such that the pair satisfies the constraints in . The active domain of consists entirely of constants, while the active domain of may contain both constants and labelled nulls. If the schema mapping is understood from the context, we simply talk about a solution for , instead of a solution for with respect to .
If is a schema mapping and is a source instance, we write to denote the set of all solutions for . In general, the constraints in may over-specify or under-specify the data transformation task, hence may be the empty set or a non-empty finite set or an infinite set. If is a query over the target schema , we can consider the certain answers of on , that is, the set
The pair is a compact representation of the space of all solutions for . Thus, the question arises: can this compact representation be used to compute the certain answers of target queries, and if so, how? As shown in,14 there are many natural settings in which the pair is used to compute a universal solution for , a special type of solution for with the property that the certain answers of every conjunctive query can be obtained by directly evaluating the query on the universal solution.
By a definition, a universal solution for is a solution for such that for every solution for , there is a homomorphism from to that is the identity on the constants in . Intuitively, a universal solution for is a “most general” solution for because it has no more and no less information than what is encapsulated in the pair . Universal solutions can be used to obtain the certain answers of conjunctive target queries. More precisely, let be a schema mapping, a source instance, and a target conjunctive query. If is a universal solution for , then , where is the set of of all null-free tuples of . The proof follows from the definitions and the fact that conjunctive queries are preserved under homomorphisms.
When do universal solutions exist? To answer this question, we also need to address a different question: what are good schema-mapping specification languages, that is, languages for expressing the constraints used in schema mappings? Ideally, a good schema-mapping specification language should strike a balance between high expressive power and tame computational behavior. From top down, if arbitrary first-order formulas are allowed to specify schema mappings, then it is easy to show that there are simple conjunctive queries for which computing the certain answers is an undecidable problem. From bottom up, let us consider some basic data transformation tasks that every schema-mapping specification language ought to support. In each case, we first describe the transformation and then give a first-order formula expressing an example of it.
Project out a column from a source relation and copy the result to a target relation; in symbols, .
Decompose a source relation into two target relations; in symbols, .
Add a column to a source relation and copy the result to a target relation; in symbols, .
Join two source relations and copy the result to a target relation; in symbols, .
The formulas expressing the preceding data transformations are first-order formulas of the form , where is a conjunction of atoms with variables from and is a conjunction of atoms with variables from and . These formulas are known as tuple-generating dependencies (tgds) and constitute one of the broadest classes of integrity constraints in databases.15 In fact, the formulas that we used to express these data transformations belong to a special class of tgds called source-to-target tgds (s-t tgds), because the atoms in the antecedent of each tgd are over the source schema, while the atoms in the consequent are over the target schema.
In what follows, we will consider schema mappings where always contains s-t tgds. In addition, may include target tgds and target equality-generating dependencies (target egds). Target tgds are tgds of the form in which both and are conjunctions of atoms over the target schema; target egds are first-order formulas of the form , where is a conjunction of atoms over the target schema and are two distinct variables from . Target tgds and target egds are the most extensively studied class of integrity constraints over a database schema.15 As special cases, they contain the functional dependencies and the full tgds, which are tgds with no existential quantifiers in the consequent.
Let be a schema mapping and let be a Boolean target conjunctive query.
The existence-of-universal-solutions problem asks: given a source instance , is there a universal solution ?
The certain answers problem asks: given a source instance , is true?
The complexity of these two decision problems exhibits diverse behavior, which depends on the constraints allowed in the schema mappings. Figure 3 summarizes the precise results in three parts. Next, we discuss the main ideas behind the proofs of each part.

The undecidability results in the first part are obtained via a reduction from the embedding problem for finite semigroups: given a finite partial semigroup, can it be extended to a finite semigroup? (see Kolaitis et al.24 for the details).
The main tool for the tractability results in the second part is the chase procedure, a versatile algorithm originally designed to study the implication problem for database dependencies.2,7,29 Intuitively, when an instance is chased with a set of tgds and egds, we consider all instantiations of variables that satisfy the antecedents of the constraints and then generate new facts as needed to satisfy the consequents of the constraints. For example, if the instance consists of the fact and is chased with the tgd , then the chase procedure will generate a labelled null and the facts and . With egds, the chase will attempt to equate the values of the two variables in the consequent of the egd by replacing a labelled null by a constant or one labelled null by another, but it will fail if it has to equate two different constants.
In general, the chase procedure may not terminate. There are, however, broad sufficient conditions guaranteeing the termination of the chase. In particular, if the set of the target tgds in the schema mapping considered obeys certain structural conditions, such as weak acyclicity, then the chase procedure terminates within time bounded by a polynomial in the size of the input structure and produces a universal solution precisely when a solution exists.14 Every set of full tgds is weakly acyclic, while the set consisting of the target tgd is not. Actually, if the instance consisting of the fact is chased with this tgd, then the chase procedure will not terminate as it will generate an infinite sequence of facts.
As regards the rewritability results in the third part, if a schema mapping is specified using s-t tgds only, then, given a source instance , the chase procedure always terminates and produces a universal solution for in time bounded by a polynomial in the size of . Therefore, by the properties of universal solutions. can be used to compute the certain answers , where is a target conjunctive query, in time bounded by a polynomial in the size of . In this case, however, the certain answers can also be obtained by rewriting to a union of conjunctive queries over the source schema and then directly evaluating on . This is achieved by “decomposing” into a set of local-as-view (LAV) constraints and a set of global-as-view (GAV) constraints, where a LAV constraint is a tgd whose antecedent consists of a single atom and a GAV constraint is a tgd whose consequent consists of a single atom. The rewriting of into can then be achieved by combining the MiniCon algorithm for LAV constraints31 with an unfolding technique for GAV constraints.
For further reading about data exchange, see the monograph5 and the collection.24
Inconsistent Databases
In designing databases, one specifies a schema and a set of integrity constraints on . An inconsistent database is a database that does not satisfy . Inconsistent databases arise in a variety of contexts and for different reasons, including the following two. First, a database system may not support the enforcement of a particular type of integrity constraints. Second, data at different sources may be transferred to a central repository and the resulting database may be inconsistent, even though each source database is consistent.
The framework of database repairs, introduced by Arenas, Bertossi, and Chomicki,5 is a principled approach to coping with inconsistent databases and without “cleaning” dirty data first. Database repairs constitute a mechanism for representing possible worlds through interventions in the database. Specifically, given an inconsistent database, the aim is to achieve consistency through some minimal intervention in the database. There may exist, however, many different such minimal interventions, and it may not be known which one represents the ground truth. Hence, the result of each such minimal intervention is viewed as a possible world.
Let be a set of integrity constraints and let be an inconsistent database. Intuitively, a database is a repair of w.r.t. if is a consistent database (that is, ), and differs from in a “minimal” way. Several different types of repairs have been considered, including set-based repairs (subset, superset, -repairs), cardinality-based repairs, attribute-based repairs, and preferred repairs.
Definition 4.1.
Let be a set of integrity constraints and let be an inconsistent database. A database is a subset-repair of w.r.t. if is a maximal consistent sub-database of , that is, the following conditions hold: (a) ; (b) ; (c) there is no database such that and , where denotes proper containment.
In what follows, we will focus on subset repairs and so from now on we will use the term repair, instead of the term subset repair.
Example 4.2.
Let be the set consisting of the key constraint . The inconsistent database has four repairs:
; ;
;
A straightforward generalization of this example shows that an inconsistent database may have exponentially many repairs.
Definition 4.3.5
Let be a set of integrity constraints, let be a query, and let be a database.
The consistent answers of on w.r.t. is the set
The consistent answers are certain answers, where the possible worlds are the repairs. Indeed, if is a set of constraints and is a database, let be the set of all repairs of w.r.t. . Then .
Let us revisit the preceding Example 4.2, where we have:
If is the query , then
If is the query , then
Let be a set of integrity constraints and let be a Boolean query. is the following decision problem: Given a database , is true? (In other words, is true on every repair of ?) We will examine the complexity of in a basic setting, namely, when is a Boolean conjunctive query and is a set of key constraints with one key per relation.
We first observe that in this setting the repair-checking problem w.r.t. is in , where this problem asks: given two databases and , is a repair of w.r.t. ? From this observation and the relevant definitions, it follows that if is a set of key constraints with one key constraint per relation and is a Boolean conjunctive query, then is in .
Let be the following set of constraints asserting that the binary relations and have their first attribute as key:
Consider the following two Boolean queries:
is the path query .
is the sink query .
The question now arises: what can we say about the computational complexity of , ? Fuxman and Miller17 showed that is in , whereas is -complete.
We first explain why is in . In fact, a stronger result holds: is FO-rewritable, which means that there is a first-order definable query such that for every database , we have is true if and only if is true.
Concretely, it is easy to verify that is the query
From a complexity standpoint, FO-rewritability is the most desirable outcome: we can compute the consistent answers by directly evaluating a FO-query on the inconsistent database. Furthermore, FO-rewritability implies that is in .
Next, we show that is -complete via a polynomial-time reduction from the (complement of) Monotone SAT, which is the restriction of SAT to monotone formulas, that is, to Boolean formulas in conjunctive normal form such that each clause (conjunct) of the formulas is either a disjunction of variables (positive clause) or a disjunction of negated variables (negative clause).
Given a monotone formula , construct a database with relations and : if is a positive clause and the variable occurs in , then put in ; if is a negative clause and occurs in , then put in . It is now easy to verify that is satisfiable if and only if is false (that is, there is a repair of such that is false). Thus, is -complete.
Next, consider the following Boolean query:
is the cycle query .
Wijsen36 showed that is in , but it is not FO-rewritable. Thus, FO-rewritability is not the only way in which the consistent answers of a query can be tractable.
In summary, we have seen that the following statements are true.
is in ; in fact, it is FO-rewritable.
is in , but it is not FO-rewritable.
is -complete.
The trifurcation in the complexity of , for , is not an isolated phenomenon, but an instance of a deeper result, depicted in Figure 4, about conjunctive queries without self-joins. In that result, the boundaries of the trichotomy are delineated with the help of a graph, called the attack graph, which is associated with and . This graph has two types of edges, regular edges and strong edges. If the attack graph is acyclic, then is FO-rewritable. If the attack graph is cyclic, but no cycle contains a strong edge, then is in but it is not FO-rewritable. Finally, if the attack graph has a cycle containing at least one strong edge, then is coNP-complete.

The Koutris-Wijsen Dichotomy Theorem vastly generalizes several different earlier dichotomy results, including the one in25 that classifies the queries that consist of two atoms over two distinct relations. The classification of the complexity of for arbitrary Boolean conjunctive queries (including those with self-joins) remains an open problem.
For further reading about inconsistent databases and consistent answers, see the monograph.8
Probabilistic Databases
A probabilistic database is a probability space over possible worlds (that is, ordinary databases). Restricting to the discrete case, which is the most commonly studied, we formally define a probabilistic database over a schema as a pair where is a countable set of databases over , and is, . The conventional semantics of query evaluation over a probabilistic database asks for the marginal probability of every answer. For a Boolean query, this amounts to computing the probability that the query is true on a random possible world. Formally, the task is to compute the probability that when is drawn randomly from :
As conventional in probabilistic modeling, we seek compact representations of probabilistic databases, where a finite object represents many possible worlds (for example, exponential number w.r.t. the size of the representation itself). Such representations rely on assumptions of probabilistic independence that, in turn, allow for factorization. The most studied representation is the Tuple-Independent Database (TID)11 (with roots in prior work, for example, Grädel et al.19). A TID is represented as an ordinary database where each fact is associated with a probability of existence. Then, a possible world is a subset of the database and it is randomly drawn by independently considering each tuple and deciding whether or not it is valid. More formally, a TID over a schema is represented as a pair where is a database over and assigns a probability to each fact. The pair represents the probabilistic database where consists of all the subsets of and
The computational complexity of query evaluation over TIDs has been scrutinized by the database community over the past two decades. As we shall see next, the probability of a query can be -hard even for very simple join queries. Past results have established thorough classifications of query classes into tractable and intractable, in either the exact or approximate sense. In this part, we explain the first dichotomy found for TIDs11 that considers the class of conjunctive queries without self-joins. We refer to it as the Little Dichotomy Theorem as it was later generalized to the broader class of all union of conjunctive queries (or, equivalently, the class of queries that can be phrased using the positive operators of the relational algebra).12
Before we give the dichotomy, let us illustrate it. For the positive side, let be the query . Given the input TID , we compute as follows. First, write as . Then, using tuple-independence, we have that:
The last expression has size , where .
An example of an intractable query is , which we denote by . We will show that is -complete through a reduction from a well known -complete problem.
A positive partitioned 2DNF formula (PP2DNF) is a DNF-formula of the form where the ’s and the ’s form disjoint sets of variables. Counting the satisfying assignments of a PP2DNF formula known to be -complete.32 We can visualize a PP2DNF as a bipartite graph, where the left and right sides consist of the and variables, respectively, and the edges correspond to the clauses. As an example, the graph of Figure 5a corresponds to the formula . If we view a truth assignment to the variables as stating whether a vertex is present or not, then a satisfying assignment corresponds to a non-independent set, that is, a set of vertices with at least one edge. Hence, the number of satisfying assignments is where is the number of variables and is the number of independent sets. Also, every bipartite graph represents some PP2DNF formula in this way. Thus, counting the satisfying assignments of a PP2DNF formula is the same as counting the independent sets of a bipartite graph.

Dalvi and Suciu11 showed that this problem can be simulated as the evaluation of over a TID, as we illustrate in Figure 5a. Let be the TID shown in Figure 5b. There is a one-to-one correspondence between truth assignments for and possible worlds for . The reader can easily verify that where is the number of variables of . Hence, we reduce #PP2DNF to .
The queries and are examples of hierarchical and non-hierarchical queries, respectively. As it turns out, the property of being hierarchical characterizes tractability. A conjunctive query without self-joins is hierarchical if for every two variables and of , either , or , or , where is the set of all atoms of where appears.
For example, our query , namely , is hierarchical, since . Query , namely , is not hierarchical since , , and yet, and have a common member, namely .
Figure 6 depicts the formal theorem that we refer to as the “little dichotomy theorem,” stating that being hierarchical characterizes being tractable (under standard complexity assumptions) as far as conjunctive queries without self-joins are concerned.

For further reading about probabilistic databases, we refer the reader to the monograph.34
Election Databases
Social choice theory is concerned with the aggregation of individual preferences into a collective outcome. Election databases form a framework that infuses social choice theory with relational database context. An election database may contain information about individual candidates (for example, age, education, wealth), voters (for example, age, occupation, affiliation), positions of candidates on various issues, and preferences of voters. This framework supports the formulation of sophisticated queries that go well beyond asking who the winners in some election are, which is the traditional focus of social choice theory. Ideally, each voter casts a complete preference, which is formalized as a total order of the candidates that the voter has to rank. It is often the case, however, that some voters can only cast incomplete preferences, which are formalized as partial orders of the candidates. Each such partial order represents the possible total rankings of the candidates by a voter, and different total rankings may produce different election outcomes. This constitutes a different mechanism for defining possible worlds.
To present a more rigorous treatment, we first recall the basic terminology of voting theory in computational social choice; for additional background, we refer the reader to the Handbook of Computational Social Choice.10 Let be a set of candidates, and let be a set of voters. A complete voting profile is a tuple , where each is a total order over , representing the ranking (preference) of voter of the candidates in . A voting rule is a function that maps every complete profile into a set of winners. We say that a candidate is a winner if .
We focus on the class of positional scoring rules, which is arguably the most extensively studied class of voting rules in computational social choice. A positional scoring rule maps every number of candidates to a scoring vector of natural numbers where . Here, is the score that a candidate is awarded when positioned th by a voter. The score of a candidate on the order of the voter is , where is the position of candidate in . When is applied to , it assigns to each candidate the sum as the score of . A candidate is a winner if her score is greater or equal to the score of every candidate. Popular positional scoring rules include the plurality rule where the winners are the candidates most frequently ranked first, the veto rule where the winners are the candidates least frequently ranked last, and the Borda rule , where the score of a candidate is the position itself minus 1 in reverse order.
To avoid trivialities, we assume that every contains at least two different score values, that is, . We also assume that the scores in are co-prime (that is, their biggest common divisor is 1), since multiplying all scores by the same number has no impact on the outcome. Rule is pure if for every , the scoring vector is obtained from by inserting a score value at some position. For example, essentially all specific rules studied in the literature (for example, plurality, veto and Borda) are pure.
A partial voting profile is a tuple , where each is a partial order over the set of candidates, representing a partially known preference of the voter . A completion of is a complete voting profile such that each is a completion of , that is, a total order that completes the partial order . A candidate is a necessary winner if for all completions .26 (We later discuss the analogous notion of a possible winner.)
An election database consists of a partial voting profile, along with a database that has contextual information about the candidates. Formally, it is a tuple that represents a set of possible worlds, where each possible world is a completion of . In turn, a completion of is obtained by taking a completion of , and adding to a new unary relation that has the fact for each winner . In particular, the possible worlds are identical, except for the content of the relation that depends on the underlying completion of . A Boolean query is necessary if for all completions of . (Note that “necessary” is the adaptation of the term “certain” to the election setting.)
As an example, let be a candidate and be the query . Then is necessary if and only if is a necessary winner. As another example, let be the query where can be thought of as representing a party of candidates. Necessity of means that there is necessarily a winner from . Note that it may be the case that is necessary even if no candidate in is a necessary winner, and even if there are no necessary winners at all.
We now discuss the problem of deciding the necessity of a Boolean conjunctive query under a positional scoring rule . This problem has two parameters, and , and the input consists of a candidate set , a partial profile , and a database .
An immediate observation is that the necessity problem is in coNP. Let us consider several examples of tractability and hardness. The simplest example is the query asking whether there exists a winner. By definition, there is always one or more winners, so this query is necessary on every election database (and the problem is trivially solvable in constant time). More interesting examples are the conjunctive queries depicted in Figure 7, namely,
for different , asking whether there are winners who participate in the -ary relation . In the remainder of this section, we discuss the proofs of the complexity results in Figure 7.

We begin with . In the case of plurality and veto, the polynomial-time algorithm is based on a polygamous version of the perfect-matching problem, where each vertex of one side should be matched with a number of neighbors from the other side, and this number is from an interval associated to the vertex. Hardness for the remaining pure rules is via a reduction from the problem of the possible unique winner: given a partial profile and a member of the set of candidates, is there any completion where is the single winner? Indeed, the complexity of this problem exhibits a classification analogous to the theorem: it is solvable in polynomial time under plurality and veto, yet NP-hard for every other pure rule.6
For , hardness for plurality and veto is proved via the maximum independent set problem, and hardness for any other pure rule is via a reduction from . Hardness for can be easily established via a reduction from . Interestingly, Kimelfeld et al.22 used a more complex reduction (from DNF tautology) that applies to all positional scoring rules, pure or not; hence, for the necessity problem is coNP-complete for every such rule.
We conclude this section with several comments. First, in the case of the plurality rule, a dichotomy in the complexity has been establish for a large fragment of conjunctive queries.21 Second, the necessity problem becomes tractable if we assume that the number of candidates is small. In particular, the problem is fixed-parameter tractable with respect to the parameter for every polynomial-time query.22
Concluding Remarks
The possible world semantics is a natural and principled approach to coping with deficiencies in data. We discussed the versatility of this approach in such deficiencies as missing information (null values), under-specified transformations (data exchange), violation of integrity constraints (inconsistent databases), and quantified uncertainty (probabilistic databases). When possible world semantics is adopted, query evaluation entails the aggregation of the results of the query over the possible worlds. The intersection of the results (certain/consistent answers) amounts to logical inference—these are the answers that are derived from the deficient data. Summation in probabilistic databases amounts to probabilistic inference—each answer is assigned its marginal probability. Other aggregation mechanisms have also been investigated. We touched on the union (possible answers) in passing, but did not cover the range semantics for queries with numerical operators, such as COUNT and SUM.5 There is also work on combinations of settings discussed here; relevant references are given in the online appendix.
The adoption of the possible world semantics increases the computational complexity since the number of possible worlds can be prohibitively large. Indeed, computational hardness already arises for frequently asked queries, such as conjunctive queries; we discussed several dichotomy theorems that strive to delineate the boundary between tractability and intractability for queries in a class. In practice, however, hard problems are often attacked by general-purpose tools, such as integer linear programming, SAT solvers, and answer-set programming, as done in consistent query answering,13,24 variants of consistent query answering9,30, and probabilistic databases.16,33
Beyond data management, the possible world semantics provides a natural approach to incorporating contextual data in the study of other settings that involve deficiencies. As a case in point, we illustrated this idea by discussing the framework of election databases. We believe that the versatility of the possible world semantics can have significant applications in a plethora of other fields.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment