
Artificial intelligence (AI) and machine learning (ML) are finding applications in many domains. With their continued success, however, come significant challenges and uncertainties. These include:
How much data is enough to train production-ready AI systems, and is it even feasible?
Is the data representative of the complete distribution of the problem being solved?
Are the results of the system transparent and explainable?
How is testing defined in the realm of AI systems?
Are AI systems truly usable in safety-critical environments?
What are the boundaries of the ethical use of AI systems?
This article examines testing in the realm of AI systems, focusing on one aspect of this challenge: namely, the quality of the test data (data on which an ML model is evaluated) in deep-learning systems. These systems, a subset of ML, are data-driven, and it is critical that after training these systems, they are evaluated on a test dataset that is a diverse representation of their training data distribution. Often, the test data might not have a balanced representation, leading to incorrect performance conclusions on these models.
Differential testing was used to generate test data to improve the diversity of data points in the test dataset; then mutation testing was used to check the quality of the test data in terms of diversity. The differential testing was done using DeepXplore3 and mutation testing using DeepMutation.2 Combining differential and mutation testing in this fashion improves the mutation score, a test-data quality metric, indicating overall improvement in testing effectiveness and quality of the test data.
Combining differential and mutation testing.
DeepXplore is a differential testing technique that uses differences in decision boundaries of multiple models for test-data generation. This enables it to discover many errors in behaviors of deep neural network (DNN) models. Using gradient ascent on test data to create data points that lie on the decision boundary of DNN models, it solves a joint optimization function to improve neuron coverage and correct several erroneous behaviors.
Mutation testing, a well-established technique for testing software systems, introduces mutants (bugs/faults) into a system to check if these mutants are correctly identified when the system is tested. DeepMutation, a mutation testing framework for deep-learning systems, achieves the same purpose through a collection of data, program, and model mutation operators that are used to inject errors into DNN models. The extent to which the implanted flaws could be recognized by executing these models on a test dataset can be used to assess the quality of test data. Figure 1 shows the general workflow of mutation testing.
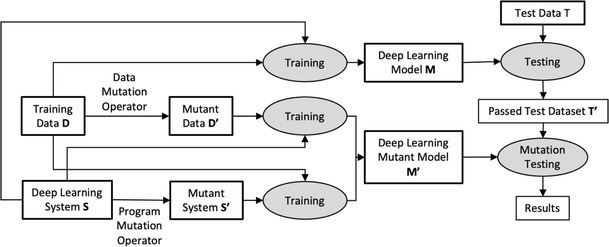
As shown in the figure, the complete test dataset T is executed against deep-learning system S, and only a subset of tests that pass T’ are used for mutation testing. All mutants in S’ are executed on T’, and when the test result for a mutant s’ ∈ S’ is different from that of S, then s’ is killed; otherwise, s’ survives. The mutation score is calculated as the ratio of killed mutants to all the generated mutants (that is, number of mutants killed / total mutants), which indicates the quality of the test dataset. The higher the score, the better it is.
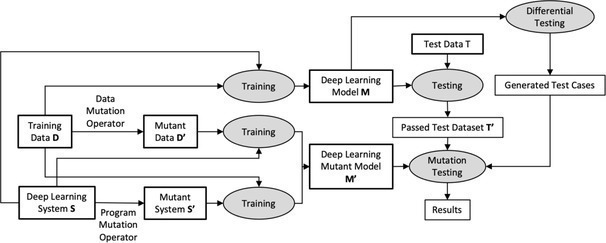
The mutation score evaluates how well the test data covers mutated models in terms of target class variety. To improve this coverage, the test dataset T is augmented by generating additional test cases using DeepXplore. Figure 2 shows the combined workflow when using differential and mutation testing.
Experiments and Results
The combined testing approach was used to run several experiments on the MNIST dataset,1 which contains handwritten digit images from 0 to 9. The dataset contains 60,000 training samples and 10,000 test samples. The experiments were run on three DNN models used in the DeepXplore study:
Model 1. Contains two conv2D layers and a Maxpooling2D layer. Conv2D layer 1 contains four filters with a 5*5 kernel, and conv2D layer 2 contains 12 filters with a 5*5 kernel. The single Maxpooling2D layer contains a 2*2 kernel. This is followed by a flatten layer and a dense layer with 10 units.
Model 2. Contains two conv2D layers and two Maxpooling2D layers. Conv2D layer 1 contains six filters with a 5*5 kernel, and conv2D layer 2 contains 16 filters with a 5*5 kernel. The Maxpooling2D layer contains a 2*2 kernel. This is followed by a flatten layer and two dense layers with 84 and 10 units.
Model 3. Contains the same structure of Model 2 but with three dense layers with 120, 84, and 10 units, respectively.
The model parameters are summarized in Table 1.
| Parameter | Model 1 | Model 2 | Model 3 |
|---|---|---|---|
| conv2D Layer 1 filters (5×5 kernel) | 4 | 6 | 6 |
| conv2D Layer 2 filters (5×5 kernel) | 12 | 16 | 16 |
| Maxpooling2D layer (2×2 kernel) | 1 | 2 | 2 |
| Flatten Layer | 1 | 1 | 1 |
| Dense Layer 1 Units | 10 | 84 | 120 |
| Dense Layer 2 Units | – | 10 | 84 |
| Dense Layer 3 Units | – | – | 10 |
| Total Parameter Count | 3,246 | 25,010 | 44,426 |
The experiments ran iteratively on subsets of training and test data: 5,000 images used as training data, and models evaluated on 1,000 images of the test data. Mutation models were created using 13 mutation operators on the source-data level, as well as the model level. These mutation operators are summarized in Table 2.
| Operator | Target | Description |
|---|---|---|
| Data Repetition (DR) | Data | Duplicates data |
| Label Error (LE) | Data | Falsify results of data |
| Data Missing (DM) | Data | Remove data |
| Data Shuffle (DF) | Data | Shuffle data |
| Noise Perturb. (NP) | Data | Add noise to data |
| Layer Addition (LAs) | Program | Add a layer |
| Act. Fun. Removal (AFRs) | Program | Remove activation functions |
| Gaussian Fuzzing (GF) | Model | Fuzz weight by gaussian distr. |
| Weight Shuffling (WS) | Model | Shuffle selected weights |
| Neuron Effect Block. (NEB) | Model | Block a neuron effect on following layers |
| Neuron Activation Inverse (NAI) | Model | Invert the activation status of a neuron |
| Neuron Switch (NS) | Model | Switch two neurons of the same layer |
| Act. Fun. Removal (AFRm) | Model | Remove activation functions |
A difference of 20% or less was the threshold between the accuracy of the mutated model and the original model on the test dataset. This threshold determined whether to use the mutation model for quantifying the quality of the test data.
These experiments led to a total of 12×10 = 120 iterations for each model, where the training data and testing data were different for each iteration (12 subsets of training data consisting of 5,000 images each from the 60,000 images in the MNIST training dataset; 10 subsets of test data consisting of 1,000 images from the 10,000 images in the MNIST test dataset). The mutation score was calculated for each iteration and then averaged for each model over the 120 iterations. Table 3 shows the average mutation score for each model.
| Model | Average Mutation score |
|---|---|
| Model 1 | 0.60 |
| Model 2 | 0.58 |
| Model 3 | 0.59 |
Next, differential testing was used to generate additional test cases, which were added to the existing test dataset; then the mutation testing experiments were rerun to see if the generated test cases improved the mutation score and, therefore, the quality of test data and the testing effectiveness. To generate the test dataset, three modifications (occlusion, blackout, and light transformation) were used on existing data points for which the models returned different outputs.
For these experiments, the number of random seed inputs was 500, the number of gradient ascent iterations was 10, the neuron activation threshold was 0.25, and the gradient ascent was done only on model 1. Also, the neuron coverage and differential data hyperparameters were set to 1 (the joint optimization problem for data generation).
Once the test cases were generated, a manual inspection was performed to remove unidentifiable generated images. The reasoning behind this comes from the fact that AI is nothing but an imitation of human actions, and if humans cannot identify an image, then neither would an AI system. Table 4 provides the number of test cases generated.
| Transformation | Number of test cases generated |
|---|---|
| Light transformation | 69 |
| Occlusion | 20 |
| Blackout | 51 |
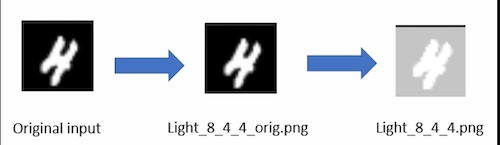
The new test cases were further classified into three categories (that is, test cases for each model). For each model, generated test cases were added that were predicted incorrectly by that model. This was because any generated test case can be considered as a corner-case data point since these data points are generated based on differences in decision boundaries of the model. For example, in Figure 3, the second image in the sequence is a differential test data point, and the third image is a modification of the test data point. In this case, the generated point was added to the test data of model 1, because it incorrectly predicts that point as 8 instead of 4, making it a corner-case point for that model. Table 5 shows the counts of generated test data for each model.
| Models | Number of test data generated for model |
|---|---|
| Model 1 | 105 |
| Model 2 | 87 |
| Model 3 | 78 |
Finally, the experiments were run using mutation testing for all three models, with the generated test cases as part of the test set to check if they truly improved the average mutation scores. A similar iterative approach to the previous experiment used 5,000 training data samples, but this time the test dataset had samples of 1,105, 1,087, and 1,078 for models 1, 2, and 3, respectively. Table 6 shows the results of the mutation testing experiments on the new test data samples.
| Model | Average Mutation score |
|---|---|
| Model 1 | 0.67 |
| Model 2 | 0.64 |
| Model 3 | 0.64 |
The same experiments had a significant increase in the average mutation score, which shows that the new test dataset has higher class diversity in terms of covering mutated models. The higher mutation score signifies that the test data has a better ability to kill the target classes of the mutated models, indicating a higher quality of the test data and testing effectiveness.
Conclusion
This work studied the effect on the quality testing of deep-learning systems when using mutation testing in combination with test cases generated using differential testing. Mutation testing allows the test-data quality to be assessed using a mutation score that checks how much of the test data kills the target classes of the mutated models. On average, these experiments showed an increase of about 6% in the mutation score, indicating improvement in testing effectiveness and quality of the test data when including generated test cases from differential testing in the test dataset for mutation testing.
Acknowledgment
This material is based on work funded and supported by the 2020 IndustryXchange Multidisciplinary Research Seed Grant from Pennsylvania State University.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment