
To measure progress on better methods for Web search, question answering, conversational agents, or retrieval from knowledge bases, it is essential to know which responses are relevant to a user’s information need. Such judgments of what is relevant are traditionally obtained by asking human assessors.
With the latest improvements on autoregressive large language models (LLMs) such as like ChatGPT, researchers started to experiment with the idea of replacing human relevance assessment by LLMs.9 The approach is simple: Just ask an LLM chatbot whether a response is relevant for an information need, and it does provide an “opinion.”
In recent empirical studies on Web search3 but also in programming,7 human–computer interaction,5 or protein function prediction,10 it has been shown that LLM-generated opinions often agree with the assessment of humans. Some people readily believe the decision on what is relevant can be outsourced to “AI” in the form of LLMs, without any involvement of humans.
However, as we argue here, there are severe issues with such a fully automated judgment approach—and these issues cannot be overcome by a technical solution. Rather than continuing with the ongoing quest to study where and how AI can replace humans, we suggest to examine forms of human–AI collaboration for which we lay out a spectrum in this column.
Why Not Just Use LLMs?
There are a number of issues that arise when we let LLMs judge the quality of search results or system-provided answers.
Judgment bias toward a particular LLM. If we use a particular LLM to create relevance judgments to measure system quality, it would likely favor results from systems that use the same or a similar LLM for response generation. Such a bias in the gold standard benchmark can lead to wrong findings when comparing multiple systems for quality.
Bias toward user groups. Bender et al.1 highlight the severe risk of LLMs to bias against underrepresented user groups. Such bias will likely be reflected in the relevance decisions made by the LLMs. Before using this technology, the computing community should develop approaches to quantify model bias and to understand possible ways of making LLMs more resilient when trained on biased data.
Resilience against misinformation. Some information on the Web may seem topically relevant, but may be factually incorrect and hence should not be perpetuated. For example, on an information request like “Do lemons cure cancer?” a system response may discuss factually incorrect information about healing cancer with lemons. While on topic, such potentially harmful responses should not be presented to a user. Factuality is already difficult for humans to assess correctly and without additional resilience mechanisms in place against misinformation, an LLM is unlikely to make correct relevance decisions in such situations.
LLM-based LLM training. In a world where LLMs are used both for judging relevance and for generating responses, the issue of concept-drift also arises. Rather soon, a lot of Web content will be LLM-generated. At the same time, new LLMs may be trained using large amounts of Web content. This would lead to a cyclic learning problem, where possibly various LLMs agree on a definition of relevance that may not make sense to human end users.
Judging vs. predicting. When a strong LLM is used to create relevance judgments for training a system to produce relevant responses, another question arises: Why not directly use the judging LLM to produce the response? There could be arguments with respect to reduced model size or improved response times, but still the trained system may not be able to surpass the quality of the judging LLM.
Truthfulness and hallucinations. A well-known issue of LLMs is that they tend to generate text that contains inaccurate or false information (that is, confabulations or hallucinations). Responses are often presented in such an affirmative manner that makes it difficult for humans to detect errors. While chain-of-thought reasoning8 or reinforcement from human feedback11 can reduce the issue, it remains unclear to which extent the problem can be avoided.
LLM relevance judgments for training only. Even when LLM-generated relevance judgments are only used to train a system—but not to evaluate it—many of these issues still hold. Following the “garbage in/garbage out” mantra, issues arising from biased judgments, misinformation, and confabulations or hallucinations will affect the quality of the end user-facing system.
LLMs Are the New Crowdworkers
It is yet to be understood what the benefits and risks associated with LLM technology are—especially when it comes to creating gold standards. A rather similar debate was spawned more than 10 years ago when a lot of data annotations started to rely on crowdworkers instead of trained editors—with a substantial decrease in annotation quality somewhat compensated by a huge increase in annotated data. Quality-assurance methods for crowdworkers were developed to obtain reliable labels.2 With LLMs, history may repeat itself: a huge increase in available relevance assessment data at a possibly decreased quality. However, the specific extent of the deterioration is still unclear and requires further study.
A related idea is to allow LLMs to learn by “observing” human relevance assessors or by following an active learning paradigm.13 Starting from LLM-generated relevance assessments that a human evaluates,17 the LLM could learn to provide better assessments. We believe humans working with LLMs is not only an option, but is likely unavoidable as shown by recent results indicating a large proportion of crowdworkers already make use of LLMs to increase their productivity.15
A Spectrum of Human–LLM/AI Collaboration
Rather than exploring options for LLMs to replace humans, or reasons why LLMs should not be used, we discuss a spectrum of options to combine human and machine intelligence in a complementary and collaborative fashion.
The spectrum outlines different levels of collaboration. At one end, humans make judgments manually, while at the other end, LLMs replace humans completely. In between, LLMs assist humans with various degrees of interdependence or humans provide feedback to decision-making LLMs. A summary of our proposed levels of human–machine collaboration is shown in the accompanying table. Here, we discuss each level in detail.
 human–
human–
 machine task organization to make (relevance) decisions. The △ symbol indicates where on the spectrum each possibility falls.
machine task organization to make (relevance) decisions. The △ symbol indicates where on the spectrum each possibility falls.| Collaboration Balance | Task Allocation |
|---|---|
| Human Judgment | |

| Humans decide what is relevant without any kind of AI support. |

| Humans have full control of deciding but are supported by machine-based text highlighting, data clustering, and so forth. |
| Model in the Loop | |
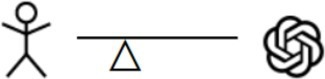
| Humans decide based on LLM-generated summaries needed for the decision. |
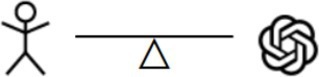
| Balanced competence partitioning. Humans and LLMs focus on decisions they are good at. |
| Human in the Loop | |
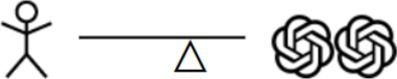
| Two (or more) LLMs each generate a decision and a human selects the best one. |
| An LLM makes a decision (and an explanation for it) that a human can accept/reject. |
| LLMs are considered crowdworkers: varied by specific characteristics, aggregated, and controlled by a human. |
| Fully Automated | |

| Fully automatic decision without humans. |
Human judgment. On one extreme, humans make all relevance judgments manually without being influenced by an LLM. The relevance assessment interface only supports well-understood automatic features that do not require any form of automatic training/feedback. For instance, humans may decide which keywords should be highlighted during assessment, they may limit viewing a certain data subset, or they may sort the data in certain ways that influence their decision. This end of the spectrum thus represents the status quo practiced in the field of information retrieval and natural language processing, where humans are considered to be the only reliable arbiter.
Model in the loop. To make it easier for human assessor to decide on relevance in a consistent manner, an advanced level of automatic support could be provided. For example, an LLM may generate a summary of a to-be-judged document and the human assessor then bases their relevance judgment on this compressed representation to complete a task in less time. Another approach could be to manually define information nuggets that are relevant12 and to then train an LLM to automatically determine how many test nuggets are contained in the retrieved results (for example, via a QA system). We hope to see more research on helpful sub-tasks that can be taken over by LLMs, such as highlighting of relevant passages and rationale generation.
An important open question is: How to employ LLMs and other AI tools to assist human assessors in devising more reliable and faster relevance judgments?
Human in the loop. Automated judgments could be produced by an LLM and then verified by humans. For instance, a first-pass automatic relevance judgment could come with a generated natural language rationale based on which a human accepts or rejects the judgment, or, following the “preference testing” paradigm,16 two or more LLMs each could generate a judgment while a human will select the best one. In such cases, a human might possibly only intervene in case of disagreements between the LLMs, thus increasing scalability. The purpose of this scenario is to simplify the decision for a human in most cases, and to use humans for difficult decisions or in situations where the LLMs generate a low-confidence decision.
Many issues identified in the field of explainability in machine learning apply to this scenario, such as the human tendency to over-rely on machines, or their inability to relate an LLM’s decision to its generated rationale.4 Thus, important open questions are: What are sub-tasks of the decision-making process that require human input (for example, prompt engineering14) and for what tasks should humans not be replaced by machines?
Fully automated. If LLMs were able to reliably judge relevance, they could completely replace humans when judging relevance. Indeed, a recent study showed a good correlation between LLMs’ relevance judgments and human assessors,3 both, for an agreement on every judgment decision as well as to the correlation of leaderboards that rank systems by quality obtained with either set of judgments. Automatic relevance judgments might even surpass those of humans in terms of quality. However, it is not entirely clear how to detect such super-human performance.
An important open question is: In which cases can human relevance judgments be replaced entirely by LLMs?
Interim conclusion. A central aspect to be investigated is where on this four-level human–machine collaboration spectrum one can obtain relevance decisions that are most cost-efficient, fast, fair, and high in quality. In other words: How can one achieve ideal competence partitioning,6 where humans would perform tasks humans are good at, while machines perform tasks that machines are good at.
Conclusion
We believe our current understanding is not sufficient to let LLMs perform relevance judgments without human intervention. Furthermore, we wish for more research on amplifying rather than replacing human intelligence using LLMs for judging the relevance of system responses, especially with respect to “model in the loop” and “human in the loop” scenarios. To this end, we proposed a spectrum of possible ways in which we can balance human and artificial intelligence to increase the efficiency, effectiveness, and fairness in decision-making processes such as relevance assessment.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment