The number of photos on the Internet is large and rapidly getting larger. The photo-hosting Web site Flickr uploaded its five-billionth picture on September 18, 2010, and Pingdom, a Swedish company that monitors Internet performance, estimated last year that Facebook is adding photos at a rate of 30 billion a year.
Such numbers present both a challenge and an opportunity for scientists focused on computer vision. The challenge lies in figuring out how to design algorithms that can organize and retrieve these photos when, to a computer, a photograph is little more than a collection of pixels with different light and color values. The opportunity comes from the enormous wealth of data, both visual and other types, which researchers can draw on.
“If you think of organizing a photo collection purely by the image content, it’s sort of a daunting task, because understanding the content of photos is a difficult task in computer science,” says Jon Kleinberg, professor of computer science at Cornell University. People look at two-dimensional pictures and immediately conjure a mental three-dimensional image, easily identifying not only the objects in the picture but their relative sizes, any interactions between the objects, and even broad understandings of the season, time of day, or rough location of the scene. When computers look at a photo, “they’re seeing it as a huge collection of points drawn on a plane,” notes Kleinberg.
But scientists are finding ways to extract the hidden information, using machine learning algorithms to first identify objects and then to uncover relationships between them, and by relying on hints provided by users’ photo tags, associated text, and other relationships between different pictures.
“In the old days we used to do image matching,” says Nuno Vasconcelos, head of the Statistical Visual Computing Laboratory at the University of California, San Diego. Computers would derive some statistical model of an example image and then look for matches with other images. “It works to some extent,” says Vasconcelos, “but it doesn’t work very well.” The programs would find low-level matches, based on factors such as color or texture. A beach scene, all sand and sky, might be matched with a picture of a train, with an equal amount of sky and a color similar to sand.
Nowadays, Vasconcelos says, the emphasis is on trying to understand what the image is about. Starting with a set of images labeled by humans, a machine learning algorithm develops a statistical model for an entire class of images. The computer calculates the probability that a picture is a beach scene—based on labels such as “beach,” “sand,” “ocean,” and “vacation”—and then matches the picture with other images with the same probability.
To train such algorithms, scientists need large sets of labeled images. While datasets with a few thousand photos exist, the algorithms become more accurate with much larger sets. Fei-Fei Li, an assistant professor at the Stanford Vision Lab, starting developing such a dataset in ImageNet, along with Kai Li, a computer scientist at Princeton University.
They started with WordNet, a hierarchical database of English words in which distinct concepts are grouped into sets of synonyms called synsets; there are 80,000 synsets just for nouns. The researchers entered each of the synonyms into Internet search engines to collect about 10,000 candidate images per synset. Then, using labor provided by Amazon Mechanical Turk, in which people earn small payments for tasks that require human input, they had people verify whether a candidate image contained the object listed in the synset. The goal is to have 500 to 1,000 images per synset. So far, they’ve amassed more than 11 million labeled images in about 15,500 categories, putting them between a third and halfway toward their goal.
About 100 people participated in the ImageNet Challenge last summer to see if they could use the dataset to train computers to recognize objects in 1,000 different categories, from “French fries” to “Japanese pagoda tree.” Once the computers have shown they can identify objects, Fei-Fei says the next objective will be to recognize associations between those objects. Noticing context can aid in object recognition, she explains. “If we see a car on the road, we don’t keep thinking ‘Is it a boat? Is it an airplane?’ “
Using Human Recognition
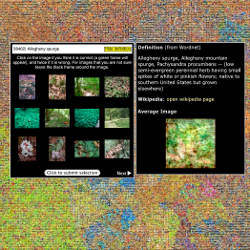
The Visual Dictionary project at the Massachusetts Institute of Technology (MIT) also seeks to develop a large dataset of labeled images, but relies on the fact that humans can recognize images even when they’re only 32 × 32 pixels. A Web page displays a mosaic representing 7.5 million images associated with 53,464 terms, with closely related words placed near each other on the mosaic. Each tile on the mosaic shows the average color of all the pictures found for that term, and clicking on it displays a box containing a definition and a dozen associated images. As people click on each tiny picture to verify that it matches the word, the computer records those labels. In another MIT project, LabelMe, the labeling gets even more specific, identifying not just a person, but heads, legs, and torsos, as well as roads, cars, doors, and so on.
The small size of these photos helps keep down the demand on computing capacity, but it also reveals something important about vision, says Antonio Torralba, an associate professor at MIT who heads the project. “If humans are able to do recognition at such low resolution, there are two possibilities. Either the human visual system is amazing or the visual world is not that complex,” he says. In fact, he adds, the world is complex. “Most of the information is because you know a lot about the world,” he says.
Scientists are extracting the hidden information in photos by using machine learning algorithms to identify objects and uncover relationships between them, and by relying on users’ photo tags and associated text.
The fact that much of the semantic content of a photo is actually supplied by the human viewing it leads researchers to try to derive clues about the content from what humans do with the pictures. Kleinberg makes the analogy with Web search, which not only looks at the textual content of Web pages, but also their structure, such as how they are organized and what hyperlinks they contain. Kleinberg uses the geotagging of photos to learn what they’re about, with the tags supplied either by Flickr users clicking on the Web site’s map or by GPS-based tags automatically created by a user’s camera. It turns out that sorting location tags on a 60-mile scale identifies population centers, and on a 100-meter scale identifies landmarks—the things people like to take pictures of.
For each of those scales, Kleinberg has the computer comb the textual description looking for the words whose use peaks most—not the most commonly used words but the words that are used more in one particular geographic area than any other. For instance, in one area the most outstanding word is Boston. Focusing on that region at the 100-meter scale finds the peak term to be Fenway Park. Pictures so labeled might actually be pictures of a car outside Fenway Park, or your dad at the ball game, or a pigeon on the Green Monster (the left-field wall at Fenway), but when the computer compares all the labeled photos to find the biggest cluster that are mutually similar to each other, a photo of the baseball diamond emerges as the typical image of Fenway Park. “There was no a priori knowledge built into the algorithm by us,” Kleinberg says.
Even with the growing datasets, more powerful processors, and constantly improving algorithms, researchers say the ability of computers to identify and organize photographs is still in its early stages. “There’s so much stuff that we still need to do, but it’s also true that we are doing a lot more than we were doing 10 years ago,” Vasconcelos says. “It really looks like 10 years from now we will be able to do a lot better than we can do today.”
 Further Reading
Further Reading
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L.
ImageNet: A large-scale hierarchical image database, IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, June 2025, 2009.
Crandall, D., Backstrom, L., Huttenlocher, D., and Kleinberg, J.
Mapping the world’s photos, Proceedings of the 18th International World Wide Web Conference, Madrid, Spain, April 2024, 2009.
Hays, J. and Efros, A.A.
IM2GPS: estimating geographic information from a single image, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, June 2328, 2008.
Torralba, A., Fergus, R., and Freeman, W.T.
80 million tiny images: a large dataset for non-parametric object and scene recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence 30, 11, Nov. 2008.
Vasconcelos, N.
From pixels to semantic spaces: advances in content-based image retrieval, IEEE Computer 40, 7, July 2007.




{kind=link}
Join the Discussion (0)
Become a Member or Sign In to Post a Comment