The wheels of big data science in the U.S. are turning at an accelerating rate.
The National Science Foundation (NSF) recently awarded grants in the second phase of a multi-year program to establish projects in data-driven science and to foster research partnerships among universities, corporations, non-profits, and government agencies. The idea is to harvest petabytes of data from diverse sources and use it to solve some of the biggest problems in society, in areas such as healthcare, manufacturing, education, energy, and finance.
For example, in one of 10 projects funded in the NSF’s three-year, $11-million Big Data Spokes program, the Massachusetts Institute of Technology, Brown University, and Drexel University will lead an effort to develop an automated licensing system for big data sets. The aim is to speed up by months the time it takes to get collaborative research projects off the ground. The overall project is coordinated by Columbia University and also includes Elsevier, Intel, Microsoft Research, Oracle, Rhode Island Hospital, and Thomson Reuters.
“There is no easy way to license data,” explained Fen Zhao, program director for the Big Data Hubs & Spokes program at the NSF. “You have to go through a lawyer and it takes six months to draft an agreement. It’s a big deterrent to data sharing.” Unlike open source software, which has just a few standard licenses, data is much trickier, she said. It may, for example, have restricted information—such as personally identifiable data—within it. Allowing for such complexities, as well as ensuring that licensees meet various restrictions, are the goals of this system.
The government’s partnership approach to research in big data dates to 2012, when the Obama Administration announced a $200-million research and development initiative among six federal agencies, including the NSF. Its goal was to “greatly improve the tools and techniques needed to access, organize, and glean discoveries from huge volumes of digital data,” a White House statement said at the time.
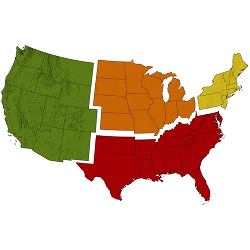
Last year, the NSF awarded $5 million to establish four Big Data Regional Innovation Hubs for data science innovation. The hubs, which represent consortia from the Midwest, Northeast, South, and Western regions of the U.S., are essentially planning and oversight bodies, each coordinated by one to three universities, for defining and then managing multi-sector, public-private projects in big data science.

In September, the NSF awarded $10 million to 10 Big Data Spokes, which are multi-party, multi-disciplinary teams aimed at research in specific application areas, such as data sharing. It also made available $1 million for related planning projects in areas of interest to big data researchers, such as the use of sensors to measure and monitor bridge safety.
Rene Baston of Columbia University in New York City is the executive director of the Northeast Big Data Innovation Hub, established last year. Baston said he has used his hub’s share of the 2015 funds to define and establish the data-licensing project, two other Spoke projects, and four planning projects. For example, one of the projects starts with the observation that most medical maladies are triggered only in part by inherited (genetic) factors. Many are also related to such external and disconnected factors as environmental toxins, weather, and socioeconomic forces.
Baston said a new three-year project, led by Columbia and Harvard Medical School, will look to integrate and enable analysis of a wide variety of such “exposome” data, including atmospheric data from the National Aeronautics and Space Administration, pollution data from the U.S. Environmental Protection Agency, and socioeconomic data from the U.S. Census Bureau. Harvard will lead in the creation of an integrated exposome database, and the University of Pittsburgh and Pennsylvania State University will develop causal analytic tools. “Nobody has really combined these data sets in an effective way,” Baston said.
The Northeast Hub has divided its Hub activities and Spoke projects into several broad vertical application areas, such as health, smart cities, and finance. In addition, it has defined four cross-cutting, or horizontal, areas: data literacy, data sharing, ethics, and privacy and security. Baston explains, “Mistakes in any of these [horizontal] areas will ripple through all the verticals we are trying to address.” In fact, he said, the biggest challenges to getting projects up and running are non-technical issues of organizational culture, intellectual property, government regulation, and data literacy.
The NSF’s current funding for Hubs and Spokes projects runs three years. During that time, the NSF will monitor progress while encouraging the players to seek funding from more local sources, including corporations, cities, foundations, and non-profits. “We view this as a long-standing program, but we want the hubs ultimately to be community-driven and self-sustaining,” said NSF program director Zhao.
That has already begun. In June, Microsoft Research awarded $3 million in Microsoft Azure cloud-computing credits to the four hubs.
Zhao also said the NSF asks—but does not require—that software developed for the program be made open-source, freely available to any user.
Meanwhile, big data scientists race to keep up. “There is no end to the growth in data,” Baston said. “While there is also a growth in individuals and organizations that are developing tools to handle the data, there aren’t enough to go around. Part of the role of the Regional Innovation Hubs is to create a framework to use data science resources that are available across sectors more effectively.”
Gary Anthes is a technology writer and editor based in Arlington, VA.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment