
Are computer scientists hypercritical? Are we more critical than scientists and engineers in other disciplines? Bertrand Meyer’s August 22, 2011 The Nastiness Problem in Computer Science blog post partially makes the argument referring to secondhand information from the National Science Foundation (NSF). Here are some NSF numbers to back the claim that we are hypercritical.
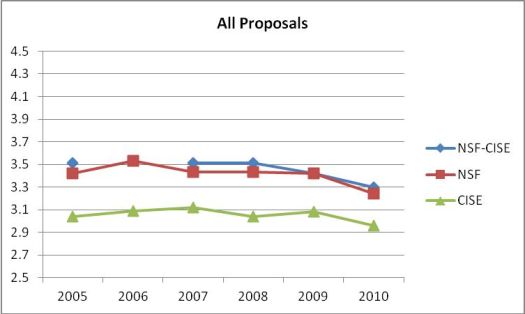
This graph plots average reviewer ratings of all proposals submitted from 2005 to 2010 to NSF overall (red line), just Computer & Information Science & Engineering (CISE) (green line), and NSF minus CISE (blue line). Proposal ratings are based on a scale of 1 (poor) to 5 (excellent). For instance, in 2010, the average reviewer rating across all CISE programs is 2.96; all NSF directorates including CISE, 3.24; all NSF directorates excluding CISE, 3.30.
Normal 0 false false false EN-US X-NONE X-NONE
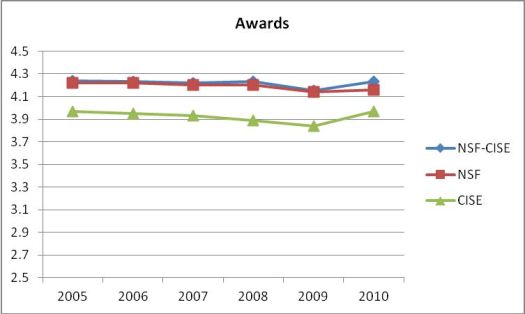
Here are the numbers for just awards (proposals funded)
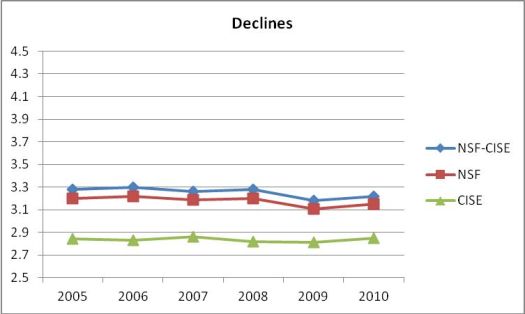
and just declines (proposals not funded):
Normal 0 false false false EN-US X-NONE X-NONE
The bottom-line is clear: CISE reviewers rate CISE proposals on average .41 points below the ratings by reviewers of other directorates’ proposals. The difference is a little better (.29 points) for awards and a little worse (.42 points) for declines.
How does our hypercriticality hurt us? In foundation-wide and multi-directorate programs, CISE proposals compete with non-CISE proposals. When a CISE proposal gets “excellent, very good, very good” it does not compete well against a non-CISE proposal that gets “excellent, excellent, excellent” even though a “very good” from a CISE reviewer might mean the same as an “excellent” from a non-CISE reviewer. In what foundation-wide programs can this hurt us? Some long-standing ones include: Science and Technology Centers (STC), Major Research Instrumentation (MRI), Graduate Research Fellowship (GRF), Integrative Graduate Education and Research Traineeship (IGERT), Partnerships for International Research and Education (PIRE), and Industry/University Cooperative Research Centers (I/UCRC). Some recent cross-foundational initiatives include: Cyber-enabled Discovery and Innovation (CDI); Science, Engineering, and Education for Sustainability (SEES); and Software Infrastructure for Sustained Innovation (SI2). Some recent multi-directorate initiatives include: National Robotics Initiative (NRI) and Cyberlearning Transforming Education (CTE). The one that was most painful for me when I was CISE AD was the annual selection from among NSF CAREER awardees of those whom the Director of NSF would nominate for the Presidential Early Career Awards for Scientists and Engineers (PECASE). To the foundation-level selection committee, I remember having to make forceful arguments for CISE’s top CAREER awardees because they had “very good”s among their ratings, whereas all other directorates’ reviewer scores for their nominees were “excellent”s across the board. What is the Director of NSF to do when deciding the slate of nominees to forward to the President?
Fortunately—or not—word had gotten around sufficiently within NSF: The CISE community is known to rate proposals lower than the NSF average. So my job was to continually remind the rest of the foundation and the Director about this phenomenon. It’s merely a reflection of our hypercriticality, not a reflection of the quality of the research we do.
Why are we so hypercritical? I have three hypotheses. One is that it is in our nature. Computer scientists like to debug systems. We are trained to consider corner cases, to design for failure, and to find and fix flaws. Computers are unforgiving when faced with the smallest syntactic error in our program; we spend research careers on designing programming languages and building software tools to help us make sure we don’t make silly mistakes that could have disastrous consequences. It could even be that the very nature of the field attracts a certain kind of personality. The second hypothesis is that we are a young field. Compared to mathematics and other science and engineering disciplines, we are still asserting ourselves. Maybe as we gain more self-confidence we will be more supportive of each other and realize that “a rising tide lifts all boats.” The third hypothesis is obvious: limited and finite resources. When there is only so much money to go around or only so many slots in a conference, competition is keen. When the number of researchers in the community grows faster than the budget—as it has over the past decade or so—competition is even keener.
What should we do about it? As a start, this topic deserves awareness and open discussion by our community. I’m definitely against grade inflation, but I do think we may be giving the wrong impression about the quality of our proposals, the quality of the researchers in our community, and the quality of our research. For NSF, I have one concrete suggestion. When one looks at reviews for proposals submitted to NSF directorates other than CISE, while the rating might say “excellent” the review itself might contain detailed, often constructive criticism. When program managers make funding decisions, they read the reviews, not just the ratings. So one idea is for us to realize that we can still be critical in our written reviews but be more generous in our ratings. I especially worry that unnecessarily low ratings or skimpy reviews discourage good people from even submitting proposals let alone pursuing good ideas.
It’s time for our community to discuss this topic. Data supports the claim that we are hypercritical, but it is up to us to decide what to do about it.
Please note these caveats about the numbers: (1) The spreadsheet from which I took these numbers has an entry for “NSF overall” and for each directorate. I derived the NSF-CISE numbers not using the “NSF overall” number, but rather subtracting the CISE number from the total of all directorates. This led to a small discrepancy in some of the numbers in the “NSF-CISE” numbers, but does not affect the bottom-line conclusion. (2) There is a lot of averaging of averages in these numbers. The “Awards” number for CISE, for example, represents the average of the average scores across all CISE programs, and similarly for the “Declines.” Looking across all NSF (and similarly CISE) programs, there is a wide variation in ratings and a wide range in the numbers of proposals submitted (and similarly awarded or declined). (3) Since I no longer have access to the raw data and my spreadsheet lacks comments, I cannot readily explain the discrepancies noted in (1) or how some of the numbers in the spreadsheet were calculated. I showed the 2010 numbers to the CISE Advisory Committee at the May 2010 meeting, pointing out that data for 2005-2009 are similar.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment