
Embodied Artificial Intelligence (EAI) integrates artificial intelligence into physical entities like robots, endowing them with the ability to perceive, learn from, and dynamically interact with their environments. This capability empowers these robots to provide goods and services effectively within human society. In this article, we draw parallels with the data value from the Internet sector to estimate the potential value of data within EAI. Furthermore, we delve into the significant challenges posed by data bottlenecks in the development of EAI and examine innovative data capture and generation technologies designed to overcome these obstacles.
1. Data is a Monetization Tool
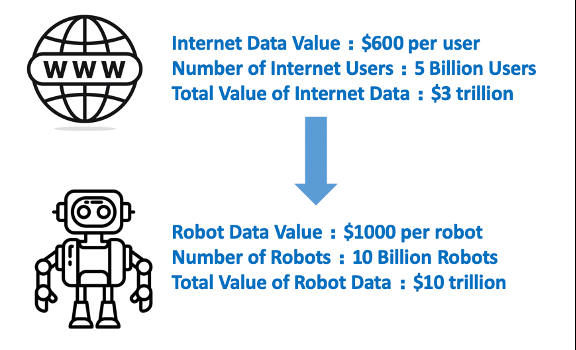
Figure 1: Data Monetization – Internet vs. Embodied AI
Credit: Shaoshan Liu
Data serves as a crucial tool for monetization in both the Internet and robotics sectors. Here, we explore the strategic value of data in EAI, drawing on the Internet sector as a historical benchmark.
In the Internet sector, companies leverage user data primarily for targeted advertising and personalized content. This targeted approach not only increases sales but also boosts user engagement, which can lead to higher subscription fees or increased usage. Meanwhile, in the EAI sector, data is pivotal for training deep learning models that enhance and optimize robotic capabilities.
Financially, user data represents significant value to Internet companies, estimated at $600 per user [3], and considering the estimated cost of $35,000 per robot after mass commercialization [4], and we conservatively project that robotic companies are willing to invest about 3% of the cost of each robot into data collection and generation. This investment is aimed at developing advanced EAI capabilities, leading to an estimated market value of EAI data exceeding $10 trillion—triple that of the Internet sector.
This analysis highlights the immense potential data for EAI, and today the data collection and generation industry for EAI is still in its nascent stages.
2. The Data Bottlenecks for Embodied AI
While the future of the EAI data industry looks bright, today the scalability of EAI systems is critically hampered by significant data bottlenecks. Unlike Internet data, which primarily consists of user-generated inputs that are relatively straightforward to collect and aggregate, data for EAI involves complex interactions between robots and their dynamic environments. This fundamental difference means that while Internet data can be mined from user activities across digital platforms, EAI data must capture a myriad of physical interactions within varied and often unpredictable settings.
For example, while the readily accessible chat data allows ChatGPT 4 to be trained with 570 GB of text [5], demonstrating remarkable proficiency in chat tasks, training an EAI model requires significantly more robotic data due to its multimodal nature. This robotic data, encompassing various sensory inputs and interaction types, is not only extremely challenging but also costly to collect.
The first challenge of training EAI is access to extensive, high-quality, and diverse datasets. For example, autonomous navigation robots need to process a vast array of environmental data to enhance their path planning and obstacle avoidance capabilities. Additionally, the precision of data directly impacts robotic performance; industrial robots engaged in high-precision tasks require extremely accurate data, where minor errors can lead to significant issues in production quality. Furthermore, a robot’s ability to adapt and generalize across different environments hinges on the diversity of data it processes. Home service robots, for example, must adapt to various domestic settings and tasks, requiring them to learn from a wide range of home environment data to improve their generalization skills.
The second challenge of training EAI is “data silos”. Acquiring such comprehensive data is fraught with challenges, including high costs, lengthy time requirements, and potential security risks. Most EAI robotics organizations are confined to collecting data within specific, controlled environments. The lack of data sharing among entities exacerbates the situation, leading to duplicated efforts and resource wastage, and creating “data silos.” These silos significantly hinder the progress of EAI.
3. Data Capture and Generation
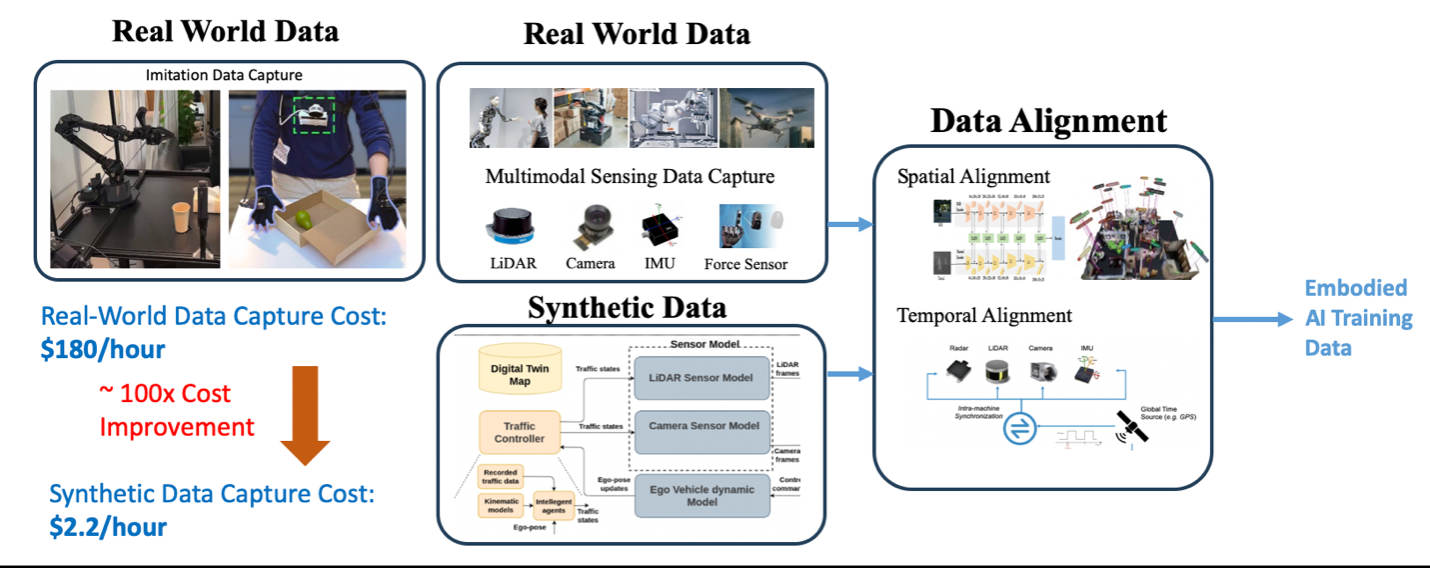
Figure 2: Data Capture and Generation
Credit: Shaoshan Liu
To tackle the data availability bottleneck in the development of EAI, a robust data capture and generation pipeline is essential. Figure 2 illustrates the architecture of such a pipeline.
The first component of this pipeline involves capturing real-world data. This includes collecting data from human interactions with the physical environment for imitation learning, as seen in research projects like Mobile-Aloha [6], which captures complex interaction tasks, and PneuAct [7], which focuses on capturing data related to human hand actions. Additionally, the pipeline involves the collection of data from multimodal robotic sensors to capture the robot’s perception of its physical surroundings.
Second, given that acquiring a large amount of high-quality and diverse EAI data is prohibitively expensive, digital twin-based simulation has proven to be an effective solution [8]. It significantly reduces data collection costs and enhances development efficiency. For example, capturing one hour of multimodal robotic data for an autonomous vehicle costs $180, whereas simulating the same data costs only $2.20—a reduction by nearly 100 times [9]. Furthermore, advancements in Sim2Real technology facilitate the transfer of skills and knowledge from simulated environments to real-world applications [10]. This technology trains robots and AI systems in virtual spaces, allowing them to learn tasks safely and efficiently without the physical risks and constraints of the real world. Thus, a combination of real-world and synthetic data is a strategic approach to overcome the challenges of data availability in EAI.
Lastly, it is crucial that both collected and generated data undergo temporal and spatial alignment. This ensures that data from various sensors is both accurate and synchronized, providing a unified and detailed understanding of the robot’s environment and actions [11]. Only after these processes can the data be effectively used to train EAI systems.
4. Conclusion
This article examines the role of data in EAI and estimates that the market for data collection and generation in EAI could surpass $10 trillion, potentially tripling the value of the internet data market. Unlike the straightforward collection of Internet data, gathering EAI data involves complex interactions within dynamic environments, making it an expensive and challenging endeavor. To address these challenges, we introduce a data capture and generation pipeline that utilizes Sim2Real technology, blending real-world data collection with digital twin-based simulations to reduce costs and enhance development efficiency. Currently, a primary obstacle in applying Sim2Real technology is the “reality gap”—the discrepancies between simulated environments and the real world, including differences in physics, lighting, and unexpected interactions. Overcoming this gap requires innovative techniques such as domain randomization, which incorporates a diverse array of scenarios into simulations, and domain adaptation, which adjusts the AI’s responses to better align with real-world conditions. These strategies are crucial for effectively bridging the gap between simulated training and real-world application.
References:
- Savva, M., Kadian, A., Maksymets, O., Zhao, Y., Wijmans, E., Jain, B., Straub, J., Liu, J., Koltun, V., Malik, J. and Parikh, D., 2019. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 9339-9347).
- Wolford, B., 2024. What’s your data really worth?, https://proton.me/blog/what-is-your-data-worth, accessed 2024/04/08
- Why Elon Musk thinks Earth will have more robots than humans, The Telegraph, https://www.telegraph.co.uk/business/2024/04/01/elon-musk-earth-more-robots-than-humans, accessed 2024/04/08
- The Tesla Robot: What will ‘Optimus’ be able to do and how much will it cost?, The Sun, https://www.thesun.co.uk/tech/21845043/tesla-robot-optimus-cost/, accessed 2024/4/08
- Hughes, A., 2023. ChatGPT: Everything you need to know about OpenAI’s GPT-3 tool. BBC Science Focus Magazine, 16.
- Fu, Z., Zhao, T.Z. and Finn, C., 2024. Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation. arXiv preprint arXiv:2401.02117.
- Luo, Y., Wu, K., Spielberg, A., Foshey, M., Rus, D., Palacios, T. and Matusik, W., 2022, April. Digital fabrication of pneumatic actuators with integrated sensing by machine knitting. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems (pp. 1-13).
- Yu, B., Tang, J. and Liu, S.S., 2023, July. Autonomous Driving Digital Twin Empowered Design Automation: An Industry Perspective. In 2023 60th ACM/IEEE Design Automation Conference (DAC) (pp. 1-4). IEEE.
- Yu, B., Chen, C., Tang, J., Liu, S. and Gaudiot, J.L., 2022. Autonomous vehicles digital twin: A practical paradigm for autonomous driving system development. Computer, 55(9), pp.26-34.
- Kadian, A., Truong, J., Gokaslan, A., Clegg, A., Wijmans, E., Lee, S., Savva, M., Chernova, S. and Batra, D., 2020. Sim2real predictivity: Does evaluation in simulation predict real-world performance?. IEEE Robotics and Automation Letters, 5(4), pp.6670-6677.
- Liu, S., Yu, B., Liu, Y., Zhang, K., Qiao, Y., Li, T.Y., Tang, J. and Zhu, Y., 2021, May. Brief industry paper: The matter of time—A general and efficient system for precise sensor synchronization in robotic computing. In 2021 IEEE 27th Real-Time and Embedded Technology and Applications Symposium (RTAS) (pp. 413-416). IEEE.
Shaoshan Liu is affiliated with the Shenzhen Institute of Artificial Intelligence and Robotics for Society of the Chinese University of Hong Kong, Shenzhen. He is currently a member of the ACM U.S. Technology Policy Committee, and a member of the U.S. National Academy of Public Administration’s Technology Leadership Panel Advisory Group. His educational background includes a Ph.D. in computer engineering from the University of California, Irvine, and a master’s degree in public administration from Harvard Kennedy School of Harvard University.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment