
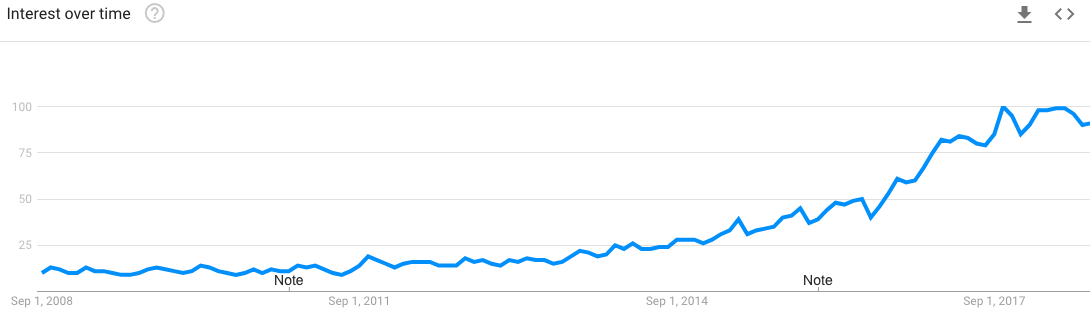
Machine learning seems to be everywhere you look now! This image shows the rising interest in Google searches for “machine learning” from 2008-2018.
Throughout the past decade, the growing availability of cloud computing power and open-source frameworks have made it much easier to implement machine learning systems than in the past. For instance, popular frameworks such as TensorFlow, Keras, PyTorch, Caffe, and Theano have greatly lowered the barriers to writing machine learning code in languages such as Python. Even more recently, JavaScript-based frameworks such as TensorFlow.js, ConvNet.js, and Brain.js have made it possible to experiment with machine learning (ML) directly in web browsers.
However, ML wasn’t always this accessible to programmers. Before a decade or so ago, it was much harder to get started in experimenting with ML because these convenient software frameworks did not yet exist. I had vague memories of my graduate school colleagues struggling to write robust and reusable ML scripts by hand, often borrowing arcane code passed down from their former labmates. That made me curious about how people wrote ML code in the past, so I posted the following question on Twitter:
Folks who were writing machine learning code over 10 years ago, even if it was in school (2008 and earlier): what languages/libraries/frameworks did you use back then?
I was pleasantly surprised to receive around 200 direct replies to my tweet, along with many more retweets whose threads I can’t easily find anymore. In this blog post, I’ll summarize the most salient findings from this very informal and unscientific survey. Thanks to everyone who responded!
The Late 2000s
Let’s start by going back a decade or so. Python started gaining prominence amongst ML programmers around the mid- to late-2000s with the emergence of scikit-learn, along with other maturing scientific libraries (e.g., numpy, scipy).
Although Matlab was still popular, some ex-Matlab programmers moved over to Python during this era due to its growing open-source ecosystem. @christiankothe wrote that he did “most [ML] in MATLAB from scratch, also reusing others’ solvers. Was dreaming of replacing it all by Python some day (well, that happened).”
Java was also still fairly prevalent during this era, along with the wildly popular Weka graphical environment for prototyping ML algorithms.
The Early 2000s
Matlab and Java were the most prominent amongst ML researchers in the early 2000s. Some Matlab programmers wrote their models from scratch, while others purchased custom toolboxes. Several also mentioned using freely-available libraries from Kevin Murphy and his students.
In contrast, nobody mentioned frameworks for Java, and many reported writing their own bespoke code: “Wrote everything from scratch in Java. There’s nothing like the feeling of actually understanding your code.” (from @togelius) More generally, I saw this common sentiment of things feeling harder back in those days but simultaneously being more transparent since everyone was forced to understand their own code rather than leaning on frameworks or libraries.
Several people also mentioned C and C++ during this era, especially for performance-sensitive code that ran in production or on embedded devices.
The 1990s
C and C++ were cited most frequently during this era, and frameworks/libraries were pretty much absent. @carmenfontana wrote, “1999 C++ with no libraries or frameworks… Very old school” and @eigenhector added, “I used C++, STL and some hand coded SSE intrinsics. Frameworks? None — we just wrote them from scratch.”
Google AI lead Jeff Dean (@JeffDean), co-creator of TensorFlow, mentioned getting his ML start in C: “Wrote parallel training code for neural networks in C in 1990 (undergrad senior thesis project)”
A few people also mentioned Lisp and Prolog during this era, although it was unclear whether they were working on ML specifically or on other more symbolic forms of AI at the time. Some also used Matlab during this era as well, but it was not nearly as popular as it was in the early 2000s.
The 1980s and earlier
I didn’t get many responses that explicitly mentioned the 1980s and earlier, but the few who chimed in listed Lisp (very popular during the early 1980s AI boom), C, Prolog, and Fortran. @chrisbogart mentioned:“C, for neural networks and genetic algorithms, in 1989-1990. I don’t recall using any libraries.”
But by far the winner for oldest ML programming memory goes to @wgl8: “Fortran II for Electrocardiogram recognition and analysis. This was in 1969. First service of its kind. No libraries–it was all hand written. One path that we abandonned was using XPL, but reverted to Fortran.”
Parting Thoughts
That’s about it! Other less common languages mentioned in this informal survey include Perl, R, Stata, Scala, Lua, and Haskell. I want to conclude with two quotes that elegantly capture the contrasts between the “good/bad old days” and the modern framework-driven ML era:
The first is from @greglinden: “C (+ Perl for sysadmin) in late 1990 at Amazon, C only in early 1990 for research. No frameworks back then, all from scratch. Also important, computation and data x100-1000 smaller. Not just tools available now, also data and computation the tools enable.” I like how he mentioned the co-evolution between advances in tooling and the parallel increase in the amount of computation and data that our modern tools can handle.
@pbloemesquire wrote: “The wealth of well-designed, well maintained frameworks we have today really didn’t exist yet. We had too many different directions to choose from.” I think this is an interesting perspective because I would’ve thought that we had more choices today, but I can see how standardization around the few most popular frameworks would make it easier to get started now. Frameworks actually constrain choices, which can be a good thing if they’re well designed for their users’ needs.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment