
Originally posted on Distant Whispers
Federated Learning (FL) is a widely popular structure that allows one to learn a Machine Learning (ML) model collaboratively. The classical structure of FL is that there are multiple clients each with their own local data, which they would possibly like to keep private, and there is a server that is responsible for learning a global ML model.
In this article, we discuss the constant back and forth that has been going on for the last 5 years or so in protecting the privacy of data through FL. Just when it looks like FL is able to keep local data private, out comes a study to deflate us.
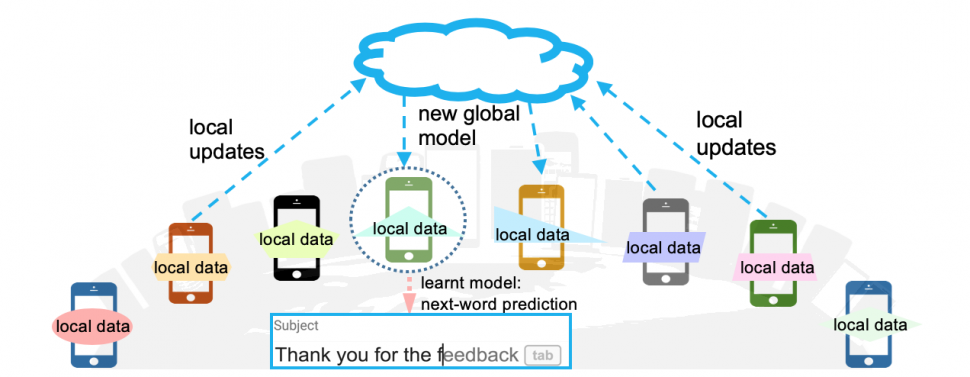
How did this fuss get started?
One of the two primary reasons for the popularity of FL is that clients can keep their data private and still benefit from the combined learning across all of their data. (The second reason is the “power of crowds” — many weak devices can come together to learn complex models, which would be beyond the compute power of any one client to learn on its own.) However, by 2018, this hope of FL had been effectively dashed. It was shown in a set of seminal papers that if the central aggregator has access to gradients sent by the clients (which it does in most versions of FL), then the aggregator can learn various things from these clients, each of which would be taken to effectively break the privacy of client data. The simplest to understand form of this attack is that the aggregator can reconstruct the data of the clients, to different degrees of fidelity. The attacker, the central aggregator here, has the unique advantage that it can observe the individual updates from the clients over time and can control the view of the participants of the global parameters. Also worryingly, the attacker could be one of the clients who can observe the global parameter updates, and can control his parameter uploads.
The categories of data leakage attacks
Broadly, there are two approaches to the data leakage attacks:
- Optimization attacks
- Analytic reconstruction attacks
Optimization attacks work starting with a dummy randomly initialized data sample and optimizing over the difference between the true gradient and the one generated through the dummy sample. The second category, analytic reconstruction attacks, involve customizing the model parameters or the model architecture to directly retrieve the training data from the gradients of a fully-connected (FC) layer — this is also referred to as linear layer leakage attacks.

A Volley of Shots Back and Forth
The next consequential arrow shot in this battle was from the defender’s side — secure aggregation. Back in 2017, a team of engineers from Google had unveiled the technique of secure aggregation [1] where clients use cryptographic techniques to compute a secure aggregate of their individual gradients. The server then uses this aggregate to do its usual processing and come up with the next iteration of the global model. This turned out to be very effective in thwarting data leakage attacks. Secure aggregation guaranteed that the server and any client in the FL setting will not gain access to individual model updates of other clients, only the aggregate from all clients. This was a strong defense, especially coupled with the fact that training happened in batches of increasing sizes (batch size = 1 makes it easier for the attacks).

Credit: “Trading is heavy today” by Tom Cheney, New Yorker Cartoons, March 28, 2017.
This is where the happy state of affairs stood till 2022. Then, a group of researchers from CMU [2] came up with a powerful analytic type attack. They showed that a malicious server by making inconspicuous changes to the Neural Network architecture (and the associated parameters) can breach user privacy. The key intuition behind this work is that the attacker introduces a malicious linear layer (synonymous with fully connected layer) and controls its weights and bias and this allows the attacker to leak gradients.
In the ongoing saga, hope for privacy was raised by the fact that in a common form of FL called FedAverage, averaging happens at each client over multiple data items and multiple iterations of such averaging happen before a communication is sent to the server. There is a second trend that made the attack less effective in practice — FL is increasing in scale in terms of the number of clients. These attacks do not handle that well and the reconstruction becomes very error prone with increasing number of clients, to the point where one can argue that data is not being leaked after all.
The latest salvo in the battle is by our work, Mandrake [3], which allows an attacker to reconstruct data even with a large number of clients in FL. The key idea here that enables Mandrake to remove the scale bottleneck of previous attacks is the introduction of a carefully crafted convolution layer in front of the fully connected layer. Further, this convolution layer is specialized for each client. Consequently, even in the secure aggregated output, the server can make out which client has contributed what.
So where do we go next?
Federated Learning is far too important a technology to be stopped in its tracks due to the fear of data leakage. What this implies is that we will develop stronger defenses that will make data reconstruction practically impossible (under reasonable numbers of clients, batch size for local aggregation, …).
Most previous works had been focused on recovering sensitive user data from gradient updates with focus on either very small batch sizes or architectural modifications that are neither realistic nor easily deployable in practice under common threat models. We are now observing elevated attacks that are targeting high stake domains and tabular data [4], model agnostic- typically require small modifications to the the model parameters-and also target new concerns such as disparate impact baked in privacy attacks [5], sybil devices that facilitates the sensitive user data reconstruction leveraging power imbalances [6], and various data and model poisoning to increase user data recovery risks.
The story will evolve with exciting discoveries on both the attack and the defense side. One big direction on the defense side that is under explored today is the age-old security trick of shuffling. In this case, that means shuffling of the updates from the clients so that a server cannot know which update came from which client. Another dimension that remains to be explored is can clients collaborate to form cliques and thus defeat the privacy leakage attempts by a server. The technical term that is used in the literature for the server is “honest but curious.” In plain speak, this is simply a server that is being too nosy for my (or any client’s) liking.
References
1. Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS), pages 1175–1191, 2017. 2. Fowl, L.H., Geiping, J., Czaja, W., Goldblum, M. and Goldstein, T., Robbing the Fed: Directly Obtaining Private Data in Federated Learning with Modified Models. In International Conference on Learning Representations (ICLR), 2022. 3. Zhao, Joshua C., Ahmed Roushdy Elkordy, Atul Sharma, Yahya H. Ezzeldin, Salman Avestimehr, and Saurabh Bagchi. "The Resource Problem of Using Linear Layer Leakage Attack in Federated Learning." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3974-3983. 2023. 4. Vero, Mark, Mislav Balunovic, Dimitar Iliev Dimitrov, and Martin Vechev. "TabLeak: Tabular Data Leakage in Federated Learning." (2023). 5. Wen, Yuxin, Jonas A. Geiping, Liam Fowl, Micah Goldblum, and Tom Goldstein. "Fishing for User Data in Large-Batch Federated Learning via Gradient Magnification." In International Conference on Machine Learning, pp. 23668-23684. PMLR, 2022. 6. Boenisch, Franziska, Adam Dziedzic, Roei Schuster, Ali Shahin Shamsabadi, Ilia Shumailov, and Nicolas Papernot. "Reconstructing Individual Data Points in Federated Learning Hardened with Differential Privacy and Secure Aggregation." In 2023 IEEE 8th European Symposium on Security and Privacy (EuroS&P), pp. 241-257. IEEE Computer Society, 2023.
Saurabh Bagchi is a professor of Electrical and Computer Engineering and Computer Science at Purdue University, where he leads a university-wide center on resilience called CRISP. His research interests are in distributed systems and dependable computing, while he and his group have the most fun making and breaking large-scale usable software systems for the greater good. Arash Nourian is General Manager/Director of Engineering at the AWS AI. He is a technical executive with deep expertise in AI, Data Science, Engineering and Product leadership. He is building theory and tools that make AI more accessible, responsible, robust, and green.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment