
Most people in the technical world are now familiar with some version of this Artificial Intelligence (AI) Venn Diagram…
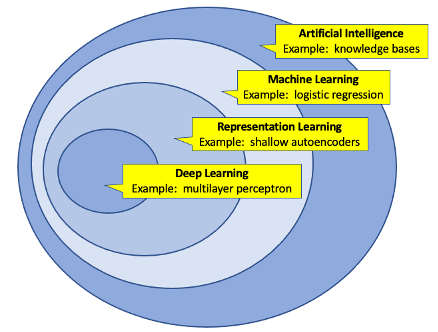
Credit: author’s re-creation of Deep Learning (Goodfellow, Bengio, Courville) – 2016 edition, page 9.
… which describes the relationship between various sets of AI techniques, including machine learning and deep learning. There are many excellent books and articles describing those topics and how they can be implemented in various software frameworks, and those descriptions will not be repeated here. There also are many articles on Big Tech implementing AI at scale. But how do “regular” organizations implement AI projects successfully, especially within an existing portfolio of solutions? In the BLOG@CACM post “Anna Karenina On Development Methodologies,” I described how the famous opening line “happy families are all alike, unhappy families are unhappy each in their own way” applies to software development. This post will describe in a similar vein the development behaviors which have the highest chance of success for AI efforts.
The AI Project Bootstrapping Dilemma
Pick A Use-Case
Or at least, pick a few candidate problem/opportunities to research. This is “they say” advice that is obvious but necessary to repeat, because it is true. There is a marketing tendency to want to sprinkle AI on everything and see what grows with the hope that something magical will happen. IBM’s Watson AI business was notorious for this when it referred to its namesake AI framework as “Cognitive Computing” back in the Watson Health era, a phrase which implied a great many things but meant nothing specific and had the effect of inflating customer expectations to an unmanageable degree.
It is also easy to get blinded in a myriad of potential AI technical implementation issues and lose sight of the analytic goals for what was originally supposed to be clustered, categorized, or predicted. The adage about alligators and draining the swamp applies.
Multi-Level Alignment
In the BLOG@CACM post “Developing Technical Leaders,” I described common levels of leadership progression in software engineering, ranging from individual contributor to tech-lead/senior individual contributor to team lead to manager. AI efforts are a prime example of the necessity of multi-level alignment, because any successful effort needs things such as:
- A technical person who can do the work
- A technical person who can get the project approved
… and these abilities rarely exist in the same person. Sometimes with an organization there is a staff member with an idea but with no ability to get it prioritized, and sometimes there might be leaders with a general idea for an AI effort, but with no ability to execute.
Multi-level alignment also applies to use-case selection as well, as there can be a difference between “executive understanding” of use-cases and those that experience pain-points in person. Both are valuable perspectives, but they are distinct. This represents the second set of multi-level alignment for stakeholders:
- Someone who can speak to the use-case with specificity
- Someone who can advocate for the use-case and get it prioritized
As on the technical side of the house, those people are rarely the same.
Establish An AI Baseline
Per the Venn diagram above, making sure that the everyone on the project team is using the same vocabulary and can explain things such as the difference between unsupervised and supervised learning, the difference between a classifier and regression, and common steps in required data preparation, is important. This includes the stakeholders because understanding these concepts as much as possible is essential for expectation management, as these aren’t just “implementation details,” it is about understanding the actual art of the possible, and what is realistic.
As the outer circle of concepts that “AI” contains is quite large, start with the basics and go from there.
Data Investigation
Data is where the rubber hits the road with AI projects, and it is why having individual contributors who understand both the relevant technology and problem space is so critical for effective data research. Never take for granted the following questions:
- For the problem being researched, is there enough data available?
- For the data that exists, how clean is it?
- What data governance is relevant for the context?
A project team might be instinctively digging into an actual bona-fide problem area only to find that there is not enough data to support the proposed analytics, or at least analytics with desired outcomes. Likewise, even when data exists, the reason why people repeat the quip “80% of data science is data preparation” is because it’s true — so, so painfully true. Lastly, understanding relevant data governance is a requirement especially in regulated industries, such as healthcare. “Why can’t you use test or fake data for this project?” is a common compliance response with respect to both AI and Natural Language Processing (NLP) efforts. While fake data is suitable for basic solution development in terms of having characters to display on a page or basic report, when trying to predict something in the real world one generally needs real data, or something very closely approximating the real thing — the generation of which is often an even harder problem than just using real data itself. The more critical the use-case, the more real and comprehensive the training data needs to be. AI and NLP efforts tend to raise non-trivial governance questions, and my BLOG@CACM post “Data Governance And The Psychology Of Tension Management“ describes some of the challenges where data needs to be protected, but also needs to be utilized to be useful.
The Power Of Feedback
Flying a plane is an activity that, on the surface, looks sort of easy when conditions are perfect, until they aren’t, and then things get complicated in a hurry. But it’s not just about the plane, as Malcolm Gladwell described in his book Outliers when discussing the concept of Power Distance and mitigation in communication. How the crew talks about solving problems is arguably even more important than the underlying problems themselves, as the communication approach plays a critical role not just in managing a crisis, but also preventing the further compounding of errors.
There are parallels in software development. Let’s say that an AI use-case was selected at the executive ranks. Even if the use-case was chosen with the best of intentions, the use-case might not be ready for AI for some of the reasons already stated above. Now what? The best situation would be for all (including the executive team) to learn and understand what was impeding that AI use-case and try to remedy, and the remedies may be beyond what the project team can do by themselves — especially if changes are required in a source system. Actions on the other end of the spectrum would be for the project team to continue to bang their collective heads on the original use-case instead of pivoting to research another one, either for fear of “being wrong” or fear of delivering bad news up the chain. High-quality AI is not typically something that can be summoned by executive decree.
Operationalize
It is natural to start with the prototypes or pilots as stand-alone efforts, but eventually the output needs to be integrated with the rest of the solution portfolio for maximum organizational benefit. The “last analytic mile” can be a tough one as in healthcare settings, for example, providers spend an inordinate amount of time in electronic medical record systems looking at, and entering, patient data. Asking providers to log into a second, third, or fourth set of solutions to see patient analytic results adds to the workload, especially when seeing 15, 20, or more patients a day. There might be some amazing supplemental AI analytic dashboards in the portfolio, but there also might not be enough time to view them in the workflow when extra context switching is required.
In Conclusion
My BLOG@CACM “Anna Karenina” post described velocity as a foundational attribute in software development. Frequent software releases can’t guarantee success, but sporadic releases and inconsistent funding have doomed more products and solutions to failure than any other reason. Similarly, early AI results could be a bit rough in the beginning. Keep learning, and keep iterating.
References
- BLOG@CACM
- Developing Technical Leaders
- Data Governance And The Psychology Of Tension Management
- Anna Karenina On Development Methodologies
- What Happened To Watson Health?
- Power Distance
- Malcolm Gladwell On Plane Crashes
- Especially on mitigation during crisis communication
- Malcolm Gladwell On Plane Crashes
Doug Meil is a software architect in healthcare data management and analytics. He also founded the Cleveland Big Data Meetup in 2010. More of his BLOG@CACM posts can be found at https://www.linkedin.com/pulse/publications-doug-meil



Join the Discussion (0)
Become a Member or Sign In to Post a Comment