
Central to any data-mining project is having sufficient amounts of data that can be processed to provide meaningful and statistically relevant information. But acquiring the data is only the first phase. Often collected in an unstructured form, this data must be transformed into a structured format for suitable for processing.
Within the past few years there has been an increase of free web crawler datasets, but for many applications it’s still necessary to crawl the web to collect information. And if the data mining pieces weren’t hard enough, there are many counterintuitive challenges associated with crawling the web to discover and collect content. The challenges become increasingly difficult when doing this on a larger scale.
In practice, capturing the content of a single web page is quite easy. Here is a simple crawler that uses the command-line tool wget:
wget – r –html-extension –convert-links –mirror –progress=bar –no-verbose –no-parent –tries=5 -level=5 $your_url
If you want to capture the content of multiple pages there exists a wealth of open source web crawlers, but you’ll find many of these solutions are overkill, often designed to crawl the web in a very large-scale, distributed manner. This article focuses on the challenges of collecting specific types of web data for data mining project on a smaller scale; by exploring three of these challenges (creating the URL frontier, scheduling the urls, and extracting the information) and potential solutions.
Creating the URL Frontier
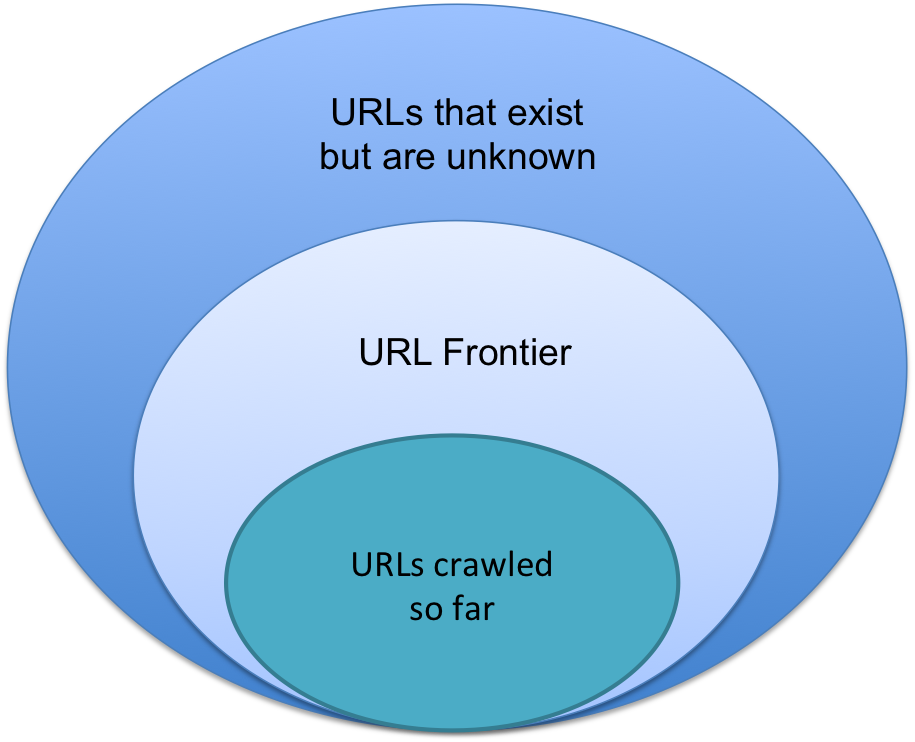
A URL frontier is the collection of URLs that the crawler intends to fetch and process in the future. URL frontiers generally work in one of two ways – a batch crawl or a continuous crawl. A batch crawl’s frontier contains only new URLs, whereas a continuous crawl’s can contain a seed set of URLs but new ones may be added (or existing ones removed) during the crawl.
Regardless of the type of crawl, the data store used to manage the frontier needs to be fast because it will slow down crawling otherwise. Below is a diagram that helps illustrate the URLs in a crawl frontier.
Crawling is quite simple at its core:
- Select a URL to crawl
- Fetch and parse page
- Save the important content
- Extract URLs from page
- Add URLs to queue
- Repeat
Of course the details around URL discovery is quite complicated depending on your application (you may not want every URL on that page for example). Adding logic around which URLs to select to crawl (selection), and which URLs to filter (often times an easy restriction is to set your filters to only apply to specific domains and ignore all others) can help ensure that your crawl is tightly targeted to your target content/data.
One way to create your URL frontier is to define a seed set of URLs or domains and crawl them to extract and discover new links. Post processing the links to normalize them can help reduce duplication and is a good best practice to follow. Another example of this post processing is filtering the links before adding them to the frontier, such as restricting links to specific domain or using an algorithm to order the URLs in a priority that makes sense the application and goals of the crawl.
(For more information on this check out this Stanford paper on URL scheduling and ordering)
Crawling and Scheduling
When it comes to crawling there are many details that allow one to do this quickly and at scale. If your crawl is less than 100 million pages, and you have time such that you don’t need to distribute the crawling across servers, then crawling and scheduling is more manageable. The coordination of distributed crawling across several servers can get difficult quickly (and since it is much more complicated I will have to leave those details for a future post).
When it comes to fetching and parsing a page, there are several steps involved for each url:
- DNS lookup
- Fetch robots.txt
- Fetch URL
- Parse content
- Store results
For the DNS lookup and robots.txt rules one can likely cache these such that any subsequent URLs from the same IP will be much faster and won’t require a trip across the network.
Tip: For DNS lookups, many of the built-in toolkits are synchronized by default, so it helps to configure this to achieve parallelism and speed.
Of course, it is important any crawler obeys the rules in robots.txt file, which may exclude all or parts of the domain.
(More details on this exclusion protocol can be found at http://www.robotstxt.org/wc/norobots.html )
Another important aspect of crawling is choosing which URLs to crawl and in what order.
If you are doing a continuous crawl it is important to think about when you may re-crawl a page. Certain parts of the Internet are changing all the time (such as news sites like http://www.cnn.com) and should be crawled regularly as they have new content, are high authority sites, or are important sources of data.
Remember the importance of politeness. Your crawler should not make too many simultaneous requests as they can overwhelm underpowered servers. Best practice is to wait 2 seconds between requests for the same IP.
Tip: Don’t sort input URLs or you will be waiting between calls. Randomize the order of URLs across domains.
Scheduling is not just about selecting which URLs to crawl, but is also about tracking the URLs that you have crawled so far. If you have a small crawl (<100 Million URLs), it probably makes sense to store these in memory otherwise your application performance can suffer reading from disk or across the network. It is possible to store URLs in plain text, although using a bloom filter (http://en.wikipedia.org/wiki/Bloom_filter) to hash URLs makes reading and writing much faster.
And finally, as new URLs are discovered it is important to normalize them to remove duplicates.
For example, many pages are expressed relative to the main domain. Such that a link might be /about.html, but would need to be transformed into: http://katemats.com/about.html. And since many URLs in the wild have query parameters (such as those used for analytics or session information), it is easy to come across many different versions of a URL that reference the same web page. These extraneous parameters typically have to be removed or normalized so that the only URL that is crawled is the canonical version of the page.
Using the rel=”canonical” tag (to read more check out Google’s documentation) can serve as a signal if the page is a duplicate, but it is not used everywhere, so it is worth implementing a fingerprinting algorithm. Using and algorithm like shingling can help detect the same or near-duplicate pages.
When it comes to crawling there are a handful of open source crawlers to consider some listed below:
Extracting the information
Once the crawler is configured the last piece of the puzzle is extracting and structuring the data from different web pages.
The most important part of parsing web pages is that your parser is able to deal with messy markup and will be resilient to errors. Chances are you will want some smart logic that removes the page chrome (like navigation, headers/footers, search boxes, advertisements, etc.) so that only data is returned. It is also important to consider more than ASCII text, as it is common to run across Unicode URLs and content.
If you are trying to crawl the entire web there are more things to consider as the Internet is full of junk such as enormous or never-ending pages, with spider traps that look like dynamic content but are actually an infinite generation of links.
Once you have the html content it is necessary to navigate the page and DOM to find the specific parts of the page relevant or important to your cause. And then of course storing that information in a structured form, which may mean converting it to JSON, or transforming it to fit a schema and inserting it into the database. Thankfully, there are a lot of extractors for parsing web pages as listed below:
- Scrapy (scraping and crawling framework)
- Mechanize
- Beautiful Soup
- Boilerplate (used to remove the chrome around web pages)
A little bit different, but good for pulling out article text from pages is Readabillity.
And there you have it! Hopefully this is a good intro into collecting some web data by crawling, if you have other links or resources, please include them in the comments.
References
http://pdf.aminer.org/000/003/078/crawling_the_web.pdf
http://nlp.stanford.edu/IR-book/html/htmledition/web-crawling-and-indexes-1.html
http://pdos.csail.mit.edu/~strib/docs/tapestry/tapestry_jsac03.pdf
http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
http://pdos.csail.mit.edu/papers/chord:sigcomm01/chord_sigcomm.pdf



Join the Discussion (0)
Become a Member or Sign In to Post a Comment