
Modern high-performance computing (HPC) systems are characterized by a complex structure and may contain thousands of computing elements connected by a computer network. The use of different types of computing cores and network protocols leads to a heterogeneous system. In order to effectively use such a computing complex, special software products have been created. To improve performance, they use as many nodes as possible by distributing tasks among them.
Performing distributed computing involves a combination of two main tasks. The first is to assign new elements to be used to parallelize computational processes. The second one is to exchange data between cooperating elements during calculations. In this post, we will talk about improving HPC performance using virtual coordinates by taking network latency into account.
For parallelization, HPC uses a virtual network topology that can be created and configured at the administrator’s discretion. At the same time, the physical interconnection scheme of the cores, which is formed during the installation of the cluster’s computational network, is often ignored. Computing networks used in HPC are characterized by high performance, so the network bandwidth is sufficient to allocate virtual channels of the required capacity. This is why the actual HPC network infrastructure is often ignored.
When using artificially created virtual network topology as well as random distribution of elements during parallelization, network routes of data exchange turn out to be far from the shortest. In this post, we discuss how to build the shortest paths between elements. In this case, the found algorithms will remain operable even when individual nodes of the cluster are overloaded.
A route is a sequence of intermediate elements through which data packets are transmitted between the start and end elements. Route construction is a classical problem solved in computer network theory. Each route hop is characterized by a special metric function that depends on the routing protocol. For the entire route, the metric function is found as the sum of the values for separate hops. From the entire set of possible routes, the one with the minimum value of the metric function is chosen.
One of the possible ways to construct routes in HPC is the virtual coordinates method [1]. The introduction of the coordinate system involves setting anchors. They must be installed in such a way that:
- the number of anchors was minimal, and
- the coordinates of each computational element were unique; that is, they did not repeat.
Specifying a coordinate system involves assigning several variables, which are called coordinates, to each element. The choice of these variables is determined by the routes from the investigated elements to the anchors and depends on the metric function.
Note that building a route using the metric function resembles the principle of least action in physics. The traffic served on the route should be chosen as the metric function [2]. The network latency should be used as the metric function for the route hop. If the network is homogeneous and its capacity is the same, then the number of route hops can be used as the metric function.
The choice of the metric function gives a hint about the coordinate’s construction. First, anchors are marked, with respect to each, the corresponding coordinate component is found. This can be either the network latency to the anchor or the number of hops. Thus, each element receives a set of coordinates (Ai Bi, Ci, Fi) [3].
The following features of the proposed coordinate system should be noted. Firstly, it is not orthogonal, it is impossible to choose basis vectors. Secondly, all coordinates take only positive values. This feature means that it is not possible to determine the direction in which packets are moving.
To build a route, we should use the greedy promotion algorithm. For any route between elements i and j, a vector Mij describing the relative position of the elements is constructed. Coordinates of this vector
![]()
(1)
The greedy forwarding algorithm determines the next route element for an arbitrary element k. If the element j is the end element of the route, then the element k must send a packet to its neighbor element l, for which the dot product MkiMkj takes the maximum value. That is, the element l will be chosen that provides the maximum advance to the end element j.
The scalar product is standardly defined as the sum of the products of the corresponding coordinates of two vectors:
![]()
(2)
The formulated rule makes it easy to build any route. The proposed method can also be used for route construction in congested networks. If an overload occurs, the element is temporarily considered inoperable and the route is built to bypass it. Once the element is restored, it can immediately be used as an intermediate route element.
Using network latency as a coordinate allows for a new approach to parallelization technologies. To perform parallel computing, the administrator must assign nodes with minimum network latency between them. In order to facilitate this process, all computational elements should be divided into clusters. Within a cluster, the latency between any two elements must not exceed a certain threshold. The low latency clusters will be inside the high latency clusters. Thus, by changing the latency values of the thresholds, a hierarchical structure of nested clusters can be obtained.
In order to illustrate this approach, a series of tests was carried out on the HPC “Afalina.” It was launched at Sevastopol State University in 2021 and has an estimated peak performance of 178 TFLOPS. Multi-threaded processors are used as CPU elements.
We are interested in the following types of latencies:
The measurements provided data on the minimum, average, and maximum latencies of various types. The results of measurements using packages of the minimum size are included in the Table.
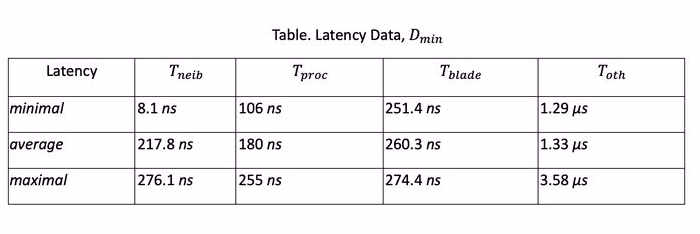
Since the latency of various types differs many times, a test was performed to improve the HPC performance. Weather forecast calculation using a Weather Research and Forecasting (WRF) model was chosen as a test task. With normal parallelization, without taking into account latencies, the program execution time was 27 minutes. The new parallelization mechanism used neighboring threads of the same core, which immediately reduced the program execution time to 22 minutes. That is, the performance gain turned out to be about 20%.
It should be noted that the latency values T in the Table are given for packets of the minimum size. As the size of the transmitted packet increases, the latency increases according to the affine function
![]()
(3)
where Dmin is the minimum latency value from the Table, W is the size of the packet exchanged between the elements, B is the available bandwidth of the HPC network.
For a sufficiently large packet size W, the second term of Eq. (3) becomes dominant. So with a packet size W of 1.25 KB and an available bandwidth B of 10 Gbps, it can be estimated at 1 μs. That is, the relative difference in delay
![]() will greatly decrease with increasing packet size W.
will greatly decrease with increasing packet size W.
Therefore, it is necessary to take this effect into account during parallelization. When assigning new computational elements, it is necessary to consider not only the minimum latency Dmin, but also the packet size W for data exchange. The larger this size, the more remote compute elements can be used without performance loss. We are currently trying to automate this process.
References
[1] Dhanapala, D. C., Jayasumana, A. P. (2011, October). Anchor selection and topology preserving maps in WSNs—A directional virtual coordinate based approach. In 2011 IEEE 36th Conference on Local Computer Networks (pp. 571-579). IEEE.
[2] Sukhov, A. M., Chemodanov, D. Y. (2013). A metric for dynamic routing based on variational principles. Journal of High Speed Networks, 19(2), 155-163.
[3] Romanov, A., Myachin, N., Sukhov, A. (2021, October). Fault-tolerant routing in networks-on-chip using self-organizing routing algorithms. In IECON 2021–47th Annual Conference of the IEEE Industrial Electronics Society (pp. 1-6). IEEE.
Anton Demin is an associate professor at Joint HPC laboratory of Sevastopol State University and Samara University, Samara, Russia. e-mail: ad2271@yandex.ru. Oleg Shakhov is a System Administrator at Joint HPC laboratory of Sevastopol State University and Samara University, Samara, Russia. e-mail:omshakhov@mail.sevsu.ru. Andrei Sukhov is a Senior Member of ACM, and a professor at Joint HPC Laboratory of Sevastopol State University and Samara University, Samara, Russia. e-mail: asukhov@acm.org.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment