
こんにちは。ようこそ!… Hello and welcome!
The ACM Community is excited to host the first ACM Special Interest Group on Information Retrieval (SIGIR) Conference ever in Japan this month, in Tokyo. According to an e-mail memo dated August 2 from Tetsuya Sakai of the Organizing Committee, 882 registrants (a whopping 53% increase from SIGIR 2016) will “witness the most exciting SIGIR ever, and also a very crowded one” (after all, this is Tokyo).
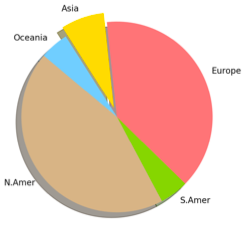
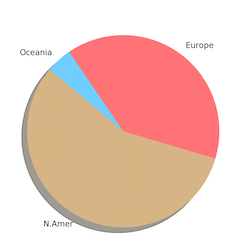
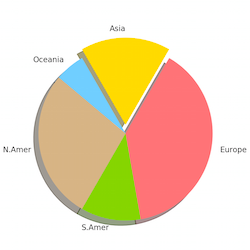
1(a) All SIGIRs 1(b) SIGIRS by continent 1(c) SIGIRS 2000 and after
Figures 1 (a-c, left-to-right) Location of ACM SIGIR Conferences by continent.
Out of curiosity, I looked up the history of SIGIR Conferences and found that hosting countries and participants have become more diverse in recent years (ref: http://sigir.org/general-information/history/ ). A quick comparison of pie charts of hosting venues by continent (Figures 1a-c) shows a clear movement from a North American-European focus towards the inclusion of Asia, South America, and Oceania. This globalization of venues is commendable since students and scientists from the host country participate at a higher rate than usual due to convenience and reduced costs. The longer-term, positive impact of attending a prestigious, international conference as a student is well-known.
As a member of the ACM NLP community, I am also interested in shifts in the technical content. NLP work presented at SIGIR has traditionally focused on English data (and maybe a few works in European languages that share the same alphabet). Given the statistics on the diversification of SIGIR conferences, will work on languages with different alphabets and grammatical structure receive greater attention? Consider a very simple example to illustrate my point: to understand the meaning of sentences, English requires a great deal of work for unambiguous stemming, while Japanese requires identification word/phrase boundaries (since there are no spaces between words), followed by accurate parts-of-speech tagging to identify the roles of nouns and verbs in sentences.
In addition to language-based work, I am also interested to learn about regional differences in the adoption of NLP-based applications. For example, the acceptance of digital assistants by consumers will depend on preferences regarding GUIs, policies on the storage and use of personal data, ease-of-use on mobile devices, etc. I look forward to hearing about diverse approaches and productive – and possibly passionate – debate on their pros and cons.
I am planning to blog on my experience as an attendee so please stay tuned. では、また! … until we meet again!
Mei Kobayashi is manager, Data Science/Text Analysis at NTT Communications.


Join the Discussion (0)
Become a Member or Sign In to Post a Comment