
Embodied Artificial Intelligence (EAI) involves embedding artificial intelligence into tangible entities, such as robots, equipping them with the capacity to perceive, learn from, and engage dynamically with their surroundings. In this article we delve into the key tradeoffs of building foundation models for EAI systems.
1. Foundation Models for Embodied AI
Previously, we have outlined three guiding principles for developing embodied artificial intelligence (EAI) systems [1]. EAI systems should not depend on predefined, complex logic to handle specific scenarios. Instead, they must incorporate evolutionary learning mechanisms, enabling continuous adaptation to their operational environments. Additionally, the environment significantly influences not only physical behaviors but also cognitive structures. While the third principle focuses on simulation, the first two principles emphasize building EAI foundation models capable of learning from the EAI systems’ operating environments.
A common approach for EAI foundation models is to directly utilize pretrained large models. For example, pretrained GPT models can serve as a baseline, followed by fine-tuning and in-context learning (ICL) to enhance performance [9]. These large models typically possess a substantial number of parameters to encode extensive world knowledge and feature a small context window for fast response times. This extensive pre-encoding allows these models to deliver excellent zero-shot performance. However, their limited context windows pose challenges for continuous learning from the EAI systems’ operating environments and connecting various usage scenarios.
Alternatively, another approach leverages models with significantly fewer parameters but a larger context window. These models, rather than encoding comprehensive world knowledge, focus on learning how to learn, or meta-learning [2]. With large context windows, these models can perform general-purpose in-context learning (GPICL), enabling continuous learning from their operating environments and establishing connections across a broad context.
Figure 1 illustrates these two different approaches. The meta-training + GPICL approach, while exhibiting poorer zero-shot performance and having a smaller model size, excels in continuously learning from its environment, eventually specializing EAI systems for specific tasks. In contrast, the pretraining + fine-tuning + ICL approach, characterized by a larger model size and smaller context windows, offers superior zero-shot performance but inferior learning capabilities.
Empirical evidence supporting this is found in the GPT-3 paper, where a 7B Few-Shot model outperforms a 175B Zero-Shot model [3]. If few-shot learning is replaced by a long context window enabling EAI systems to learn from their operating environments, performance may further improve.
We envision an ideal foundation model for EAI that should meet several critical criteria. Firstly, it should be capable of universally learning from complex instructions, demonstrations, and feedback without relying on crafted optimization techniques. Secondly, it should demonstrate high sample efficiency in its learning and adaptation processes. Thirdly, it must possess the ability to continuously learn through contextual information, effectively avoiding the issue of catastrophic forgetting. Therefore, we conclude that the meta-learning + GPICL approach is suitable for EAI systems. However, before we decide on taking this approach, let us first examine the tradeoffs between these two approaches.
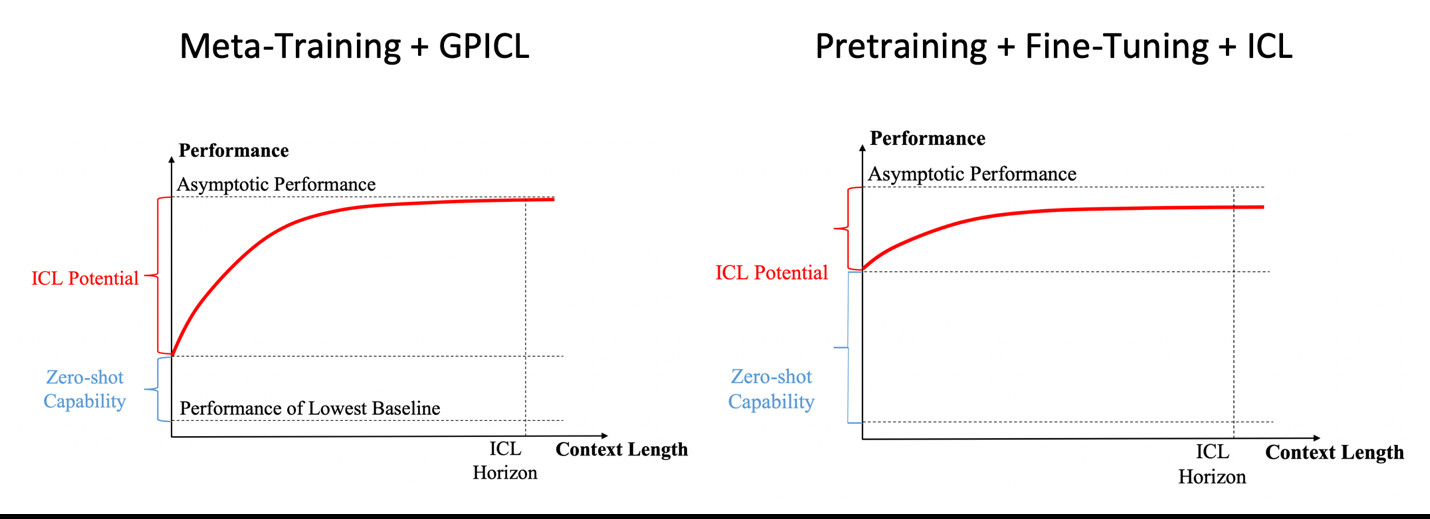
Figure 1: Foundation Model Options for EAI.
Credit: Fan Wang
2. Key Tradeoffs
Table 1: Tradeoffs of Pretrained large model vs. meta-training + GPICL
Credit: Fan Wang
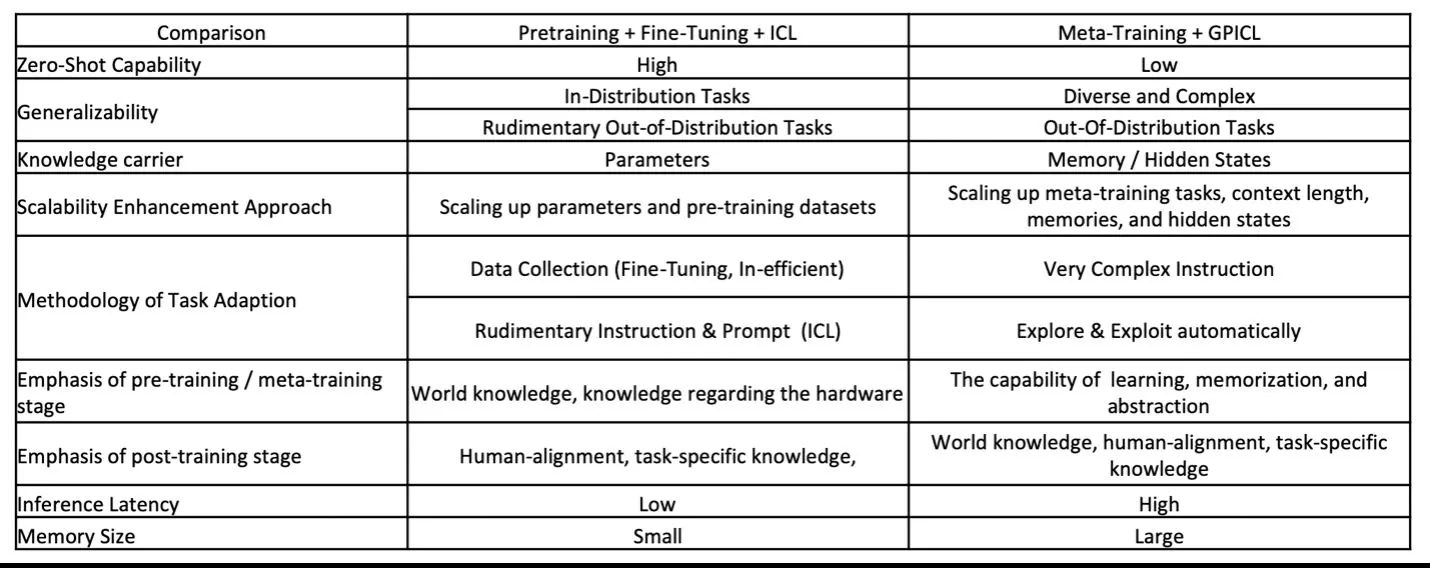
In this section, we review the tradeoffs between pretrained large models vs. meta-training + GPICL as foundation models for EAI [4]. The results are summarized in Table 1.
For zero-shot capability, the Pretraining + Fine-Tuning + ICL approach [9] offers high performance, allowing models to generalize well to new tasks without any task-specific fine-tuning. In contrast, the Meta-Training + GPICL approach exhibits low zero-shot capability, as it focuses on learning to adapt to a wide variety of tasks using in-context learning rather than zero-shot generalization.
In terms of generalizability, the Pretraining + Fine-Tuning + ICL approach performs well on in-distribution tasks but has rudimentary capabilities for out-of-distribution tasks. Meta-Training + GPICL, on the other hand, exhibits diverse and complex generalization capabilities for out-of-distribution tasks due to its emphasis on meta-training over varied contexts.
The scalability enhancement approach for Pretraining + Fine-Tuning + ICL involves scaling up parameters and pre-training datasets to improve performance. Meta-Training + GPICL enhances scalability by scaling up meta-training tasks, context length, memories, and hidden states to improve the model’s adaptability.
Regarding task adaptation, Pretraining + Fine-Tuning + ICL relies on data collection and fine-tuning, which can be inefficient. In contrast, Meta-Training + GPICL utilizes very complex instructions and learns from diverse contexts automatically.
During the pre-training or meta-training stage, Pretraining + Fine-Tuning + ICL focuses on world knowledge and understanding the hardware. Meta-Training + GPICL emphasizes the capability of learning, memorization, and abstraction over a wide variety of tasks.
In the post-training stage, Pretraining + Fine-Tuning + ICL involves aligning the model to specific human-centric tasks, emphasizing human-alignment and task-specific knowledge. Meta-Training + GPICL continues to emphasize world knowledge, human-alignment, and task-specific knowledge.
Inference latency is generally low for Pretraining + Fine-Tuning + ICL as the model parameters are fixed after training. However, for Meta-Training + GPICL, inference can be slower due to the need to utilize and update memory and hidden states dynamically.
Memory size requirements for Pretraining + Fine-Tuning + ICL are small, as most knowledge is embedded in fixed model parameters. Conversely, Meta-Training + GPICL requires significant memory to handle complex instructions, extended context, and hidden states.
Meta-Training + GPICL offers the advantage of enabling the system to continuously learn various tasks through contexts, i.e., learning to continuously learn [7]. This essentially requires the system to be able to learn new tasks without forgetting the old one, which typically poses great challenge for gradient-based fine-tuning (catatrophic forgetting [8]) but can be less a challenge with in-context learning.
3. Overcoming the Computing and Memory Bottlenecks
From the above comparison, it is evident that meta-training combined with GPICL offers superior adaptability and generalization across diverse and complex tasks. However, this approach demands higher resources, posing a challenge for most EAI systems, which are often real-time edge devices with limited computational capabilities and memory. The large context windows required for this approach can significantly increase inference time and memory footprint, potentially hindering its feasibility for EAI foundation models.
Fortunately, recent advancements have introduced innovative solutions to scale Transformer-based Large Language Models (LLMs) for processing infinitely long inputs while maintaining bounded memory and computational efficiency. A notable innovation is the Infini-attention mechanism, which integrates masked local attention and long-term linear attention within a single Transformer block. This enables the efficient processing of both short and long-range contextual dependencies. Additionally, the compressive memory system allows the model to maintain and retrieve information with bounded storage and computation costs, reusing old Key-Value (KV) states to enhance memory efficiency and enable fast streaming inference. Experimental results demonstrate that the Infini-attention model outperforms baseline models in long-context language modeling benchmarks, showing superior performance in tasks involving extremely long input sequences (up to 1 million tokens) and significant improvements in memory efficiency and perplexity scores.
Similarly, the StreamingLLM framework enables large models trained with a finite attention window to generalize to infinite sequence lengths without the need for fine-tuning. This is achieved by preserving the Key and Value (KV) states of initial tokens as attention sinks, along with the most recent tokens, stabilizing attention computation and maintaining performance over extended texts. StreamingLLM excels at modeling texts up to 4 million tokens, providing a remarkable speedup of up to 22.2 times.
4. Conclusion
In conclusion, we believe that learning from the environment is the essential feature for EAI systems and thus the meta-training + GPICL approach is promising for building EAI foundation models due to its capabilities of providing better long-term adaptability and generalization. Although currently this approach is facing significant challenges in computing and memory usage, we believe that innovations such as Infini-attention and StreamingLLM will soon making this approach viable for real-time, resource-constrained environments.
References
- A Brief History of Embodied Artificial Intelligence, and its Outlook, Communications of the ACM, https://cacm.acm.org/blogcacm/a-brief-history-of-embodied-artificial-intelligence-and-its-future-outlook/
- Kirsch, L., Harrison, J., Sohl-Dickstein, J., and Metz, L., 2022. General-purpose in-context learning by meta-learning transformers. arXiv preprint arXiv:2212.04458.
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., and Agarwal, S., 2020. Language models are few-shot learners. Advances in neural information processing systems, 33, pp.1877-1901.
- Wang, F., Lin, C., Cao, Y., and Kang, Y., 2024. Benchmarking General Purpose In-Context Learning. arXiv preprint arXiv:2405.17234.
- Munkhdalai, T., Faruqui, M., and Gopal, S., 2024. Leave no context behind: Efficient infinite context transformers with infini-attention. arXiv preprint arXiv:2404.07143.
- Xiao, G., Tian, Y., Chen, B., Han, S. and Lewis, M., 2023. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453.
- Beaulieu, Shawn, et al. Learning to continually learn. ECAI 2020. IOS Press, 2020. 992-1001.
- French, Robert M. Catastrophic forgetting in connectionist networks. Trends in cognitive sciences 3.4 (1999): 128-135.
- Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” Advances in neural information processing systems 35 (2022): 27730-27744.

Fan Wang is a Distinguished Architect at Baidu working on AI systems. He holds a Master of Science degree from the engineering school at the University of Colorado at Boulder, and a Bachelor of Science degree from the University of Science and Technology of China. Fan specializes in Reinforcement Learning, Natural Language Processing, AI for Sciences, and Robotics.

Shaoshan Liu is a member of the ACM U.S. Technology Policy Committee, and a member of the U.S. National Academy of Public Administration’s Technology Leadership Panel Advisory Group. His educational background includes a Ph.D. in Computer Engineering from the University of California Irvine, and a master’s degree in public administration from Harvard Kennedy School.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment