
(This article series began here. Every article has, at the end, a link to the next one. This is the last in the series!)
We started with a succession of attempts that might have “felt right” but were in fact all wrong, each in its own way: giving the wrong answer in some cases, crashing (by trying to access an array outside of its index interval) in some cases, looping forever in some cases. Always “in some cases”, evidencing the limits of testing, which can never guarantee that it exercises all the problem cases. A correct program is one that works in all cases. The final version was correct; you were able to prove its correctness with an online tool and then to understand (I hope) what lies behind that proof.
To show how to prove such correctness properties, I have referred throughout the series to publications from the 1990s (my own Introduction to The Theory of Programming Languages), the 1980s (Jon Bentley’s Programming Pearls columns, Gries’s Science of Programming), and even the 1970s (Dijkstra’s Discipline of Programming). I noted that the essence of my argument appeared in a different form in one of Bentley’s Communications articles. What is the same and what has changed?
The core concepts have been known for a long time and remain applicable: assertion, invariant, variant and a few others, although they are much better understood today thanks to decades of theoretical work to solidify the foundation. Termination also has a more satisfactory theory.
On the practical side, however, the progress has been momentous. Considerable engineering has gone into making sure that the techniques scaled up. At the time of Bentley’s article, binary search was typical of the kind of programs that could be proved correct, and the proof had to proceed manually. Today, we can tackle much bigger programs, and use tools to perform the verification.
Choosing binary search again as an example today has the obvious advantage that everyone can understand all the details, but should not be construed as representative of the state of the art. Today’s proof systems are far more sophisticated. Entire operating systems, for example, have been mechanically (that is to say, through a software tool) proved correct. In the AutoProof case, a major achievement was the proof of correctness [1] of an entire data structure (collections) library, EiffelBase 2. In that case, the challenge was not so much size (about 8,000 source lines of code), but the complexity of both:
- The scope of the verification, involving the full range of mechanisms of a modern object-oriented programming language, with classes, inheritance (single and multiple), polymorphism, dynamic binding, generics, exception handling etc.
- The code itself, using sophisticated data structures and algorithms, involving in particular advanced pointer manipulations.
In both cases, progress has required advances on both the science and engineering sides. For example, the early work on program verification assumed a bare-bones programming language, with assignments, conditionals, loops, routines, and not much more. But real programs use many other constructs, growing ever richer as programming languages develop. To cover exception handling in AutoProof required both theoretical modeling of this construct (which appeared in [2]) and implementation work.
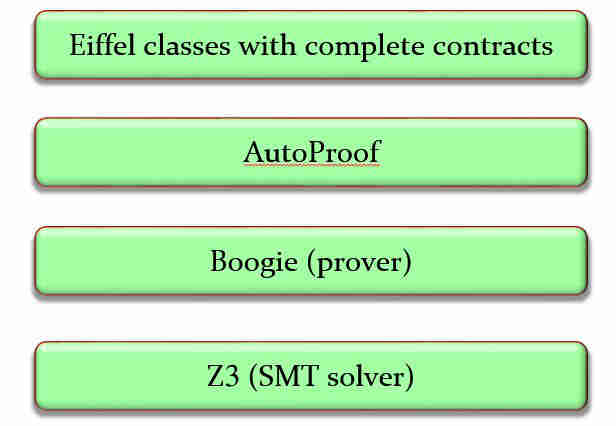
More generally, scaling up verification capabilities from the small examples of 30 years ago to the sophisticated software that can be verified today required the considerable effort of an entire community. AutoProof, for example, sits at the top of a tool stack relying on the Boogie environment from Microsoft Research, itself relying on the Z3 theorem prover. Many person-decades of work make the result possible.
Beyond the tools, the concepts are esssential. One of them, loop invariants, has been illustrated in the final version of our program. I noted in the first article the example of a well-known expert and speaker on testing who found no better way to announce that a video would not be boring than “relax, we are not going to talk about loop invariants.” Funny perhaps, but unfair. Loop invariants are one of the most beautiful concepts of computer science. Not so surprisingly, because loop invariants are the application to programming of the concept of mathematical induction. According to the great mathematician Henri Poincaré, all of mathematics rests on induction; maybe he exaggerated, maybe not, but who would think of teaching mathematics without explaining induction? Teaching programming without explaining loop invariants is no better.
Below is an illustration (if you will accept my psychedelic diagram) of what a loop is about, as a problem-solving technique. Sometimes we can get the solution directly. Sometimes we identify several steps to the solution; then we use a sequence (A ; B; C). Sometimes we can find two (or more) different ways of solving the problem in different cases; then we use a conditional (if c then A else B end). And sometimes we can only get a solution by getting closer repeatedly, not necessarily knowing in advance how many times we will have to advance towards it; then, we use a loop.
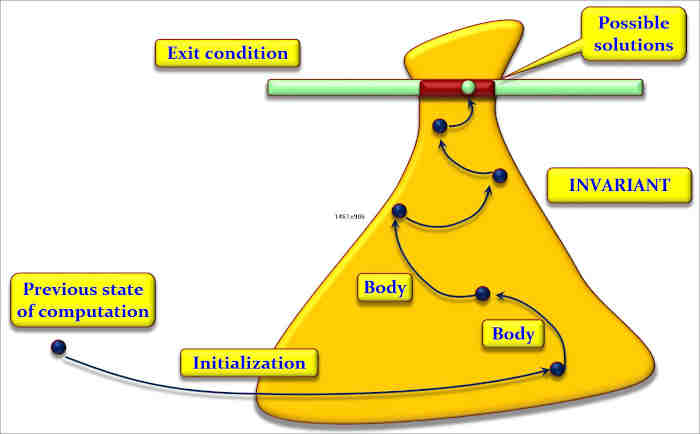
We identify an often large (i.e. very general) area where we know the solution will lie; we call that area the loop invariant. The solution or solutions (there may be more than one) will have to satisfy a certain condition; we call it the exit condition. From wherever we are, we shoot into the invariant region, using an appropriate operation; we call it the initialization. Then we execute as many times as needed (maybe zero if our first shot was lucky) an operation that gets us closer to that goal; we call it the loop body. To guarantee termination, we must have some kind of upper bound of the distance to the goal, decreasing each time discretely; we call it the loop variant.
This explanation is only an illustration, but I hope it makes the ideas intuitive. The key to a loop is its invariant. As the figure suggests, the invariant is always a generalization of the goal. For example, in binary search (and many other search algorithms, such as sequential search), our goal is to find a position where either x appears or, if it does not, we can be sure that it appears nowhere. The invariant says that we have an interval with the same properties (either x appears at a position belonging to that interval or, if it does not, it appears nowhere). It obviously includes the goal as a special case: if the interval has length 1, it defines a single position.
An invariant should be:
- Strong enough that we can devise an exit condition which in the end, combined with the invariant, gives us the goal we seek (a solution).
- Weak enough that we can devise an initialization that ensures it (by shooting into the yellow area) easily.
- Tuned so that we can devise a loop body that, from a state satifying the invariant, gets us to a new one that is closer to the goal.
In the example:
- The exit condition is simply that the interval’s length is 1. (Technically, that we have computed Result as the single interval element.) Then from the invariant and the exit condition, we get the goal we want.
- Initialization is easy, since we can just take the initial interval to be the whole index range of the array, which trivially satisfies the invariant.
- The loop body simply decreases the length of the interval (which can serve as loop variant to ensure termination). How we decrease the length depends on the search strategy; in sequential search, each iteration decreases the length by 1, correct although not fast, and binary search decreases it by about half.
The general scheme always applies. Every loop algorithm is characterized by an invariant. The invariant may be called the DNA of the algorithm.
To demonstrate the relevance of this principle, my colleagues Furia, Velder, and I published a survey paper [6] in ACM Computing Surveys describing the invariants of important algorithms in many areas of computer science, from search algorithms to sorting (all major algorithms), arithmetic (long integer addition, squaring), optimization and dynamic programming (Knapsack, Levenshtein/Edit distance), computational geometry (rotating calipers), Web (Page Rank)… I find it pleasurable and rewarding to go deeper into the basis of loop algorithms and understand their invariants; like a geologist who does not stop at admiring the mountain, but gets to understand how it came to be.
Such techniques are inevitable if we want to get our programs right, the topic of this article series. Even putting aside the Bloch average-computation overflow issue, I started with 5 program attempts, all kind of friendly-looking but wrong in different ways. I could have continued fiddling with the details, following my gut feeling to fix the flaws and running more and more tests. Such an approach can be reasonable in some cases (if you have an algorithm covering a well-known and small set of cases), but will not work for non-trivial algorithms.
Newcomers to the concept of loop invariant sometimes panic: “this is all fine, you gave me the invariants in your examples, how do I find my own invariants for my own loops?” I do not have a magic recipe (nor does anyone else), but there is no reason to be scared. Once you have understood the concept and examined enough examples (just a few of those in [6] should be enough), writing the invariant at the same time as you are devising a loop will come as a second nature to you.
As the fumbling attempts in the first few articles of this series should show, there is not much of an alternative. Try this approach. If you are reaching these final lines after reading what preceded them, allow me to thank you for your patience, and to hope that this rather long chain of reflections on verification will have brought you some new insights into the fascinating challenge of writing correct programs.
References
[1] Nadia Polikarpova, Julian Tschannen, and Carlo A. Furia: A Fully Verified Container Library, in Proceedings of 20th International Symposium on Formal Methods (FM 15), 2015. (Best paper award.)
[2] Martin Nordio, Cristiano Calcagno, Peter Müller and Bertrand Meyer: A Sound and Complete Program Logic for Eiffel, in Proceedings of TOOLS 2009 (Technology of Object-Oriented Languages and Systems), Zurich, June-July 2009, eds. M. Oriol and B. Meyer, Springer LNBIP 33, June 2009.
[3] Boogie page at MSR, see here for publications and other information.
[4] Z3 was also originally from MSR and has been open-sourced, one can get access to publications and other information from its Wikipedia page.
[5] Carlo Furia, Bertrand Meyer and Sergey Velder: Loop invariants: Analysis, Classification and Examples, in ACM Computing Surveys, vol. 46, no. 3, February 2014. Available here.
[6] Dynamic programming is a form of recursion removal, turning a recursive algorithm into an iterative one by using techniques known as “memoization” and “bottom-up computation” (Berry). In this transformation, the invariant plays a key role. I will try to write this up some day as it is a truly elegant and illuminating explanation.
Bertrand Meyer is chief technology officer of Eiffel Software (Goleta, CA), professor and provost at the Schaffhausen Institute of Technology (Switzerland), and head of the software engineering lab at Innopolis University (Russia).



Join the Discussion (0)
Become a Member or Sign In to Post a Comment