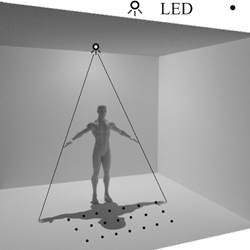
Many electronic and software applications could serve people better, if only the app knew where they were in a room and what gestures they were making. Researchers have long tried to accomplish this using video cameras with sophisticated graphical and artificial intelligence (AI) software, but Xia Zhou at Dartmouth College in Hanover, NH, has developed a simple "occlusion" technique that modulates light-emitting diodes (LEDs) in ordinary overhead solid-state lighting (SSL) fixtures and reads the postures and gestures of each person in the room using tiny (three-millimeter), inexpensive photodiodes sewn into the fabric of the floor covering.
To Thomas Little, principal investigator at the National Science Foundation’s (NSF’s) Smart Lighting Engineering Research Center at Boston University, "The work of Zhou and her team is an important contribution for enabling future immersive cognitive spaces that have the ability to react or anticipate human activity." Little said the work "demonstrates how skeleton postures can be identified from occlusion data, which will lead to future location-independent gesture recognition and control."
Many SSL systems using energy-saving LEDs in ceiling fixtures are already deployed, and the cost of switching over from incandescent or fluorescent lighting often can be quickly recouped through lower electric bills. In addition, to make SSL smart, low-cost (less than $3 each) photodiodes can be easily embedded into existing carpets, or can be woven into smart textiles that overlay or replace existing floor coverings.
The two used together—encoded LEDs and photodiode detectors—allow the occluding shadow of each room occupant to be read. Software monitors the photodiodes in the fabric of the rug at a rate of 40 frames per second (FPS), then constructs the human’s skeleton. It takes just 25 milliseconds to achieve an accuracy of 13.6 degrees mean angular error for all five body joints (backbone, left and right shoulders, left and right elbows) and a localization error of four centimeters on average (9.7 centimeters at the 95%-accuracy level). These specifications surpass Microsoft’s Kinect 3-D skeletal reconstructions, according to Zhou, using vastly simpler software. Plus, using occlusions can determine postures and gestures for each person in the room.
"This project demonstrates how modern LED lighting systems enable occupant and fine-grained gesture tracking in smart buildings. One potential application lies in rooms where camera-based tracking is undesirable due to privacy concerns. Future work on eliminating the need for floor sensors or developing more practical sensor form factors will also be valuable," said Marco Gruteser, a professor of Electrical and Computer Engineering and Computer Science at Rutgers University’s Wireless Information Network Laboratory.
How It Works
A special controller is added to overhead SSL fixtures so that each LED blinks with a different high-frequency encoding, which is invisible to the human eye, but which can be individually tracked by the photodiode detectors in the room’s carpeting in precise detail, enabling the reconstruction of people’s skeletal postures and gestures.
The secret to the simple software, compared with video processing, is that it assembles a virtual shadow map of the room that is the same whether the LEDs are on the ceiling and the photodiodes on the floor, or vice-versa. The extreme detail from each separate LED signature allows the shadow map to accurately reconstruct the data received as moving skeletons for all of the people in the room.
"We modulate the flashing rate of each LED inside the panels. The flashing rate periodically changes over time, so that each LED flashes with its own unique pattern, like a signature. Based on these patterns, light sensors are able to separate light rays from different LEDs and sense how our body blocks each light ray. These flashing rates are at high frequencies (20.8kHz to 41.5kHz) imperceptible to our eyes, so it won’t affect the illumination," said Zhou.
In the most recent experiments at the Dartmouth lab, effective results were obtained from just 20 LED arrays in the ceiling matched to 20 photodiode detectors woven into the floor covering. The costliest component in the system was a special LED controller that used a field-programmable gate array (FPGA) to provide the high-speed encoding signals that were retrofit into the otherwise standard overhead SSL system; each specialized controller costs $100 more than a conventional LED controller.
Zhou says he is now experimenting with substituting a lower-cost (about $10) wave generator for the FPGA.
Last year, the same research group introduced its LiSense system for sensing human presence and motion using shadows from visible light at the ACM International Conference on Mobile Computing and Networking (ACM MobiCom 2015); the video demonstration of the system received the conference’s "Best Video Award." StarLight , the group’s successor to LiSense, will be presented at ACM MobiCom 2016 in New York City in October.
Explained Zhou, "StarLight is better than LiSense because it dramatically reduces the number of light sensors, from over 300 to just 20. Secondly, it tracks the user even when the user is freely moving around in a room, whereas LiSense assumes a static user with known orientation. Finally, it works in a typical room with other blocking objects such as furniture, while LiSense needs an open space where the user as the only blocking object."
The new system includes both hardware (light sensors, Arduino microcontroller, and FPGA accelerator) and software "algorithms to modulate LED flashing rate, to separate light rays from different LEDs, and to search for the best-fit user skeleton posture," Zhou said.
The researchers plan to further refine the system’s design to reduce the number of overhead LED arrays needed, as well as exploring application software that utilizes the location, posture, and gestures of each person in a room.
"We plan to start with two new human interaction designs using light. One example is virtual reality [VR], where naturally tracking users’ gestures is still a challenge. Today’s VR devices commonly rely on on-body controllers or invasive cameras. Our system can sense a user’s arbitrary gestures without on-body devices and without the use of cameras," Zhou said.
"We are also interested in behavioral health monitoring—seeing whether the continuous posture data can reveal a user’s higher-level activities and behavioral patterns, which can possibly help detect early symptoms of certain diseases."
R. Colin Johnson is a Kyoto Prize Fellow who has worked as a technology journalist for two decades.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment