
Separation between content and presentation has always been one of the important design aspects of the Web. Historically, however, even though most websites were driven off structured databases, they published their content purely in HTML. Services such as Web search, price comparison, reservation engines, among others that operated on this content had access only to HTML. Applications requiring access to the structured data underlying these Web pages had to build custom extractors to convert plain HTML into structured data. These efforts were often laborious and the scrapers were fragile and error prone, breaking every time a site changed its layout.
Recent proliferation of devices with widely varying form factors has dramatically increased the number of different presentation formats that websites must target. At the same time, a number of new personal assistant applications such as Google App and Microsoft’s Cortana have started providing sites with new channels for reaching their users. Further, mature Web applications such as Web search are increasingly seeking to use the structured content, if any, to power richer and more interactive experiences. These developments have finally made it vital for both Web and application developers to be able to exchange their structured data in an interoperable fashion.
This article traces the history of efforts to enable Web-scale exchange of structured data and reports on Schema.org, a set of vocabularies based on existing standard syntax, in widespread use today by both publishers and consumers of structured data on the Web. Examples illustrate how easy it is to publish this data and some of the ways in which applications use this data to deliver value to both users and publishers of the data.
Early on it became clear that domain-independent standards for structured data would be very useful. One approach—XML—attempted to standardize the syntax. While XML was initially thought of as the future of browser-based HTML, it has found more utility for structured data, with more traditional data-interoperability scenarios.
Another approach—MCF18 (Meta Content Framework)—introduced ideas from knowledge representation (frames and semantic nets) to the Web and proposed going further by using a common data model—namely, a directed labeled graph. Its vision was to create a single graph (or knowledge base) about a wide range of entities, different parts of which would come from different sites. An early diagram of this vision is shown in Figure 1, in which information about Tori Amos is pulled together from different sites of that era into a single coherent graph.
The hope at that time was to enable many different applications to work easily with data from many different sites. Over time, the vision grew to cover all kinds of intelligent processing of data on the Web. A 2001 Scientific American article by Tim Berners-Lee et al. on the Semantic Web was probably the most ambitious and optimistic view of this program.5
Between 1997 and 2004 various standards (RDF, RDFS, and OWL) were developed for the syntax and data model. A number of vocabularies were proposed for specific verticals, some of which were widely adopted. One of these was RSS (Rich Site Summary), which allowed users to customize home pages such as Netscape’s Netcenter and Yahoo’s My Yahoo with their favorite news sources. Another was vCard/hCard (such as, IMC’s vCard standard, expressed in HTML using microformat via the CSS class attribute), which was used to exchange contact information between contact managers, email programs, and so on. These were later joined by hCalendar, a format for calendar exchange, again a microformats HTML re-expression of an existing IETF (Internet Engineering Task Force) standard, iCalendar. FOAF (Friend of a Friend) predated these efforts but saw its usage for social-network data decline as that industry matured.11 It has found a niche in the RDF (Resource Description Framework) Linked Data community as a commonly reused schema.6
In each of these cases where structured data was being published, one class of widely used application consumed it. Since the goal was to create a graph with wide coverage, well beyond narrow verticals, the challenge was to find a widely used application that had broad coverage. This application turned out to be text search.
The intense competition in Web search led companies to look beyond the ranking of results to improve search results. One technique used first by Yahoo and then Google was to augment the snippet associated with each search result with structured data from the results page.
They focused on a small number of verticals (eventually around 10, such as recipes, events, among others), each with a prescribed vocabulary, reusing existing vocabularies such as hCard and FOAF when appropriate. For each, they augmented the snippet with some structured data so as to optimize the user’s and webmaster’s experience. This approach led to much greater adoption, and soon a few hundred thousand sites were marking up their pages with structured data markup. The program had a substantial drawback, however. The vocabularies for the different verticals were completely independent, leading to substantial duplication and confusion. It was clear that extending this to hundreds or thousands of verticals/classes was impossible. To make things worse, different search engines recommended different vocabularies.
Because of the resulting confusion, most webmasters simply did not add any markup, and the markup they did add was often incorrectly formatted. This abundance of incorrect formatting required consumers of markup to build complex parsers that were able to handle improperly formed syntax and vocabulary. These complex parsers turned out to be just as brittle as the original systems used to extract structured data from HTML and thus did not result in the expected advances.
Schema.org
In 2011, the major search engines Bing, Google, and Yahoo (later joined by Yandex) created Schema.org to improve this situation. The goal was to provide a single schema across a wide range of topics that included people, places, events, products, offers, and so on. A single integrated schema covered these topics. The idea was to present webmasters with a single vocabulary. Different search engines might use the markup differently, but webmasters had to do the work only once and would reap the benefits across multiple consumers of the markup.
Schema.org was launched with 297 classes and 187 relations, which over the past five years have grown to 638 classes and 965 relations. The classes are organized into a hierarchy, where each class may have one or more super-classes (though most have only one). Relations are polymorphic in the sense they have one or more domains and one or more ranges. The class hierarchy is meant more as an organizational tool to help browse the vocabulary than as a representation of common sense, à la Cyc.
The first application to use this markup was Google’s Rich Snippets, which switched over to Schema.org vocabulary in 2011. Over the past four years, a number of different applications across many different companies have started using Schema.org vocabulary. Some of the more prominent among these include the following:
- In addition to per-link Rich Snippets, annotations in Schema.org are used as a data source for the Knowledge Graph, providing background information about well-known entities (for example, logo, contact, and social information).
- Schema.org-based structured data markup is now being used in places such as email messages.
For example, emailmessages confirming reservations (restaurant, hotel, airline, and so on), purchase receipts, have embedded Schema.org markup with details of the transaction. This approach makes it possible for email assistant tools to extract the structured data and make it available through mobile notifications, maps, and calendars. Google’s Gmail and Search products use this data to provide notifications and reminders (Figure 2). For example, a dinner booking made on Opentable.com will trigger a reminder for leaving for the restaurant, based on the location of the restaurant, the user, traffic conditions, and so on.
- Microsoft’s Cortana (for Windows 10 and Windows phones) makes use of Schema.org from email messages, as shown in Figure 3.
- Yandex uses many parts of Schema.org, including recipes, autos, reviews, organizations, services, and directories. Its earlier use of FOAF (corresponding to the popularity of the LiveJournal social network in Russia) demonstrated the need for pragmatic vocabulary extensions that support consumer-facing product features.
- Pinterest uses Schema.org to provide rich pins for recipe, movie, article, product, or place items.
- Apple’s iOS 9 (Searchlight/Siri) uses Schema.org for search features including aggregate ratings, offers, products, prices, interaction counts, organizations, images, phone numbers, and potential website search actions. Apple also uses Schema.org within RSS for news markup.
Adoption Statistics
The key measure of success is, of course, the level of adoption by webmasters. A sample of 10 billion pages from a combination of the Google index and Web Data Commons provides some key metrics. In this sample 31.3% of pages have Schema.org markup, up from 22% one year ago. On average, each page containing this markup makes references to six entities, making 26 logical assertions among them. Figure 4a lists well-known sites within some of the major verticals covered by Schema.org, showing both the wide range of topics covered and the adoption by the most popular sites in each of these topics. Figures 4b and 4c list some of the most frequently used types and relations. Extrapolating from the numbers in this sample, we estimate at least 12 million sites use Schema.org markup. The important point to note is structured data markup is now of the same order of magnitude as the Web itself.
Although this article does not present a full analysis and comparison, we should emphasize various other formats are also widespread on the Web. In particular, OGP (Open Graph Protocol) and microformat approaches can be found on approximately as many sites as Schema.org, but given their much smaller vocabularies, they appear on fewer than half as many pages and contain fewer than a quarter as many logical assertions. At this point, Schema.org is the only broad vocabulary used by more than one-quarter of the pages found in the major search indices.
A key driver of this level of adoption is the extensive support from third-party tools such as Drupal and WordPress extensions. In verticals (such as events), support from vertical-specific content-management systems (such as Bandsintown and Ticketmaster) has had a substantial impact. A similar phenomenon was observed with the adoption of RSS, where the number of RSS feeds increased dramatically as soon as tools such as Blogger started outputting RSS automatically.
The success of Schema.org is attributable in large part to the search engines and tools rallying behind it. Not every standard pushed by big companies has succeeded, however. Some of the reason for Schema.org‘s success lies with the design decisions underlying it.
Design Decisions
The driving factor in the design of Schema.org was to make it easy for webmasters to publish their data. In general, the design decisions place more of the burden on consumers of the markup. This section addresses some of the more significant design decisions.
Syntax. From the beginning, Schema.org has tried to find a balance between pragmatically accepting several syntaxes versus making a clear and simple recommendation to webmasters. Over time it became clear multiple syntaxes would be the best approach. Among these are RDFa (Resource Description Framework in Attributes) and JSON-LD (JavaScript Object Notation for Linked Data), and publishers have their own reasons for preferring one over another.
In fact, in order to deal with the complexity of RDFa 1.0, Schema.org promoted a newer syntax, Microdata that was developed as part of HTML5. Design choices for Microdata were made through rigorous usability testing on webmasters. Since then, prompted in part by Microdata, revisions to RDFa have made it less complex, particularly for publishers.
Different syntaxes are appropriate for different tools and authoring models. For example, Schema.org recently endorsed JSON-LD, where the structured data is represented as a set of JavaScript-style objects. This works well for sites that are generated using clientside JavaScript as well as in personalized email where the data structures can be significantly more verbose. There are a small number of content-management systems for events (such as concerts) that provide widgets that are embedded into other sites. JSONLD allows these embedded widgets to carry structured data in Schema.org. In contrast, Microdata and RDFa often work better for sites generated using server-side templates.
It can sometimes help to idealize this situation as a trade-off between machine-friendly and human-friendly formats, although in practice the relationship is subtler. Formats such as RDF and XML were designed primarily with machine consumption in mind, whereas microformats have a stated bias toward humans first. Schema.org is exploring the middle ground, where some machine-consumption convenience is traded for publisher usability.
Polymorphism. Many frame-based KR (knowledge representation) systems, including RDF Schema and OWL (Web Ontology Language) have a single domain and range for each relation. This, unfortunately, leads to many unintuitive classes whose only role is to be the domain or range of some relation. This also makes it much more difficult to reuse existing relations without significantly changing the class hierarchy. The decision to allow multiple domains and ranges seems to have significantly ameliorated the problem. For example, though there are various types (Events, Reservations, Offers) in Schema.org whose instance can take a startDate property, the polymorphism has allowed us to get away with not having a common supertype (such as TemporallyCommencable-Activity) in which to group these.
Entity references. Many models such as Linked Data have globally unique URIs for every entity as a core architectural principle.4 Unfortunately, coordinating entity references with other sites for the tens of thousands of entities about which a site may have information is much too difficult for most sites. Instead, Schema.org insists on unique URIs for only the very small number of terms provided by Schema.org. Publishers are encouraged to add as much extra description to each entity as possible so that consumers of the data can use this description to do entity reconciliation. While this puts a substantial additional burden on applications consuming data from multiple websites, it eases the burden on webmasters significantly. In the example shown in Figure 1, instead of requiring common URIs for the entities (for example, Tori Amos; Newton, NC; and Crucify), of which there are many hundreds of millions (with any particular site using potentially hundreds of thousands), webmasters must use standard vocabulary only for terms such as country, musician, date of birth, and so on of which there are only a few thousand (with any particular site using at most a few dozen). Schema.org does, however, also provide a same As property that can be used to associate entities with well-known pages (home pages, Wikipedia, and so on) to aid in reconciliation, but this has not found much adoption.
Incremental complexity. Often, making the representation too simplistic would make it hard to build some of the more sophisticated applications. In such cases, we start with something simple, which is easy for webmasters to implement, but has enough data to build a motivating application. Typically, once the simple applications are built and the vocabulary gets a minimal level of adoption, the application builders and webmasters demand a more expressive vocabulary—one that might have been deemed too complex had we started off with it.
At this point, it is possible to add the complexity of a more expressive vocabulary. Often this amounts to the relatively simple matter of adding a few more descriptive properties or subtypes. For example, adding new types of actions or events is a powerful way of extending Schema.org‘s expressivity. In many situations, however, closer examination reveals subtle differences in conceptualization. For example, creative works have many different frameworks for analyzing seemingly simple concepts, such as book, into typed, interrelated entities (for example, in the library world, functional requirements for bibliographic records, or FRBR); or with e-commerce offers, some systems distinguish manufacturer warranties from vendor warranties. In such situations there is rarely a right answer. The Schema.org approach is to be led by practicalities—the data fields available in the wider Web and the information requirements of applications that can motivate large-scale publication. Schema.org definitions are never changed in pursuit of the perfect model, but rather in response to feedback from publishers and consumers.
Schema.org‘s incremental complexity approach can be seen in the interplay among evolving areas of the schema. The project has tried to find a balance between two extremes: uncoordinated addition of schemas with overlapping scopes versus overly heavy coordination of all topics. As an example of an area where we have stepped back from forced coordination, both creative works (books, among others) and e-commerce (product descriptions) wrestle with the challenge of describing versions and instances of various kinds of mass-produced items. In professional bibliographies, it is important to describe items at various levels (for example, a particular author-signed copy of a particular paperback versus the work itself, or the characteristics of that edition such as publisher details). Surprisingly similar distinctions must be made in e-commerce when describing nonbibliographic items such as laser printers. Although it was intellectually appealing to seek schemas that capture a “grand theory of mass produced items and their common properties,” Schema.org instead took the pragmatic route and adopted different modeling idioms for bibliography12 and e-commerce.8
It was a pleasant surprise, by contrast, to find unexpected common ground between those same fields when it was pointed out that Schema.org‘s concept of an offer could be applied in not-for-profit fields beyond ecommerce, such as library lending. A few community-proposed pragmatic adjustments to our definitions were needed to clarify that offers are often made without expectation of payment. This is typical of our approach, which is to publish schemas early in the full knowledge they will need improving, rather than to attempt to perfect everything prior to launch. As with many aspects of Schema.org, this is also a balancing act: given strong incentives from consumers, terms can go from nothing to being used on millions of sites within a matter of months. This provides a natural corrective force to the desire to continue tweaking definitions; it is impractical (and perhaps impolite) to change schema definitions too much once they have started to gain adoption.
The driving factor in the design of Schema.org was to make it easy for webmasters to publish their data.
Cleanup. Every once in a while, we have gotten carried away and have introduced vocabulary that never gets meaningful usage. While it is easy to let such terms lie around, it is better to clean them out. Thus far, this has happened only with large vocabularies that did not have a strong motivating application.
Extensions
Given the variety of structured data underlying the Web, Schema.org can at best hope to provide the core for the most common topics. Even for a relatively common topic such as automobiles, potentially hundreds of attributes are required to capture the details of a car’s specifications as found on a manufacturer’s website. Schema.org‘s strategy has been to have a small core vocabulary for each such topic and rely on extensions to cover the tail of the specification.
From the beginning there have been two broad classes of extensions: those that are created by the Schema.org community with the goal of getting absorbed into the core, and those that are simply deployed “in the wild” without any central coordination. In 2015, the extension mechanism was enhanced to support both of these ideas better. First, the notion of hosted extensions was introduced; these are terms tightly integrated into Schema.org‘s core but treated as additional (in some sense optional) layers. Such terms still require coordination discussion with the broader community to ensure consistent naming and to identify appropriate integration points. The layering mechanism, however, is designed to allow greater decentralization to expert and specialist communities.
Second came the notion of external extensions. These are independently managed vocabularies that have been designed with particular reference to Schema.org‘s core vocabulary with the expectation of building upon, rather than duplicating, that core. External extensions may range from tiny vocabularies that are product/service-specific (for example, for a particular company’s consumption), geographically specific (for example, U.S.-Healthcare), all the way to large schemas that are on a scale similar to Schema.org.
We have benefited from Schema.org‘s cross-domain data model. It has allowed a form of loosely coupled collaboration in which topic experts can collaborate in dedicated fora (for example, sports, health, bibliography), while doing so within a predictable framework for integrating their work with other areas of Schema.org.
The more significant additions have come from external groups that have specific interests and expertise in an area. Initially, such collaborations were in a project-to-project style, but more recently they have been conducted through individual engagement via W3C’s Community Group mechanism and the collaboration platform provided by GitHub.
The earliest collaboration was with the IPTC’s rNews initiative, whose contributions led to a number of term additions (for example, NewsArticle) and improvements to support the description of news. Other early additions include healthcare-related schemas, e-commerce via the inclusion of the GoodRelations project, as well as LRMI (Learning Resources Metadata Initiative), a collaboration with Creative Commons and the Association of Educational Publishers.
The case of TV and radio markup illustrates a typical flow, as well as the evolution of our collaborative tooling.9 Schema.org began with some rough terminology for describing television content. Discussions at W3C identified several ways in which it could be improved, bringing it more closely in line with industry conventions and international terminology, as well as adding the ability to describe radio content. As became increasingly common, experts from the wider community (BBC, EBU, and others) took the lead in developing these refinements (at the time via W3C’s wikis and shared file systems), which in turn inspired efforts to improve our collaboration framework. The subsequent migration to open source tooling hosted on GitHub in 2014 has made it possible to iterate more rapidly, as can be seen from the project’s release log, which shows how the wider community’s attention to detail is being reflected in fine-grained improvements to schema details.10
Schema.org does not mandate exactly how members of the wider community should share and debate ideas—beyond a general preference for public fora and civil discussion. Some groups prefer wikis and IRC (Internet Relay Chat); others prefer Office-style document collaborative authoring, telephones, and face-to-face meetings. Ultimately, all such efforts need to funnel into the project’s public GitHub repository. A substantial number of contributors report problems or share proposals via the issue tracker. A smaller number of contributors, who wish to get involved with more of the technical details, contribute specific changes to schemas, examples, and documentation.
Related Efforts
Since 2006, the “Linked Data” slogan has served to redirect the W3C RDF community’s emphasis from Semantic Web ontology and rule languages toward open-data activism and practical data sharing. Linked data began as an informal note from Tim Berners-Lee that critiqued the (MCF-inspired) FOAF approach of using reference by description instead of “URIs everywhere:”3
“This linking system was very successful, forming a growing social network, and dominating, in 2006, the linked data available on the Web. However, the system has the snag that it does not give URIs to people, and so basic links to them cannot be made.”
Linked-data advocacy has successfully elicited significant amounts of RDF-expressed open data from a variety of public-sector and open-data sources (for example, in libraries,14 the life sciences,16 and government.15 A strong emphasis on identifier reconciliation, complex best practice rules (including advanced use of HTTP), and use of an arbitrary number of partially overlapping schemas, however, have limited the growth of linked-data practices beyond fields employing professional information managers. Linked RDF data publication practices have not been adopted in the Web at large.
Schema.org‘s approach shares a lot with the linked-data community: it uses the same underlying data model and schema language,17 and syntaxes (for example, JSON-LD and RDFa), and shares many of the same goals. Schema.org also shares the linked-data community’s skepticism toward the premature formalism (rule systems, description logics, and so on) found in much of the academic work that is carried out under the Semantic Web banner. While Schema.org also avoids assuming that such rule-based processing will be commonplace, it differs from typical linked-data guidelines in its assumption that various other kinds of cleanup, reconciliation, and post-processing will usually be needed before structured data from the Web can be exploited in applications.
Linked data aims higher and has consequently brought to the Web a much smaller number of data sources whose quality is often nevertheless very high. This opens up many opportunities for combining the two approaches—for example, professionally published linked data can often authoritatively describe the entities mentioned in Schema.org descriptions from the wider mainstream Web.
Using unconstrained combinations of identifying URIs and unconstrained combinations of independent schemas, linked data can be seen as occupying one design extreme. A trend toward Google Knowledge Graphs can be viewed at the other extreme. This terminology was introduced in 2012 by Google, which presented the idea of a Knowledge Graph as a unified graph data set that can be used in search and related applications. In popular commentary, Google’s (initially Free-base-based) Knowledge Graph is often conflated with the specifics of its visual presentation in Google’s search results—typically as a simple factual panel. The terminology is seeing some wider adoption.
The general idea builds upon common elements shared with linked data and Schema.org: a graph data model of typed entities with named properties. The Knowledge Graph approach, at least in its Google manifestation, is distinguished in particular by a strong emphasis on up-front entity reconciliation, requiring curation discipline to ensure new data is carefully integrated and linked to existing records. Schema.org‘s approach can be seen as less noisy and decentralized than linked data, but more so than Knowledge Graphs. Because of the shared underlying approach, structured data expressed as Schema.org is a natural source of information for integration into Knowledge Graphs. Google documents some ways of doing so.7
Lessons
Here are some of the most important lessons we have learned thus far, some of which might be applicable to other standards efforts on the Web. Most are completely obvious but, interestingly, have been ignored on many occasions.
- Make it easy for publishers/developers to participate. More generally, when there is an asymmetry in the number of publishers and the number of consumers, put the complexity with the smaller number. They have to be able to continue using their existing tools and workflows.
- No one reads long specifications. Most developers tend to copy and edit examples. So, the documentation is more like a set of recipes and less like a specification.
- Complexity has to be added incrementally, over time. Today, the average Web page is rather complex, with HTML, CSS, JavaScript. It started out being very simple, however, and the complexity was added mostly on an as-needed basis. Each layer of complexity in a platform/standard can be added only after adoption of more basic layers.
Conclusion
The idea of the Web infrastructure requiring structured data mechanisms to describe entities and relationships in the real world has been around for as long as the Web itself.1,2,13 The idea of describing the world using networks of typed relationships was well known even in the 1970s, and the use of logical statements about the world has a history predating computing. What is surprising is just how difficult it was for such seemingly obvious ideas to find their way into the Web as an information platform. The history of Schema.org suggests that rather than seeking directly to create “languages for intelligent agents,” addressing vastly simpler scenarios from Web search has turned out to be the best practical route toward structured data for artificial personal assistants.
Over the past four years, Schema.org has evolved in many ways, both organizationally and in terms of the actual schemas. It started with a couple of individuals who created an informal consortium of the three initial sponsor companies. In the first year, these sponsor companies made most decisions behind closed doors. It incrementally opened up, first moving most discussions to W3C public forums, and then to a model where all discussions and decision making are done in the open, with a steering committee that includes members from the sponsor companies, academia, and the W3C.
Four years after its launch, Schema.org is entering its next phase, with more of the vocabulary development taking place in a more distributed fashion. A number of extensions, for topics ranging from automobiles to product details, are already under way. In such a model, Schema.org itself is just the core, providing a unifying vocabulary and congregation forum as necessary.
The increased interest in big data makes the need for common schemas even more relevant. As data scientists are exploring the value of data-driven analysis, the need to pull together data from different sources and hence the need for shared vocabularies is increasing. We are hopeful that Schema.org will contribute to this.
Acknowledgments.
Schema.org would not be what it is today without the collaborative efforts of the teams from Google, Microsoft, Yahoo and Yandex. It would also be unrecognizable without the contributions made by members of the wider community who have come together via W3C.
![]() Related articles
Related articles
on queue.acm.org
Proving the Correctness of Nonblocking Data Structures
Mathieu Desnoyers
http://queue.acm.org/detail.cfm?id=2490873
Managing Semi-Structured Data
Daniela Florescu
http://queue.acm.org/detail.cfm?id=1103832
The Five-minute Rule: 20 Years Later and How Flash Memory Changes the Rules
Goetz Graefe
http://queue.acm.org/detail.cfm?id=1413264
Figures
 Figure 1. Example of a knowledge base sourced from multiple sites.
Figure 1. Example of a knowledge base sourced from multiple sites.
 Figure 2. Restaurant reservation email markup (microdata syntax).
Figure 2. Restaurant reservation email markup (microdata syntax).
 Figure 3. Flight reservation email markup (JSON-LD syntax) and its use in Microsoft’s Cortana.
Figure 3. Flight reservation email markup (JSON-LD syntax) and its use in Microsoft’s Cortana.
 Figure 4. (a) Major sites that have published Schema.org, (b) Most frequently used types (from public Web), (c) Most frequently used properties (as of July 2015).
Figure 4. (a) Major sites that have published Schema.org, (b) Most frequently used types (from public Web), (c) Most frequently used properties (as of July 2015).
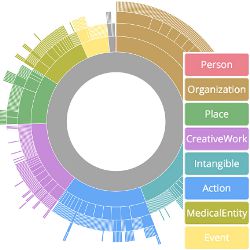
 Figure. An interactive version of the Starburst visualization (http://blog.schema.org/) allows for exploring Schema.org’s hierarchy.
Figure. An interactive version of the Starburst visualization (http://blog.schema.org/) allows for exploring Schema.org’s hierarchy.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Join the Discussion (0)
Become a Member or Sign In to Post a Comment